solr全文检索
Posted qq1141100952com
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了solr全文检索相关的知识,希望对你有一定的参考价值。
注:首先说明:配置文件跟java代码完全没关系的,这里给出配置文件只是为了熟悉solr
完整的文件我会放到百度网盘,自行下载
链接:https://pan.baidu.com/s/1LmjdiML0USJ00TjnZ-yHrQ
提取码:jedv
1、我们先看配置文件 db-data-config (路径:D:solr-5.5.5serversolrdemandconf)
注意:本人建议自己先单表的,先别多表查询,查询语句别用 select * ,好像不支持
<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://sql.messcat.com:3306/design?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false" user="messcat" password="messcat"/>
<document>
<entity name="demand" transformer="TemplateTransformer" query="select d.id,d.app_id,d.content,d.create_time,d.has_hot,d.hyperlink,d.listPhoto_id,d.title,d.user_id from demand d">
<field column="id" name="id"/>
<field column="user_id" name="userId"/>
<field column="app_id" name="appId"/>
<field column="content" name="content"/>
<field column="has_hot" name="hasHot"/>
<field column="create_time" name="createTime"/>
<field column="title" name="title"/>
<field column="hyperlink" name="hyperlink"/>
<entity name="demand_rel" query="SELECT file_url from file_item where id=${demand.listPhoto_id}">
<field column="file_url" name="fileUrl"/>
</entity>
<entity name="demand_tag_rel" query="SELECT tag_id from demand_tag_rel where demand_id=${demand.id}">
<entity name="demand_tag" query="SELECT id,tag_name from demand_tag where id=${demand_tag_rel.tag_id}">
<field column="tag_name" name="tagName"/>
<field column="id" name="tagId"/>
</entity>
</entity>
<entity name="user" query="select u.avatar_img,u.username from user u where u.id=${demand.user_id}">
<field column="avatar_img" name="avatarImg"/>
<field column="username" name="username"/>
</entity>
</entity>
</document>
</dataConfig>
2、managed-schema文件 (路径:D:solr-5.5.5serversolrdemandconf找到文件中标注(1)、(2)的地方做配置,其他地方不用)
<?xml version="1.0" encoding="UTF-8" ?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<!--
This is the Solr schema file. This file should be named "schema.xml" and
should be in the conf directory under the solr home
(i.e. ./solr/conf/schema.xml by default)
or located where the classloader for the Solr webapp can find it.
This example schema is the recommended starting point for users.
It should be kept correct and concise, usable out-of-the-box.
For more information, on how to customize this file, please see
http://wiki.apache.org/solr/SchemaXml
-->
<schema name="example" version="1.6">
<!-- attribute "name" is the name of this schema and is only used for display purposes.
version="x.y" is Solr‘s version number for the schema syntax and
semantics. It should not normally be changed by applications.
1.0: multiValued attribute did not exist, all fields are multiValued
by nature
1.1: multiValued attribute introduced, false by default
1.2: omitTermFreqAndPositions attribute introduced, true by default
except for text fields.
1.3: removed optional field compress feature
1.4: autoGeneratePhraseQueries attribute introduced to drive QueryParser
behavior when a single string produces multiple tokens. Defaults
to off for version >= 1.4
1.5: omitNorms defaults to true for primitive field types
(int, float, boolean, string...)
1.6: useDocValuesAsStored defaults to true.
-->
<!-- Valid attributes for fields:
name: mandatory - the name for the field
type: mandatory - the name of a field type from the
<types> fieldType section
indexed: true if this field should be indexed (searchable or sortable)
stored: true if this field should be retrievable
docValues: true if this field should have doc values. Doc values are
useful for faceting, grouping, sorting and function queries. Although not
required, doc values will make the index faster to load, more
NRT-friendly and more memory-efficient. They however come with some
limitations: they are currently only supported by StrField, UUIDField
and all Trie*Fields, and depending on the field type, they might
require the field to be single-valued, be required or have a default
value (check the documentation of the field type you‘re interested in
for more information)
multiValued: true if this field may contain multiple values per document
omitNorms: (expert) set to true to omit the norms associated with
this field (this disables length normalization and index-time
boosting for the field, and saves some memory). Only full-text
fields or fields that need an index-time boost need norms.
