word2vec的数学原理——词向量基础及huffuman树
Posted liguangchuang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了word2vec的数学原理——词向量基础及huffuman树相关的知识,希望对你有一定的参考价值。
一、旧版本的神经网络表示词向量
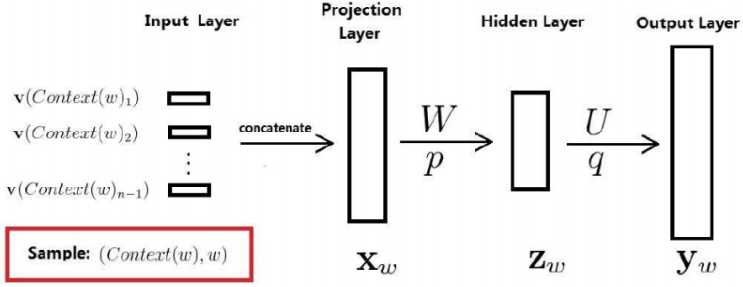
将每个词表示成$m$维的向量,用$v(w)$表示,整个网络分为4层,分别为输入层,投影层,隐藏层,输出层。
输入层:取一个大小为n的窗口表示输入,用1~(n-1)个词来预测第n个词的生成概率。
投影层:将每个词映射为m维向量,将这些词向量拼接为一个(n-1)m的长向量,作为投影层
隐藏层:隐藏层的节点根据需要可以进行调节
输出层:N维向量,表示预测为每个词的概率
前向传播的表达式为:
$z_{w}=tanh(Wx_{w}+p)$
$y_{w}=softmax(Uz_{w}+q)$
其中,输出表示由前面(n-1)各词,预测第n个词的概率,即$P(w|context(w))=y_{w}$
注意:这个网络的参数是由两部分组成的
1)词向量,每个词一开始的投影是随机的,最后由训练后确定。(这和普通的机器学习算法输入是确定的有很大区别)
2)神经网络的连接权重
二、huffman树及huffman编码
1、Huffman树的构造
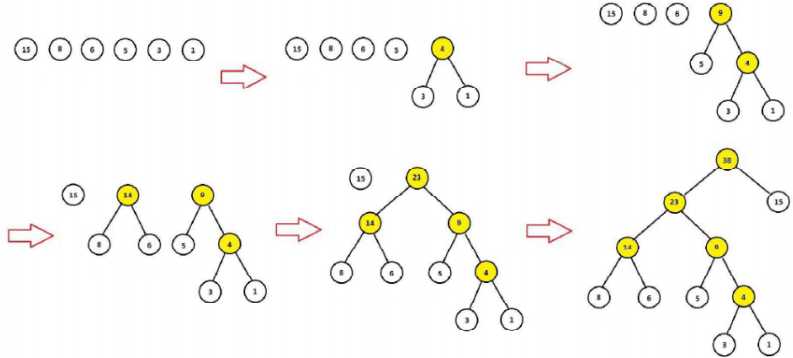
根据词典每个词作为叶子节点,词的频次作为叶子节点的权重,向上构造huffman树,具体为:
1)将词典的N个词,看成N棵树的森林
2)将“根节点权值“最小的两棵树合并成一棵新树,原来的树视为新树的左右子树,新树的“根节点权值”为左右子树的“根节点权值”之和
3)重复2),直到森林中只剩下一棵树
整个Huffman树构建完成以后,叶节点的个数为N(词典大小),非叶节点的个数为N-1
以“我”,“喜欢”,“观看”,“巴西”,“足球”,“世界杯”为例,这组词的词频为:15,8,6,5,3,1
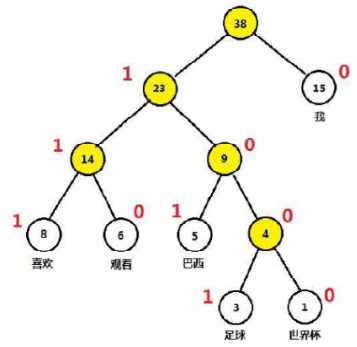
2、Huffman编码
对于一棵Huffman树,规定左子节点标记为1,右子节点标记为0,每个词的路径(根节点除外)对应的编码称为该词的Huffman编码,如:我——0,喜欢——111,观看——110,巴西——101,足球——1001,世界杯——1000
huffuman编码原先是用在数字通信领域,希望整段文本的编码长度越小越好,因此构建huffuman树,使得词频越多的字编码越短,词频越少的字编码越长。
以上是关于word2vec的数学原理——词向量基础及huffuman树的主要内容,如果未能解决你的问题,请参考以下文章