网页上审查元素提取一段完整网页代码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网页上审查元素提取一段完整网页代码相关的知识,希望对你有一定的参考价值。
只提取某一段代码,像第二幅图那样,自动将这一段代码重新生成一个网页;忘了怎么做的了~~~
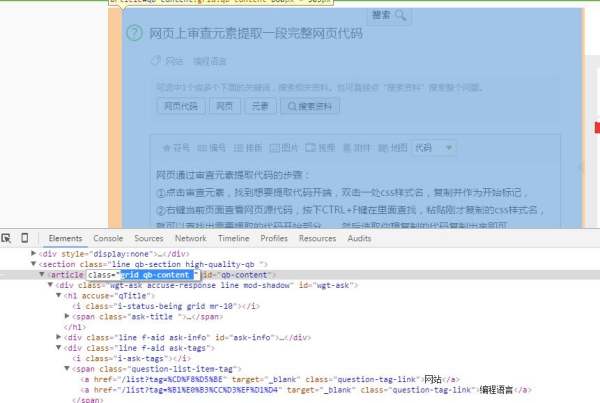
网页通过审查元素提取代码的步骤:
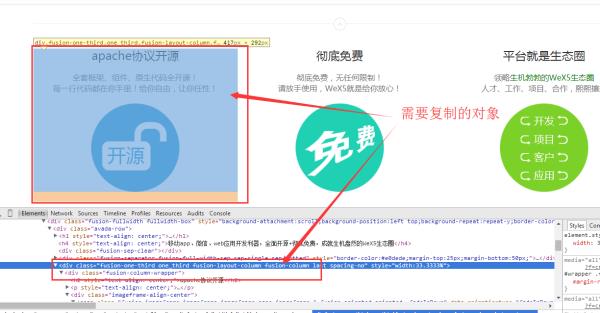
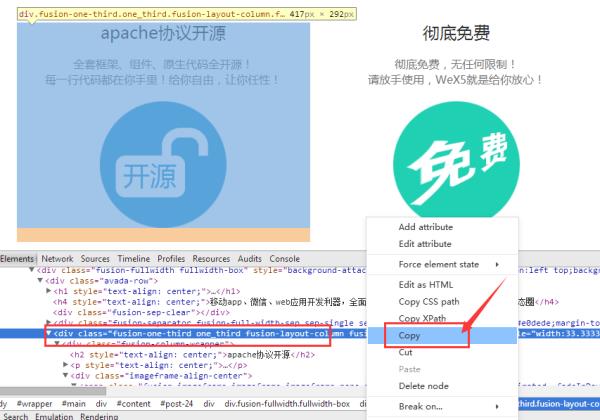
①点击审查元素,找到想要提取代码开端,双击一处css样式名,复制并作为开始标记,
②右键当前页面查看网页源代码,按下CTRL+F键在里面查找,粘贴刚才复制的css样式名,就可以查找出需要提取的代码开始部分。,然后选取你想复制的代码复制出来即可。
---------------------------------------------------------------------------------------
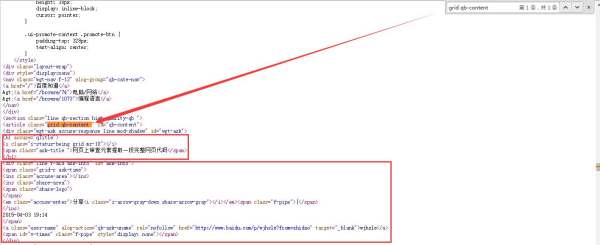
使用搜狗或360浏览器,找到要复制的对象,鼠标放在需要提取代码元素的文字或图片上,点击右键,选择审查元素,然后在下边的代码中复制需要提取的代码。
第二步:
第三步:
1在电脑桌面,双击“Google浏览器”。
2打开某一个网页,我这里以一个简单的网页为例,然后,在网页的空白位置,鼠标右击选择“查看网页源代码”,
3这时,在另一个窗口中,就显示网页代码了,
4另外,还有一种方法,就是点击浏览器右上角的竖着的三点,
5在下拉选项中,找到“更多工具”,再在级联选项中找到“开发者工具”,
6这时,你发现在网页的右侧可以查看到代码了。 参考技术C 您好,首先你要获取到你要看的某个元素的对象,然后 元素对象.读文本属性 (“outerhtml”, ) 就可以获取到代码了。
第一种:
网页内容 = 到文本(HTTP读文件("http://www.baidu.com"))
调试输出(网页内容)
第二种:
使用超文本浏览器填表方式取源码。 参考技术D 把这段HTML代码COPY出来。另存为HTML文件,但是这样没有样式与图片,需要你把对应的东西引用到新的HTML文件中。
python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述
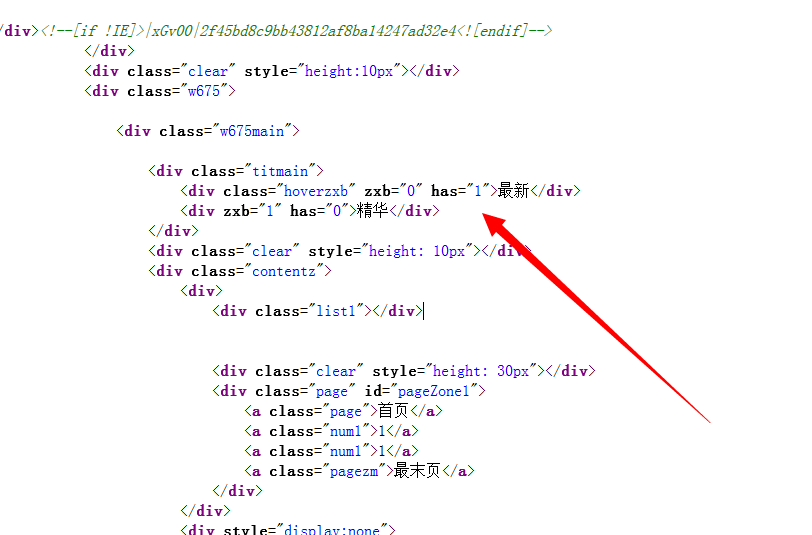
以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ 。此网页中的最新、精华下面的内容是由JavaScript动态生成的。审查网页元素与网页源码是不同。
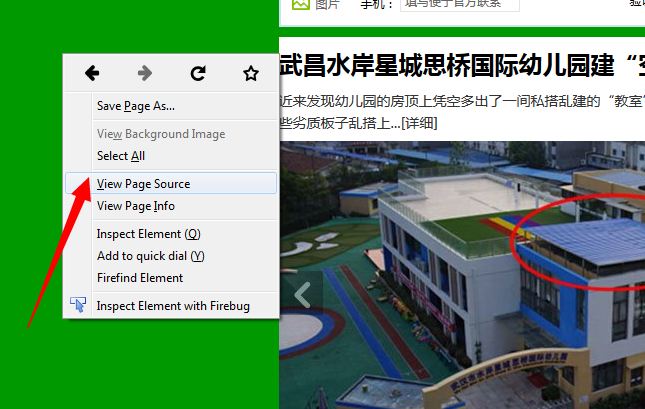
以上是网页源码
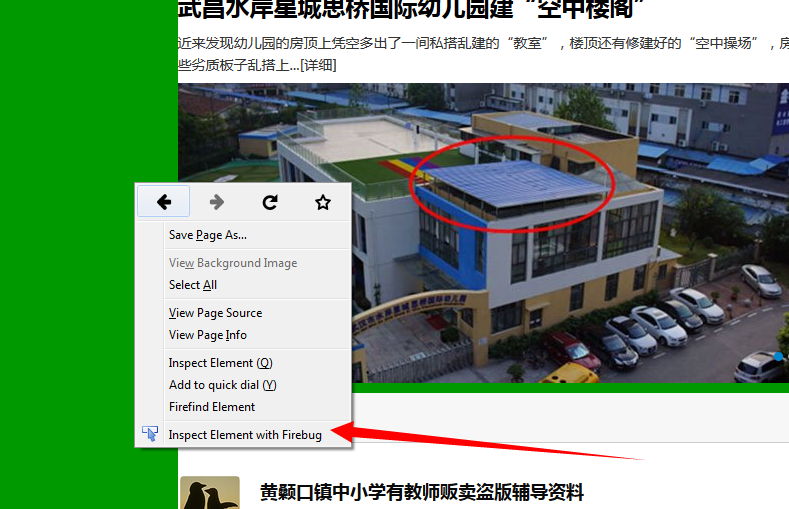
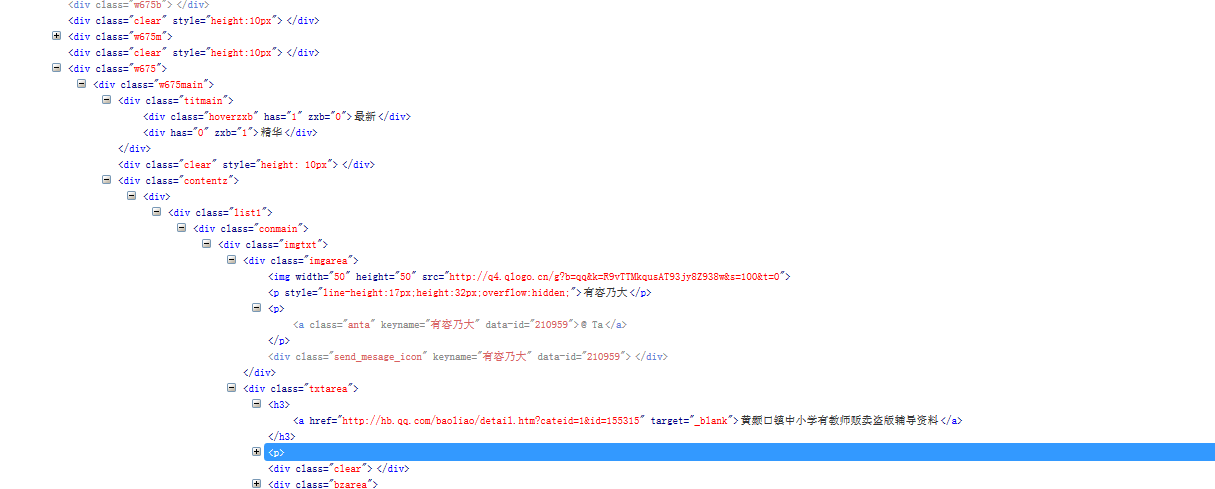
以上是审查网页元素
所以此处不能简单的使用正则表达式来获取内容。
以下是完整的获取内容并存储到数据库的思路及源码。
实现思路:
抓取实际访问的动态页面的url – 使用正则表达式获取需要的内容 – 解析内容 – 存储内容
以上部分过程文字解释:
抓取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是: http://baoliao.hb.qq.com/api/report/NewIndexReportsList/cityid/18/num/20/pageno/1?callback=jQuery183019859437816181613_1440723895018&_=1440723895472
正则表达式:
正则表达式的使用有两种思路,可以参考个人有关其简述:python实现简单爬虫以及正则表达式简述
更多的细节介绍可以参考网上资料,搜索关键词: 正则表达式 python
json:
参考网上有关json的介绍,搜索关键词: json python
存储到数据库:
参考网上的使用介绍,搜索关键词: 1,mysql 2,mysql python
源码及注释
注意:使用python的版本是 2.7
#!/usr/bin/python #指明编码 # -*- coding: UTF-8 -*- #导入python库 import urllib import urllib2 import re import MySQLdb import json #定义爬虫类 class crawl1: def getHtml(self,url=None): #代理 user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0" header={"User-Agent":user_agent} request=urllib2.Request(url,headers=header) response=urllib2.urlopen(request) html=response.read() return html def getContent(self,html,reg): content=re.findall(html, reg, re.S) return content #连接数据库 mysql def connectDB(self): host="192.168.85.21" dbName="test1" user="root" password="123456" #此处添加charset=‘utf8‘是为了在数据库中显示中文,此编码必须与数据库的编码一致 db=MySQLdb.connect(host,user,password,dbName,charset=‘utf8‘) return db cursorDB=db.cursor() return cursorDB #创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建 def creatTable(self,createTableName): createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))" DB_create=self.connectDB() cursor_create=DB_create.cursor() cursor_create.execute(createTableSql) DB_create.close() print ‘creat table ‘+createTableName+‘ successfully‘ return createTableName #数据插入表中 def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks): insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)" # insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")" DB_insert=self.connectDB() cursor_insert=DB_insert.cursor() cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks)) DB_insert.commit() DB_insert.close() print ‘inert contents to ‘+insertTable+‘ successfully‘ url="http://baoliao.hb.qq.com/api/report/NewIndexReportsList/cityid/18/num/20/pageno/1?callback=jQuery183019859437816181613_1440723895018&_=1440723895472" #正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数) reg_jason=r‘.*?jQuery.*?((.*))‘ reg_time=r‘.*?"create_time":"(.*?)"‘ reg_title=r‘.*?"title":"(.*?)".*?‘ reg_text=r‘.*?"content":"(.*?)".*?‘ reg_clicks=r‘.*?"counter_clicks":"(.*?)"‘ #实例化crawl()对象 crawl=crawl1() html=crawl.getHtml(url) html_jason=re.findall(reg_jason, html, re.S) html_need=json.loads(html_jason[0]) print len(html_need) print len(html_need[‘data‘][‘list‘]) table=crawl.creatTable(‘yh1‘) for i in range(len(html_need[‘data‘][‘list‘])): creatTime=html_need[‘data‘][‘list‘][i][‘create_time‘] title=html_need[‘data‘][‘list‘][i][‘title‘] content=html_need[‘data‘][‘list‘][i][‘content‘] clicks=html_need[‘data‘][‘list‘][i][‘counter_clicks‘] crawl.inserttable(table,creatTime,title,content,clicks)
以上是关于网页上审查元素提取一段完整网页代码的主要内容,如果未能解决你的问题,请参考以下文章