PaddlePaddle应用于百度视觉技术的工程实践
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PaddlePaddle应用于百度视觉技术的工程实践相关的知识,希望对你有一定的参考价值。
深度学习的出现,某种程度上改变了我们对计算机视觉的定义。而PaddlePaddle是百度开源的深度学习框架,它是如何支持百度视觉技术,有哪些工程实践,这篇文章将由百度视觉技术部主任研发架构师刘国翌为大家解答。
以下为刘国翌老师演讲实录
百度AI视觉能力
百度内部大规模应用计算机视觉的技术分为四个方面,第一是图像识别,包含图像分类、文字识别、人脸识别等。第二是图像检索,包含图文、相同图片、相似图片和商品图片检索。第三是视频理解,主要涉及视频分类、目标追踪、人体姿态跟踪,应用在商业、监控、安全、新零售等领域,。第四是机器人视觉,包括嵌入式视觉、SLAM、深度传感器。这是百度计算机视觉整体的划分,除机器人视觉大量应用深度学习技术,其余三个技术是从传统的机器视觉的方法逐渐过渡到现在最流行的深度学习的过程,是逐步替代的。
其中,图像识别是百度应用最广泛也是最重要的技术,包括无人车、推荐、图像配图等等。它的基础能力包含通用分类、文字识别、图像检索、细粒度识别、图像审核、视频内容分析六大能力。

图一:百度识图基础能力
? 通用分类:在实际应用中,我们需要处理上万类的通用分类以及各种各样的目标检测,因此百度内部建设自己的分类体系。
? 文字识别:和人脸识别一样,是图像识别的最主要的指令,是编码和解码的过程,方向是目标类检测。
? 图像检索:用以覆盖广泛的需求,可以搜到互联网所有包含这张图片的网页,以及跟这张图片关联的商品,包括垂类的识别,比如商品、景点、红酒、外币等等,这些无法通过一个简单分类来解决。因此需要通过图像特征学习,从而实现从图片到信息的关联。基于此,图像检索技术最关键的是图像深度学习,基于通用分类,提取分到某个中间层,定义图像不良的相应损失函数,使得相同的或者相类似的问题能得到统一的表达。另外重要的垂类,比如动植物、商标、车型等等,这种采用专用的分类技术或者分类数据,并建设一个分类的数据闭环来持续进行迭代。模型迭代需要解决三个问题,第一个问题是如何在众多的模型结构里选择最适合、最先进、最好的结构。第二个问题是上百个模型如何进行评价,这时我们需要系统的方法。换句话说,第二个问题就是如何快速经济的复现模型,希望有流程使其自动化和标准化。第三个问题:如何沉淀模型研发中大量的算法经验。因此视觉研发的实现目标是使得机器学习拥有流程化,标准化,持续快速迭代的能力。
基于PaddlePaddle,如何实现视觉模型研发
现在市场上有各种各样的不同的框架,不同框架的使用会带来模型研发、训练不同实现的问题。因此,百度内部趋向于使用同一种框架和流程,把所有的算法研发经验,包括数据处理流程都往一个方向去努力。
其中,PaddlePaddle是提供基础的平台或架构,它为我们提供了符合论文实现标准的算子的实现。同时,PaddlePaddle复现使用单卡进行训练,来保证单机单卡以及多机多卡效率互有分工。因此,基于PaddlePaddle,实现了训练的标准化和自动化以及最底层的训练框架。
PaddlePaddle训练平台中的Paddle Cloud是公司级的平台,它的数据读取可以实现从数据仓库和HDFS、AFS直读,大家通过这个平台去共享复现方案以及降低模型复现和训练的门槛。
目前,PaddlePaddle中已发布的视觉模型有:
?图像分类:image_classification
?人脸检测:face_detection
?OCR识别:ocr_recognition
?目标检测:object_detection
?图像分割:ICNet
