百度PaddlePaddle深度学习平台:面向工程师,性能优先
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度PaddlePaddle深度学习平台:面向工程师,性能优先相关的知识,希望对你有一定的参考价值。
本文改编自百度技术沙龙上于洋老师的演讲,由InfoQ社区编辑尚剑整理并分享。
大家下午好,我是百度的工程师于洋。我现在给大家带来的技术分享是关于PaddlePaddle的实现和怎么用PaddlePaddle来实现神经网络。现在深度学习这个事情非常火,尤其是谷歌下一盘棋以后,大家都想做这个事情。目前我们来看,深度学习就像火箭一样,包含引擎和燃料两个部分。燃料就是所谓的大数据,也就是说我们要有足够量的数据做一些预测,引擎就是我们要有一个算的非常快的东西,可以从数据中寻找中规律。这次百度给大家带来的就是百度内部最快的一个火箭的引擎,包括这个引擎是怎么实现的。
今天的介绍主要分为以下四个部分:首先是关于我们的团队,然后介绍PaddlePaddle是什么,主要是关于PaddlePaddle具体的一些实现方式以及现在神经网络计算框架里一些比较麻烦的问题,第三部分我会用PaddlePaddle为大家做一些演示。最后是我们的联系方式。

PaddlePaddle来自于百度深度学习研究院(IDL),百度深度学习研究院可能是中国第一家以深度学习为核心的大数据人工智能研发机构,而PaddlePaddle是百度IDL最早与INF(基础架构部)和SYS(系统部)开发的深度学习平台,所以这个项目非常有历史。
我们的老大是徐伟老师,现任百度深度学习研究院“杰出科学家”,负责深度学习平台的开发以及算法的研究。我们目前的团队是比较小的,大概10人左右,主要以系统工程师为主,都是由Github办公,另外百度硅谷AI实验室资深科学家王益也加入了我们的团队。