Norms are omitted for primitive (non-analyzed) types by default.
termVectors: [false] set to true to store the term vector for a
given field.
When using MoreLikeThis, fields used for similarity should be
stored for best performance.
termPositions: Store position information with the term vector.
This will increase storage costs.
termOffsets: Store offset information with the term vector. This
will increase storage costs.
required: The field is required. It will throw an error if the
value does not exist
default: a value that should be used if no value is specified
when adding a document.
-->
<!-- field names should consist of alphanumeric or underscore characters only and
not start with a digit. This is not currently strictly enforced,
but other field names will not have first class support from all components
and back compatibility is not guaranteed. Names with both leading and
trailing underscores (e.g. _version_) are reserved.
-->
<!-- If you remove this field, you must _also_ disable the update log in solrconfig.xml
or Solr won‘t start. _version_ and update log are required for SolrCloud
-->
<field name="_version_" type="long" indexed="true" stored="true"/>
<!-- points to the root document of a block of nested documents. Required for nested
document support, may be removed otherwise
-->
<field name="_root_" type="string" indexed="true" stored="false"/>
<!-- Only remove the "id" field if you have a very good reason to. While not strictly
required, it is highly recommended. A <uniqueKey> is present in almost all Solr
installations. See the <uniqueKey> declaration below where <uniqueKey> is set to "id".
Do NOT change the type and apply index-time analysis to the <uniqueKey> as it will likely
make routing in SolrCloud and document replacement in general fail. Limited _query_ time
analysis is possible as long as the indexing process is guaranteed to index the term
in a compatible way. Any analysis applied to the <uniqueKey> should _not_ produce multiple
tokens
-->
<!--(1):下面的是要显示的字段:数据类型要对应上,对应不上会警告,显示不出来-->
<!--index 建立索引,stored 是否存储 multiValyed 集合(类似于一个对象,里面有多个值)-->
<field name="id" type="int" indexed="true" stored="true" required="true" multiValued="false"/>
<field name="userId" type="int" indexed="true" stored="true"/>
<field name="appId" type="int" indexed="true" stored="true"/>
<field name="content" type="text_ik" indexed="true" stored="true"/>
<field name="hasHot" type="boolean" indexed="true" stored="true"/>
<field name="createTime" type="date" indexed="true" stored="true"/>
<field name="title" type="text_ik" indexed="true" stored="true"/>
<field name="hyperlink" type="text_ik" indexed="false" stored="true"/>
<field name="fileUrl" type="text_ik" indexed="false" stored="true"/>
<field name="avatarImg" type="text_ik" indexed="false" stored="true"/>
<field name="username" type="text_ik" indexed="true" stored="true"/>
<field name="tagName" type="text_ik" indexed="false" stored="true" multiValued="true"/>
<field name="tagId" type="int" indexed="true" stored="true" multiValued="true"/>
<!-- Main body of document extracted by SolrCell.
NOTE: This field is not indexed by default, since it is also copied to "text"
using copyField below. This is to save space. Use this field for returning and
highlighting document content. Use the "text" field to search the content. -->
<!-- catchall field, containing all other searchable text fields (implemented
via copyField further on in this schema -->
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
<!-- catchall text field that indexes tokens both normally and in reverse for efficient
leading wildcard queries. -->
<field name="text_rev" type="text_general_rev" indexed="true" stored="false" multiValued="true"/>
<!-- Dynamic field definitions allow using convention over configuration
for fields via the specification of patterns to match field names.