?模型转换:image_classification/caffe2fluid
同时,还在开发中的模型如下:
?图像特征学习
?OCR 检测
?定点化训练
?视频分类
?GAN
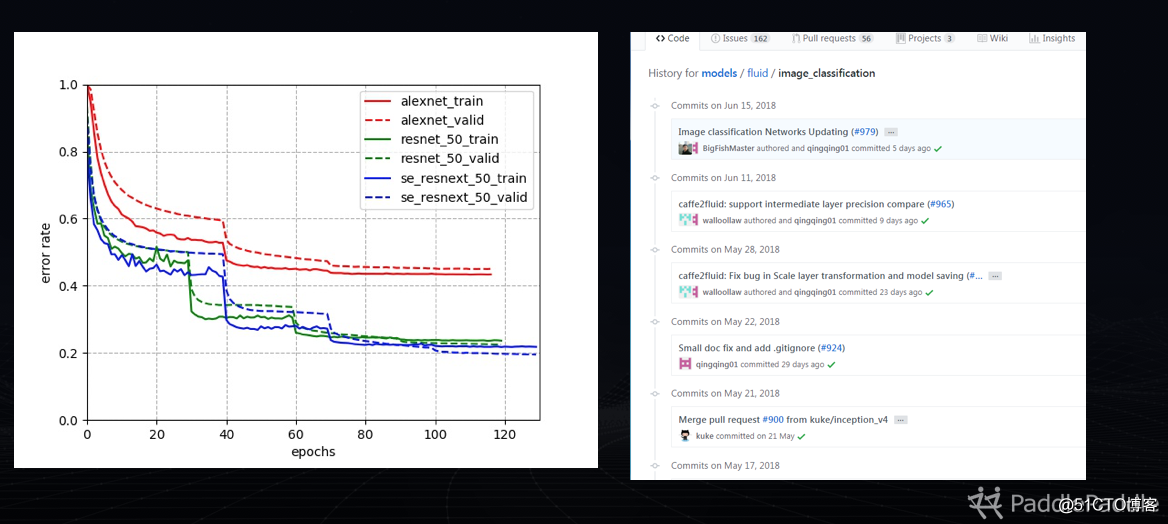
图二:图像分类模型的论文结果复现
这是我们在图像分类模型复现的结果,我们在研发过程中使用的一些数据集,通过提高社区提交代码文档和质量的要求,所有代码进行持续的集成测试,保证随着版本的迭代,使得稳定性和正确性能保持。
PaddlePaddle涉及大量的基础算法和优化算法,里面任何一部分的修改都有可能造成潜在的错误,为保证这些修改能持续得到验证,一方面在公司内部持续使用,另一方面我们会有专门的QA团队来保证持续迭代的功能,当然,我们也会有专门的团队来负责PaddlePaddle训练模型之后的预测优化。所有这些通过分工协作,视觉模型研发及相应预测的优化,更多是接近真正的使用场景。除复现大量经典的模型,我们自己也做一些自研的模型研发,如人脸检测,大规模分类以及视觉识别方面,在公开数据做到世界领先水平。未来会逐步把这些模型开放出来,跟大家一起去改进和升级这些算法。
工程示例:OCR PaddlePaddle v1 迁移到PaddlePaddle Fluid
OCR长期适用比较老的版本进行模型识别训练,期望使用最新PaddlePaddle Fluid进行研发,并统一到Paddle Cloud集群训练,应用最新的模型预测优化。因此成立PaddlePaddle vision联合项目组,模型研发和对齐并进行训练迁移和预测迁移。
模型迁移主要有四个步骤:
?完成C++端OP开发。
?完成模型网络配置,验证前向网络
?与旧版本Paddle对齐模型训练指标。
?对比多种优化方法和学习率动态调整策略。
最终试验的效果是识别率可以跟以前的版本打平,经过优化,可以有提升的空间。
模型训练主要有两个方面的提高:第一实现Fluid框架训练OCR英文识别模型。与旧版本PaddlePaddle训练出的模型相比精度相对提升1%;第二在Paddle Cloud上实现afs数据分发,实现Paddle Cloud进行单机单卡,单机多卡训练OCR识别模型。
以上这些工作和PaddlePaddle技术团队一起完成,不仅实现了PaddlePaddle的升级,也实现了自己整个训练方式的升级。
整体实现迭代之后影响面大概是1500万文本图像的识别,流量得到了升级。概括来说,我们是基于PaddlePaddle开发了一个流程:首先是基线算法采用公开数据集,实现公开的算法并在社区上提交代码和文档,以保证基线模型的正确性,以及跟其他分发的图像对比。第二是代码经过反复review,提高了代码和文档的质量,也通过社区的反馈,实现了技术的积累以及相应的问题解决。第三基于PaddlePaddle框架,实现了统一的集群训练方式,实现了标准化、自动化去做机器学习,且一些高级的训练特性,可以快速集成到框架中去。第四预测框架通过专业专门的团队,进行优化,可以达到世界领先水平。同时,独立的训练QA测试,保证训练结果随版本迭代是可复现的。
实录结束
刘国翌,百度视觉技术部主任研发架构师,百度AI技术部识图技术负责人,负责研发基于图像检索、大规模图像分类和垂类识别技术的识图系统,满足手机拍照场景下的以图搜图、以图搜信息的用户需求,组织研发并建设了百度视觉技术开放平台,开放百度的各项视觉能力。
以上是关于PaddlePaddle应用于百度视觉技术的工程实践的主要内容,如果未能解决你的问题,请参考以下文章
百度世界2017AI技术划重点:PaddlePaddle视觉技术升级
专栏 | 有趣!用计算机视觉技术与PaddlePaddle打造AI控烟项目
国际赛事“收割机”再战权威 :PaddlePaddle 助力百度大脑视觉团队获MOT榜单第一