PaddlePaddle是百度自主研发的深度学习的平台,是解决深度学习训练问题的平台。它的出发点,就是性能是第一优先,兼顾灵活易用性。PaddlePaddle本身是一个非常务实的平台,这和其他的一些平台不太一样,我们本质是一个面向工程师的平台,是一个已经解决和将要解决一些实际问题的平台,而不是一个专业做科研的平台。目前百度有超过30个主要产品都有应用到PaddlePaddle,比如搜索、杀毒、作业帮。

1. 什么是深度学习
这里首先简单介绍一下机器学习,什么是深度学习,深度学习是机器学习得一个分支,是通过多层的计算结构做的机器学习,机器学习又是人工智能的分支,所以这三者的关系是层层递进的。所谓机器学习就是不需要显示的通过编程告诉机器怎样做,而是随着数据增加机器的能力越来越强。
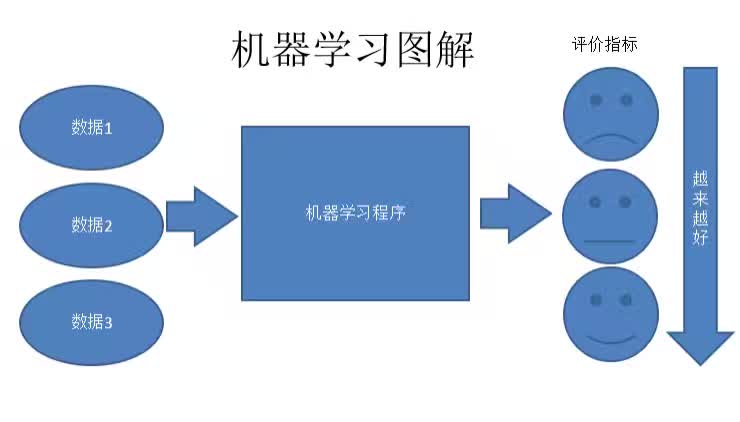
如图,我们先确定一个评价指标,机器学习就是通过数据总结规律,使这个评价指标越来越好,PaddlePaddle就是中间的机器学习程序。
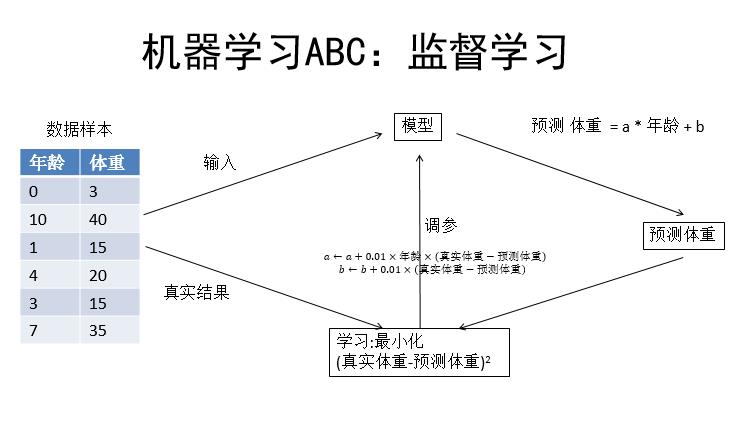
这是一个监督学习的例子,监督学习是指有一个数据样本,将数据样本输入到一个初始模型中,它会给出一个预测结果,将预测结果跟真实结果做一个对比,通过学习让真实结果和预测结果更接近,然后学习的表现就是给模型调参。比如人的年龄和体重的关系,左边的数据是年龄和体重,比如说0岁是3公斤,10岁是40公斤。首先先把样本数据输给模型,然后这个模型根据这个公式会有一个预测结果。然后根据这个预测结果和真实结果,也就是说体重之间的差,可以确定一个最小化的学习目标。这个学习目标就是让真实体重和预测体重的差最小,通过学习目标来调节模型的参数进而得到一个最优的模型,这就是一个最简单的监督学习的框架。
机器学习主要有四个要素。
第一个要素就是数据,数据的训练场景和使用场景要一致。比如上面那个例子中人的年龄和体重,数据标签中并没有性别,可能都是女性的年龄和体重,但是预测的时候或者使用的时候是不在乎性别或者只有男性,这个时候预测肯定不准,因为一般而言男性比女性稍微重一些。