EXAMPLE: name="*_i" will match any field ending in _i (like myid_i, z_i)
RESTRICTION: the glob-like pattern in the name attribute must have
a "*" only at the start or the end. -->
<dynamicField name="*_i" type="int" indexed="true" stored="true"/>
<dynamicField name="*_is" type="int" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_ss" type="string" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_l" type="long" indexed="true" stored="true"/>
<dynamicField name="*_ls" type="long" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_t" type="text_general" indexed="true" stored="true"/>
<dynamicField name="*_txt" type="text_ik" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_en" type="text_en" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_b" type="boolean" indexed="true" stored="true"/>
<dynamicField name="*_bs" type="boolean" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_f" type="float" indexed="true" stored="true"/>
<dynamicField name="*_fs" type="float" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_d" type="double" indexed="true" stored="true"/>
<dynamicField name="*_ds" type="double" indexed="true" stored="true" multiValued="true"/>
<!-- Type used to index the lat and lon components for the "location" FieldType -->
<dynamicField name="*_coordinate" type="tdouble" indexed="true" stored="false" />
<dynamicField name="*_dt" type="date" indexed="true" stored="true"/>
<dynamicField name="*_dts" type="date" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_p" type="location" indexed="true" stored="true"/>
<!-- some trie-coded dynamic fields for faster range queries -->
<dynamicField name="*_ti" type="tint" indexed="true" stored="true"/>
<dynamicField name="*_tl" type="tlong" indexed="true" stored="true"/>
<dynamicField name="*_tf" type="tfloat" indexed="true" stored="true"/>
<dynamicField name="*_td" type="tdouble" indexed="true" stored="true"/>
<dynamicField name="*_tdt" type="tdate" indexed="true" stored="true"/>
<dynamicField name="*_c" type="currency" indexed="true" stored="true"/>
<dynamicField name="ignored_*" type="ignored" multiValued="true"/>
<dynamicField name="attr_*" type="text_general" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="random_*" type="random" />
<!-- uncomment the following to ignore any fields that don‘t already match an existing
field name or dynamic field, rather than reporting them as an error.
alternately, change the type="ignored" to some other type e.g. "text" if you want
unknown fields indexed and/or stored by default -->
<!--dynamicField name="*" type="ignored" multiValued="true" /-->
<!-- Field to use to determine and enforce document uniqueness.
Unless this field is marked with required="false", it will be a required field
-->
<uniqueKey>id</uniqueKey>
<!--(2):下面是检索域,即搜索的关键字在里面搜索:用户名,标题、内容-->
<copyField source="username" dest="text"/>
<copyField source="title" dest="text"/>
<copyField source="content" dest="text"/>
<copyField source="username" dest="text_rev"/>
<copyField source="title" dest="text_rev"/>
<copyField source="content" dest="text_rev"/>
<!-- copyField commands copy one field to another at the time a document
is added to the index. It‘s used either to index the same field differently,
or to add multiple fields to the same field for easier/faster searching. -->
<!--
<copyField source="title" dest="text"/>
<copyField source="body" dest="text"/>
-->
<!-- field type definitions. The "name" attribute is
just a label to be used by field definitions. The "class"
attribute and any other attributes determine the real
behavior of the fieldType.
Class names starting with "solr" refer to java classes in a
standard package such as org.apache.solr.analysis
-->
<!-- The StrField type is not analyzed, but indexed/stored verbatim.
It supports doc values but in that case the field needs to be
single-valued and either required or have a default value.
-->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<!-- boolean type: "true" or "false" -->
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<!-- sortMissingLast and sortMissingFirst attributes are optional attributes are
currently supported on types that are sorted internally as strings
and on numeric types.
This includes "string","boolean", and, as of 3.5 (and 4.x),
int, float, long, date, double, including the "Trie" variants.
- If sortMissingLast="true", then a sort on this field will cause documents
without the field to come after documents with the field,
regardless of the requested sort order (asc or desc).
- If sortMissingFirst="true", then a sort on this field will cause documents
without the field to come before documents with the field,
regardless of the requested sort order.
- If sortMissingLast="false" and sortMissingFirst="false" (the default),
then default lucene sorting will be used which places docs without the
field first in an ascending sort and last in a descending sort.
-->
<!--
Default numeric field types. For faster range queries, consider the tint/tfloat/tlong/tdouble types.
These fields support doc values, but they require the field to be
single-valued and either be required or have a default value.
-->
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<!--
Numeric field types that index each value at various levels of precision
to accelerate range queries when the number of values between the range
endpoints is large. See the javadoc for NumericRangeQuery for internal
implementation details.
Smaller precisionStep values (specified in bits) will lead to more tokens
indexed per value, slightly larger index size, and faster range queries.
A precisionStep of 0 disables indexing at different precision levels.
-->
<fieldType name="tint" class="solr.TrieIntField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tfloat" class="solr.TrieFloatField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tlong" class="solr.TrieLongField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tdouble" class="solr.TrieDoubleField" precisionStep="8" positionIncrementGap="0"/>
<!-- The format for this date field is of the form 1995-12-31T23:59:59Z, and
is a more restricted form of the canonical representation of dateTime
http://www.w3.org/TR/xmlschema-2/#dateTime
The trailing "Z" designates UTC time and is mandatory.
Optional fractional seconds are allowed: 1995-12-31T23:59:59.999Z
All other components are mandatory.
Expressions can also be used to denote calculations that should be
performed relative to "NOW" to determine the value, ie...
NOW/HOUR
... Round to the start of the current hour
NOW-1DAY
... Exactly 1 day prior to now
NOW/DAY+6MONTHS+3DAYS
... 6 months and 3 days in the future from the start of
the current day
Consult the TrieDateField javadocs for more information.
Note: For faster range queries, consider the tdate type
-->
<fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/>
<!-- A Trie based date field for faster date range queries and date faceting. -->
<fieldType name="tdate" class="solr.TrieDateField" precisionStep="6" positionIncrementGap="0"/>
<!--Binary data type. The data should be sent/retrieved in as Base64 encoded Strings -->
<fieldType name="binary" class="solr.BinaryField"/>
<!-- The "RandomSortField" is not used to store or search any
data. You can declare fields of this type it in your schema
to generate pseudo-random orderings of your docs for sorting
or function purposes. The ordering is generated based on the field
name and the version of the index. As long as the index version
remains unchanged, and the same field name is reused,
the ordering of the docs will be consistent.
If you want different psuedo-random orderings of documents,
for the same version of the index, use a dynamicField and
change the field name in the request.
-->
<fieldType name="random" class="solr.RandomSortField" indexed="true" />
<!-- solr.TextField allows the specification of custom text analyzers
specified as a tokenizer and a list of token filters. Different
analyzers may be specified for indexing and querying.
The optional positionIncrementGap puts space between multiple fields of
this type on the same document, with the purpose of preventing false phrase
matching across fields.
For more info on customizing your analyzer chain, please see
http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters
-->
<!-- One can also specify an existing Analyzer class that has a
default constructor via the class attribute on the analyzer element.
Example:
<fieldType name="text_greek" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.el.GreekAnalyzer"/>
</fieldType>
-->
<!-- A text field that only splits on whitespace for exact matching of words -->
<fieldType name="text_ws" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
<!-- A general text field that has reasonable, generic
cross-language defaults: it tokenizes with StandardTokenizer,
removes stop words from case-insensitive "stopwords.txt"
(empty by default), and down cases. At query time only, it
also applies synonyms. -->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- A text field with defaults appropriate for English: it
tokenizes with StandardTokenizer, removes English stop words
(lang/stopwords_en.txt), down cases, protects words from protwords.txt, and
finally applies Porter‘s stemming. The query time analyzer
also applies synonyms from synonyms.txt. -->
<fieldType name="text_en" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<!-- Case insensitive stop word removal.
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<!-- Optionally you may want to use this less aggressive stemmer instead of PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<!-- Optionally you may want to use this less aggressive stemmer instead of PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- A text field with defaults appropriate for English, plus
aggressive word-splitting and autophrase features enabled.
This field is just like text_en, except it adds
WordDelimiterFilter to enable splitting and matching of
words on case-change, alpha numeric boundaries, and
non-alphanumeric chars. This means certain compound word
cases will work, for example query "wi fi" will match
document "WiFi" or "wi-fi".
-->
<fieldType name="text_en_splitting" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<!-- Case insensitive stop word removal.