第二个要素是模型结构,主要体现在对问题的理解。刚才预测年龄和体重的模型结构是一个线性的模型,就是一条直线,但是这肯定是不对的,因为人的体重肯定不会随着年龄无限的增长,所以模型结构和具体问题有关。而且模型结构还有一个问题就是输入特征是什么?刚才这个模型年龄应该是一个特征,当然还可能有别的特征,比如说收入情况,比较穷的人可能体重不会很大,比较富的人体重也不会很大,因为有时间锻炼,但是中产阶级可能比较胖。
第三个要素是优化目标函数,就是如何衡量预测和真实的差异。刚才这个例子用的优化目标就是平方差。这是比较简单的一个优化目标,但如果是分类问题,比如如果要做一个手写字符的识别,两个类别之间做差肯定是不行的,那么应该如何设计这个优化目标呢,这也是一个比较重要的问题。
第四个要素就是优化算法,也就是调参。实际上优化算法可以选择的很多,包括现在有一些自适应学习率的学习算法,都可以用PaddlePaddle来实现。
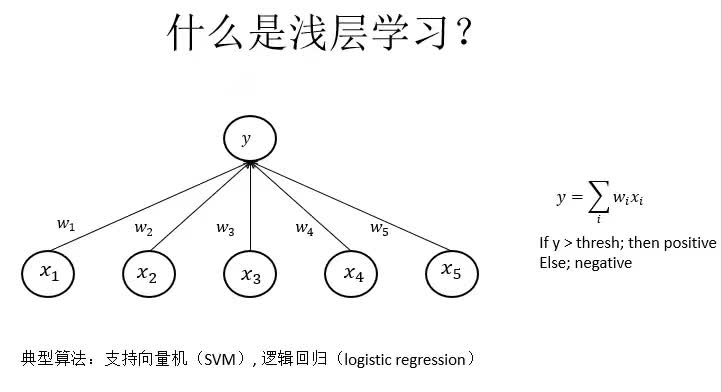
那么什么又是浅层学习呢?浅层学习的典型算法就是SVM和逻辑回归。图中x1-x5是五个特征,w1-w5是五个权重,预测值y就等于权重和对应特征的乘积和。假如说这是一个分类问题,那么y大于阈值就是正例,小于阈值就是负例,这就是一个浅层学习的基本模型。如果把这个浅层模型投影到二维情况下,那么y就可以表示成x和w的一条直线,这条直线是一个分界线,直线两边分别表示正例和负例。但是对于非线性问题,也就是线性不可分的情况下传统的浅层学习是做不了的。
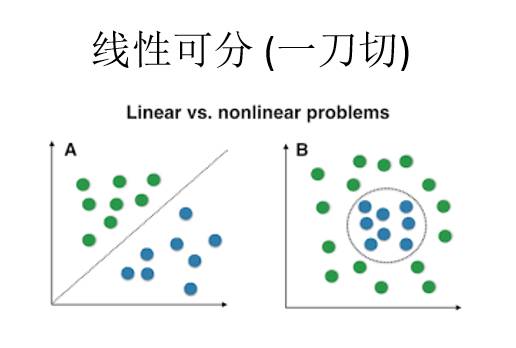
浅层学习的局限性一是依赖于特征选择,如果特征选择特别准,那么确实可能线性可分或者说一刀切。比如说人类性别分类问题,如果我们选择头发长度或者颜色,身高或者体重作为特征,这些特征不太可能一刀能够切开这个分割平面。但是如果选择DNA作为特征,显然这个问题是线性可分的。或者可以通过核函数,将原来的空间扭曲成一个线性可分的空间。这些情况的话需要对输入数据的分布有比较清楚的了解,而且要有非常好的数学背景。但是如果没有那么好的数学背景呢?这个时候就需要神经网络了,传统的统计学习就是分析数据,调整核函数,而神经网络比较简单的玩法就是看看有没有效果,如果有效果再说为什么这么做。