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Less flexible matching, but less false matches. Probably not ideal for product names,
but may be good for SKUs. Can insert dashes in the wrong place and still match. -->
<fieldType name="text_en_splitting_tight" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1" catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<!-- this filter can remove any duplicate tokens that appear at the same position - sometimes
possible with WordDelimiterFilter in conjuncton with stemming. -->
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
<!-- Just like text_general except it reverses the characters of
each token, to enable more efficient leading wildcard queries. -->
<fieldType name="text_general_rev" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ReversedWildcardFilterFactory" withOriginal="true"
maxPosAsterisk="3" maxPosQuestion="2" maxFractionAsterisk="0.33"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- This is an example of using the KeywordTokenizer along
With various TokenFilterFactories to produce a sortable field
that does not include some properties of the source text
-->
<fieldType name="alphaOnlySort" class="solr.TextField" sortMissingLast="true" omitNorms="true">
<analyzer>
<!-- KeywordTokenizer does no actual tokenizing, so the entire
input string is preserved as a single token
-->
<tokenizer class="solr.KeywordTokenizerFactory"/>
<!-- The LowerCase TokenFilter does what you expect, which can be
when you want your sorting to be case insensitive
-->
<filter class="solr.LowerCaseFilterFactory" />
<!-- The TrimFilter removes any leading or trailing whitespace -->
<filter class="solr.TrimFilterFactory" />
<!-- The PatternReplaceFilter gives you the flexibility to use
Java Regular expression to replace any sequence of characters
matching a pattern with an arbitrary replacement string,
which may include back references to portions of the original