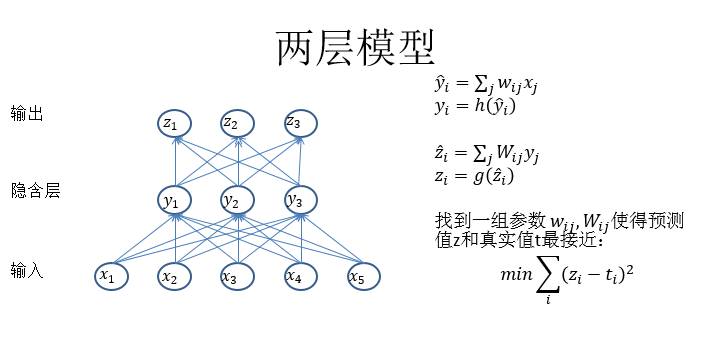
上图是一个两层模型,两层模型的话其实就是两个浅层模型的堆叠。从x到y是一个浅层学习,从y到z也是浅层学习。它的需求点就是y到z应该是线性可分,但是y是通过x学习出来的特征。所以深度学习的特点就是叠很多层,然后在中间每一层对特征进行变换,直到最后变成一个可以分类的空间。中间的这些特征都是可学的,所以就不用显式地去编程中间应该怎么做了。
深度学习有以下几个特点,一是比较灵活,网络可以连接成不同结构,可以是环路或者跳层的连接,也可以选择不同的训练目标、激活函数或者正则化。
二是可以学习高层次的抽象、分解变化因素。因为只有最后一层是做分类的,所以之前的都可以看作是特征提取的过程。
多任务学习也是神经网络非常好的一个特点,比如说现在有一个机器翻译数据,是一个英文到法文,还有一个英文到中文数据,那么这两个机器翻译任务可以在一个神经网络里面学习,只是两个不同的任务,前面英文的相关网络都是可以共享的,这也是神经网络比较灵活的一点。
四是转移学习或者迁移学习,这也是深度学习中非常常用的一点。我们可以从一个任务里得到一个神经网络然后直接应用到另外一个任务。迁移学习的好处就是对于一个新的领域,在数据量比较少的情况下,也可以得到比较好的效果。
那么到底什么样的任务适合于深度学习?其实也是目前机器学习的一个问题。主要有两点,第一点是一个明确目标。这个目标最好可以用数学表示出来。比如说优化目标可以是正确率或者某一种误差函数。
第二点就是大量的数据,或者虽然这个任务里面没有大量数据,但是另一个任务有大量数据可以用,这两个任务之间可以迁移学习。所以目前来讲机器学习是一个很有局限性的问题。这个局限性,比如如果把围棋棋盘变成三角形或者六边形的事情,而直接用围棋棋盘来训练AlphaGo的话,它是适应不了棋盘的变化的,但是人是适应的。所以目前的AI还是一个特定领域下的AI,应用场景非常窄。一个类似《西部世界》中能学习的智能体,目前还是一个需要探索的问题,我们还没有完全了解,我们也正在尝试了解。
2. PaddlePaddle整体架构
下面介绍一些PaddlePaddle的整体框架。主要介绍多机的并行架构、多GPU的并行架构、序列模型的实现以及大规模稀疏训练的实现。这些问题都是实现神经网络最复杂的问题,具体怎么实现一个layer或者全连接,卷积这些,其实各大框架实现的原理都差不多,但是这些都是比较干货的东西。
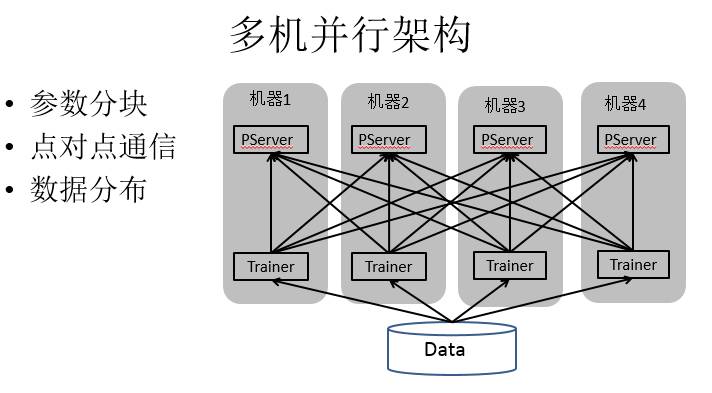
多机并行架构,图中是我们的实现方法,Paddle2013年启动的时候,当时比较流行的架构就是PServer和Trainer的架构。多机并行架构,首先是数据,数据分配到不同节点,就是简单的数据并行。灰色方框是一个机器,PServer和Trainer分布在两个独立的进程里,中间划线的部分是网络通信连接,可以看到PServer之间是没有连接的。
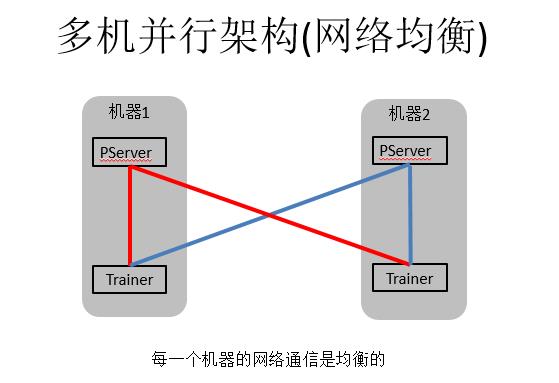
我们为什么做这么一个拓扑结构?我们的PServer逻辑上可以用在任何机器上,中间是PServer,然后许多Trainer去连接也是可以的,但是为什么每个机器都跑一个PServer,每个机器都跑一个Trainer,这样做的原因就是网络是均衡的。因为参数是被切分到不同的PServer上,这样我们网卡的出路和入路是一样,网络是可以满载的。
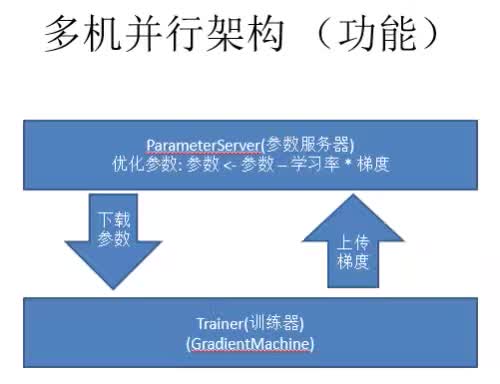
多机并行架构的大致流程就是Trainer首先计算梯度,Pserver接收上传的梯度,然后通过一个优化方法去学习参数的优化,然后Trainer在下一个mini-batch上直接从Parmeterserver上下载一个参数过来,这个算法就是一个简单的SGD。
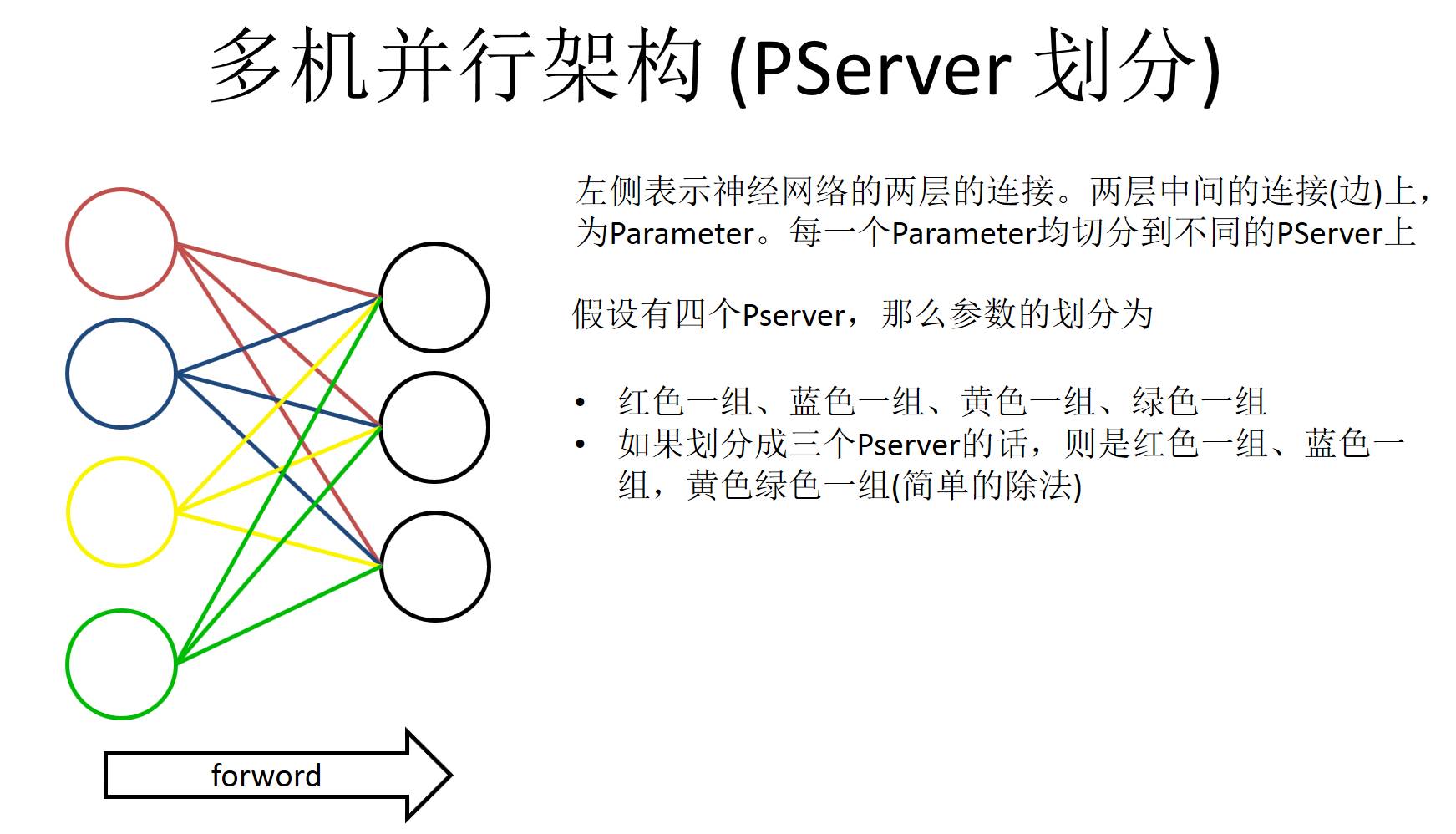