string matched by the pattern.
See the Java Regular Expression documentation for more
information on pattern and replacement string syntax.
http://docs.oracle.com/javase/7/docs/api/java/util/regex/package-summary.html
-->
<filter class="solr.PatternReplaceFilterFactory"
pattern="([^a-z])" replacement="" replace="all"
/>
</analyzer>
</fieldType>
<!-- lowercases the entire field value, keeping it as a single token. -->
<fieldType name="lowercase" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
<!-- since fields of this type are by default not stored or indexed,
any data added to them will be ignored outright. -->
<fieldType name="ignored" stored="false" indexed="false" multiValued="true" class="solr.StrField" />
<!-- This point type indexes the coordinates as separate fields (subFields)
If subFieldType is defined, it references a type, and a dynamic field
definition is created matching *___<typename>. Alternately, if
subFieldSuffix is defined, that is used to create the subFields.
Example: if subFieldType="double", then the coordinates would be
indexed in fields myloc_0___double,myloc_1___double.
Example: if subFieldSuffix="_d" then the coordinates would be indexed
in fields myloc_0_d,myloc_1_d
The subFields are an implementation detail of the fieldType, and end
users normally should not need to know about them.
-->
<fieldType name="point" class="solr.PointType" dimension="2" subFieldSuffix="_d"/>
<!-- A specialized field for geospatial search. If indexed, this fieldType must not be multivalued. -->
<fieldType name="location" class="solr.LatLonType" subFieldSuffix="_coordinate"/>
<!-- An alternative geospatial field type new to Solr 4. It supports multiValued and polygon shapes.
For more information about this and other Spatial fields new to Solr 4, see:
http://wiki.apache.org/solr/SolrAdaptersForLuceneSpatial4
-->
<fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType"