这也是PServer比较有意思的地方,左边是一个神经网络,它会把神经网络每一层参数分割开,具体怎么分割,这也是一个比较有技巧的地方。左边表示两层神经网络中间的连接,每个连接上是有一个参数的。我们要做的就是把中间这些连接参数均匀的分配到不同的PServer上。如果假设我们有四个PServer,那么参数分的话,Paddle的实现是这么做的,就是在左边靠数据那边是做切割的。红色一组蓝色一组,红黄蓝绿四组,如果是四个PServer的话就是每一组放一个PServer,如果划分为三个,最小粒度是左侧彩色的粒度。第一组是红色第二组是蓝色第三是黄色和绿色,这么做其实就可以实现一个稀疏训练的神经网络。

什么是稀疏模型的训练?首先输入数据是稀疏的,左侧(输入)到右侧(输出),左侧是稀疏的话就是左侧有一些是实心的,剩下全是虚的。所以对稀疏来讲灰色神经元就是输出是0,简单来讲就是梯度是0,通过简单的SGD可以推出权重是不更新的。所以图中只有蓝色的是有价值的,需要计算的梯度是蓝色部分。所以按右侧划分PServer参数的时候,右侧划分三组这个功能不能实现,所以一般来说是从左侧划分成一些Parmeter block给PServer。稀疏训练的话,PaddlePaddle的实现分两个部分。第一个部分就是做预取,预取就是读一遍训练数据标记好哪些神经元是有用的,哪些是稀疏的,然后从服务器上查询最新的参数。第二部分就是经典的神经网络方式,就是前馈和反向传播,先计算梯度,然后逐层返回梯度给服务器。这两个部分实现的时候是并行的,就是异步的。
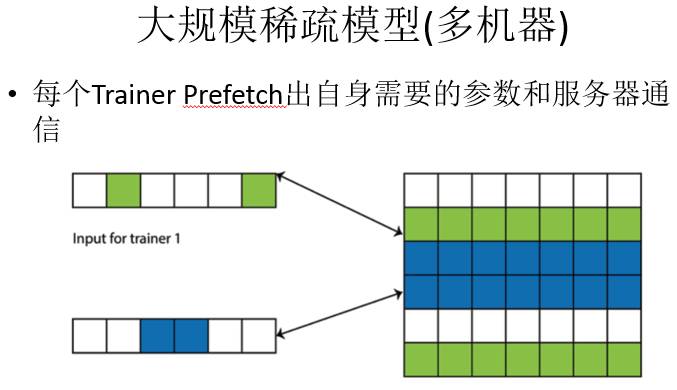
前面是单机的模型,多机的大规模稀疏模型就是每一个Trainer找自身需要的参数给服务器,所以参数不存在单点上,这个集群里有整体所有的参数。这样设计还有一个特点,我们可以训练出来一个模型,这个模型占的内存比每个节点大。比如在百度我们用的机器内存有200G,但是训练得到的网络占据的空间大于200G。所以我们把参数所有的操作都放在PServer上,Trainer没有任何参数,每次都是从server上直接获取。
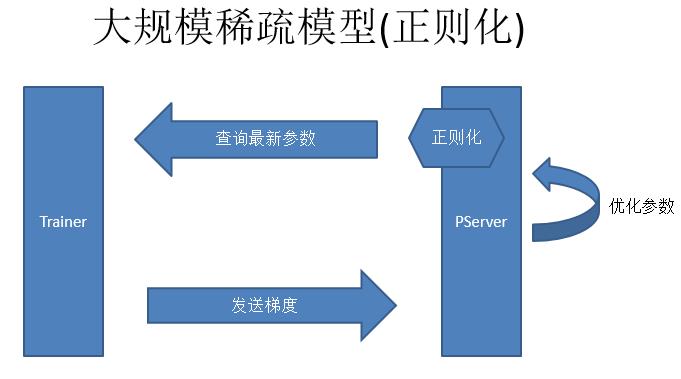
正则化是大规模稀疏模型的另一个问题。简单的SGD在梯度是0的时候,是不需要更新参数,但是如果加上正则化就不一样,比如L2正则化的时候,就要求参数的L2范数持续减小。稀疏模型正则化,第一点是从PServer上查参数,第二点Trainer去计算梯度然后发送给PServer,第三点是做参数优化,这个优化是不包括正则化的优化。我们在查询参数之前去做正则化,用这个参数的时候正则化再开始做。正则化是每一轮都要做,要持续的让这个参数越来越好。因为是一个稀疏模型,不一定每一次都会访问这个参数,所以我们就会记录下来访问的次数,然后最后一次访问的时候把之前没有做的正则化补齐,这个就是大规模稀疏模型正则化的做法。
当然这是2013年的趋势,目前有一个流行趋势就是不需要PServer这个架构,而是完全P2P的更新。P2P的更新一般是用一个环形网络,这个框架主要针对语言或者图像任务。比如说百度的语音识别就是基于这个框架。这个框架的多机通信算法的描述比较简单,这里有三个节点,节点NodeA就是机器A,然后机器B、机器C,对于一个参数,首先在每个节点上切分成三份,我们要做的就是求和以后做一个优化。它的具体算法就是,比如说NodeA的时候,从A0发给B0,NodeB的时候直接从B1发给C1这样环形走,这是第一步。
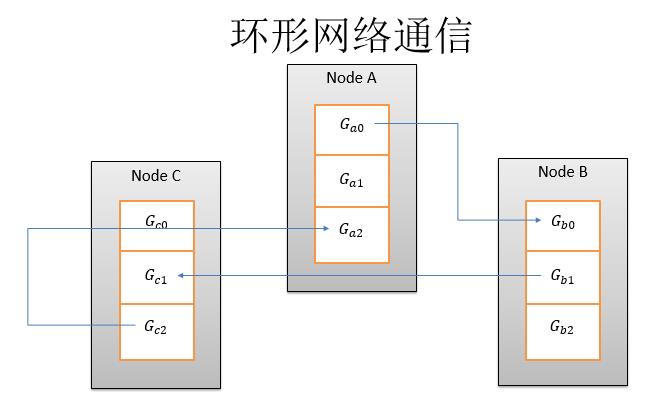
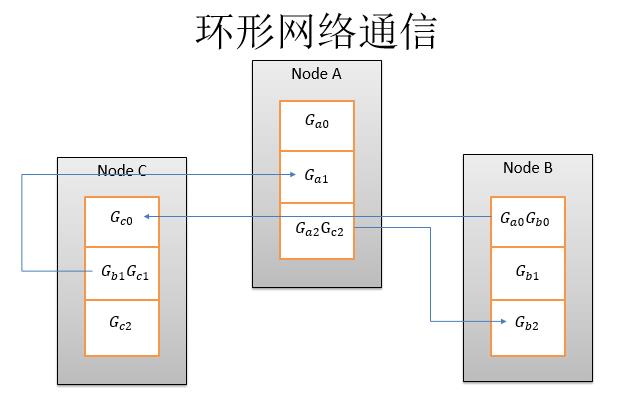
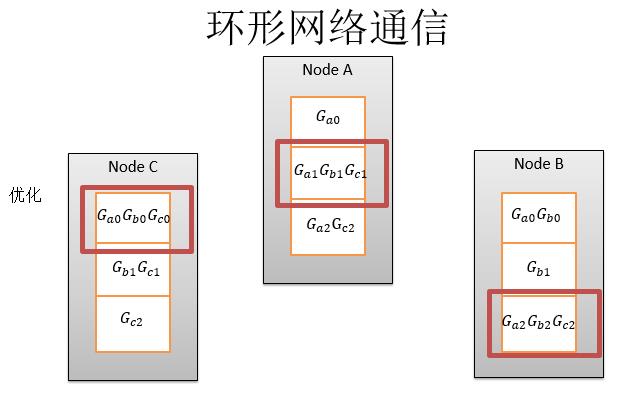
第二步求完和,然后再把求和的结果发给下一步。第二步这些和已经全了,全了以后画方框这一点,就是这个梯度已经和全部同步完毕,那么我可以优化到参数上,然后变成了theta1、theta2、theta3然后环形的发送回去。
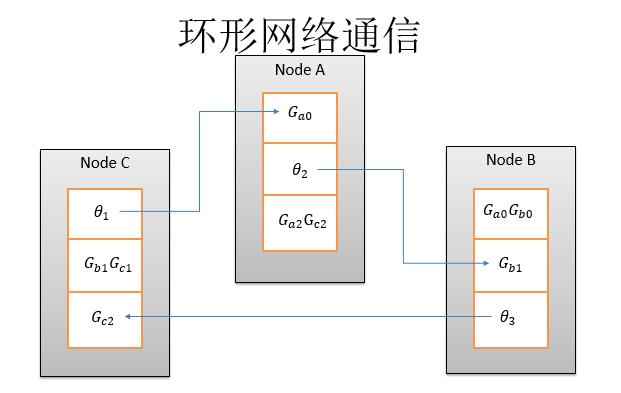