geo="true" distErrPct="0.025" maxDistErr="0.001" distanceUnits="kilometers" />
<!-- Spatial rectangle (bounding box) field. It supports most spatial predicates, and has
special relevancy modes: score=overlapRatio|area|area2D (local-param to the query). DocValues is recommended for
relevancy. -->
<fieldType name="bbox" class="solr.BBoxField"
geo="true" distanceUnits="kilometers" numberType="_bbox_coord" />
<fieldType name="_bbox_coord" class="solr.TrieDoubleField" precisionStep="8" docValues="true" stored="false"/>
<!-- Money/currency field type. See http://wiki.apache.org/solr/MoneyFieldType
Parameters:
defaultCurrency: Specifies the default currency if none specified. Defaults to "USD"
precisionStep: Specifies the precisionStep for the TrieLong field used for the amount
providerClass: Lets you plug in other exchange provider backend:
solr.FileExchangeRateProvider is the default and takes one parameter:
currencyConfig: name of an xml file holding exchange rates
solr.OpenExchangeRatesOrgProvider uses rates from openexchangerates.org:
ratesFileLocation: URL or path to rates JSON file (default latest.json on the web)
refreshInterval: Number of minutes between each rates fetch (default: 1440, min: 60)
-->
<fieldType name="currency" class="solr.CurrencyField" precisionStep="8" defaultCurrency="USD" currencyConfig="currency.xml" />
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer" />
<analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer" />
</fieldType>
</schema>
3、配置好文件,windows cmd 命令进入solr5.5.5 bin目录:执行solr start 命令,启动服务器 ,另外,停止服务器命是:solr stop -all ,值得注意的是,每次改变了配置文件,都必须重启solr服务器
4、输入网址:http://localhost:8983/solr/#/
5、
6、分别执行:
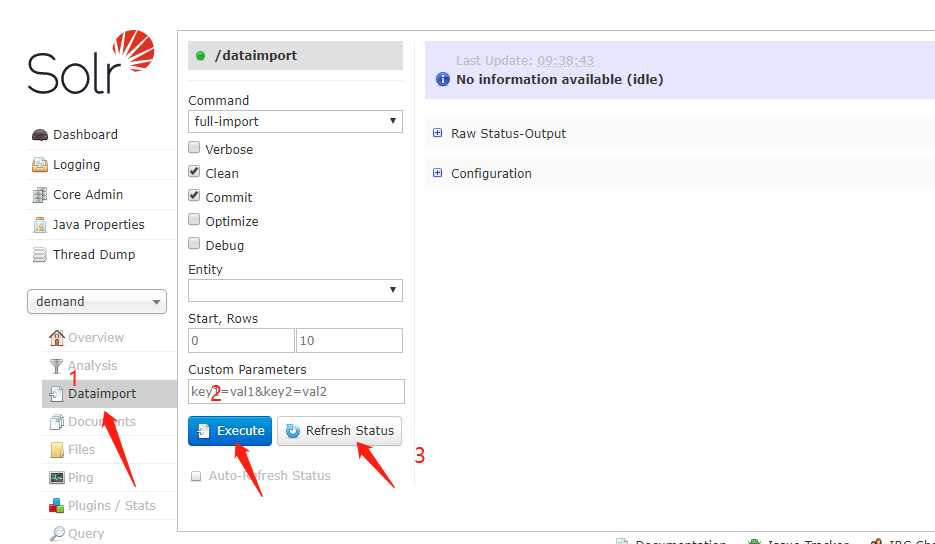
7、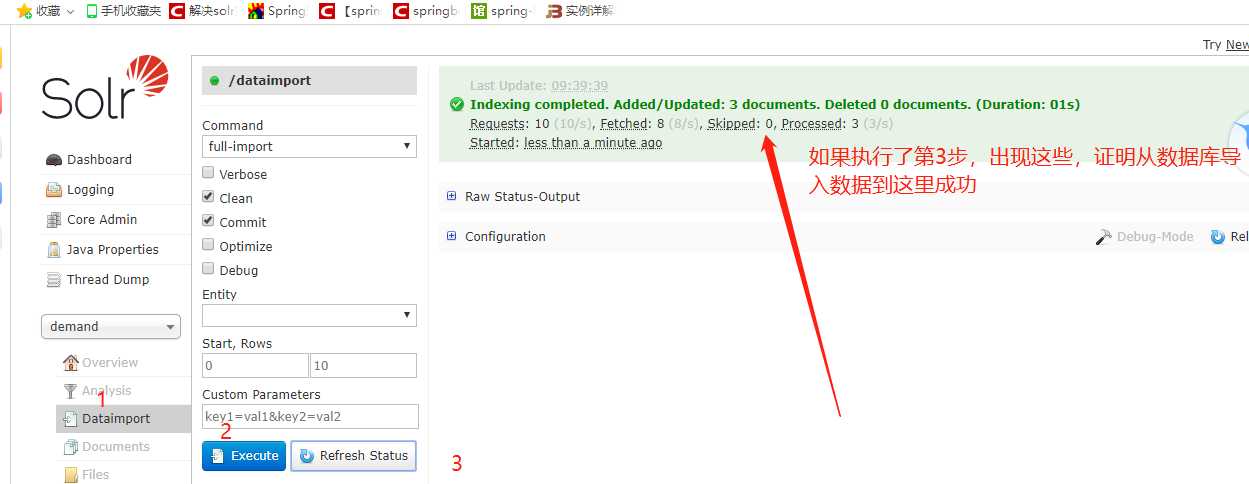
8、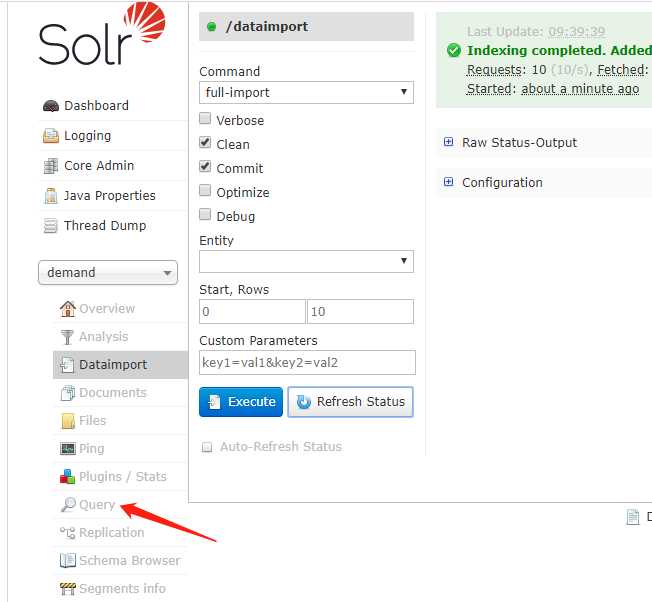
9、
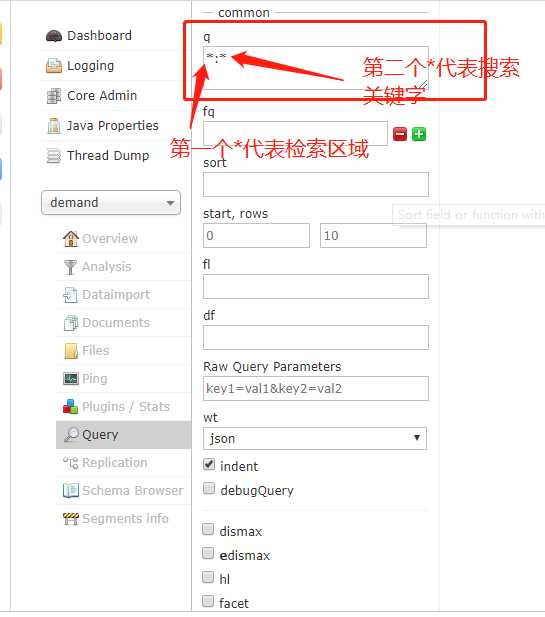
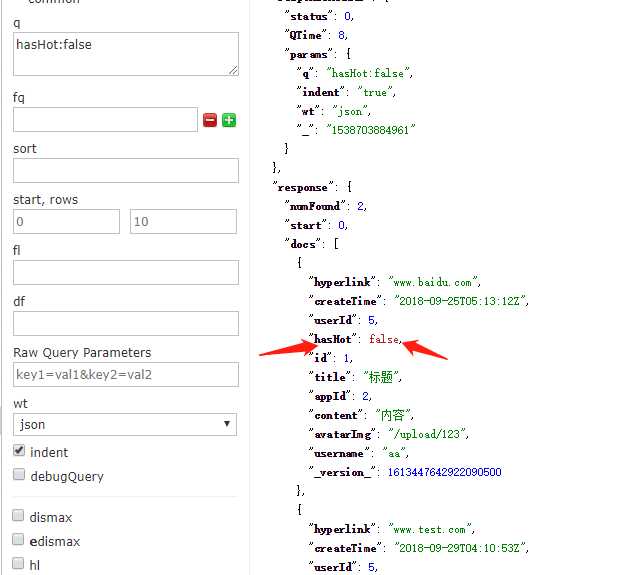
10:成功
以上是关于solr全文检索的主要内容,如果未能解决你的问题,请参考以下文章