环形网络通信的优势在于,首先实现同步算法的时候比较简单,和Pserver相比少了一部分通讯,而且同步力度非常大,到最后把参数算出来之后再做同步,它中间每一个机器都可以随便分发。但是它不能实现异步SGD,不过异步SGD通常收敛效果不是最佳的。所以不实现异步SGD这一点不是非常重要。第二缺点在于,实现稀疏更新的情况下,网络的开销变得越来越大。因为它新的节点会累加之前节点的信息,传递给下一个节点。因为是稀疏越累加越多,最后一个节点会有一个全量的数据。
PaddlePaddle的单机多GPU通信是环形通信,这比别的计算框架要快的一点,比如caffe的算法快一倍到两倍。单机多GPU的时候是环形通信,那为什么是环形呢?因为GPU是一个SPMD((Single Program/Multiple Data))的设备,一次会处理很多数据,但是处理很多数据和处理很少的数据对于GPU来讲是一样,GPU一般训练时都是稠密的数据。但是单机多GPU一般也不会做异步SGD,这与多GPU通信和网络多节点通信不一样,不需要把参数聚合到CPU,而是用一个逻辑的对外参数即可。
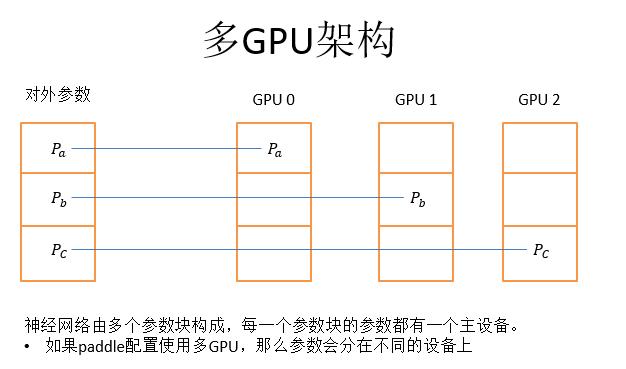
而多GPU架构,如上图,左侧是对外参数,是可以被PaddlePaddle其他的程序访问,然后这一个对外参数分成三个参数块,把三个参数块分别放到三个不同的主卡上。
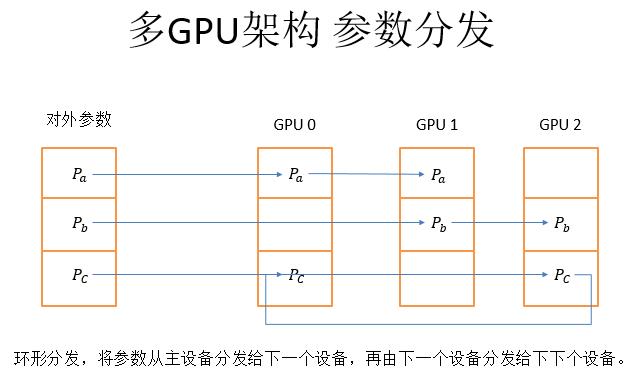
多GPU架构的参数分发采用的是从主设备分发给下一个设备,再由下一个设备分发给下下个设备,依次往最远端分发的方式。
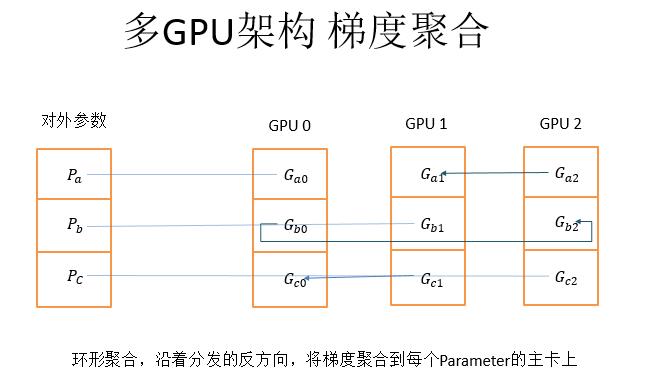
而梯度聚合就是沿着分发的反方向,将计算得到的梯度聚合到每个参数的主卡上。这样做的好处就是只利用显卡之间的P2P通信,没有经过CPU和内存。
PaddlePaddle还实现了对一些序列模型的训练,序列模型是指训练数据是一个序列(sequence),具有一定的顺序(order)的概念。就是序列模型的特征是a vector of features而不是a set of features,比较常见的序列模型任务就是自然语言处理或者说音视频的处理。
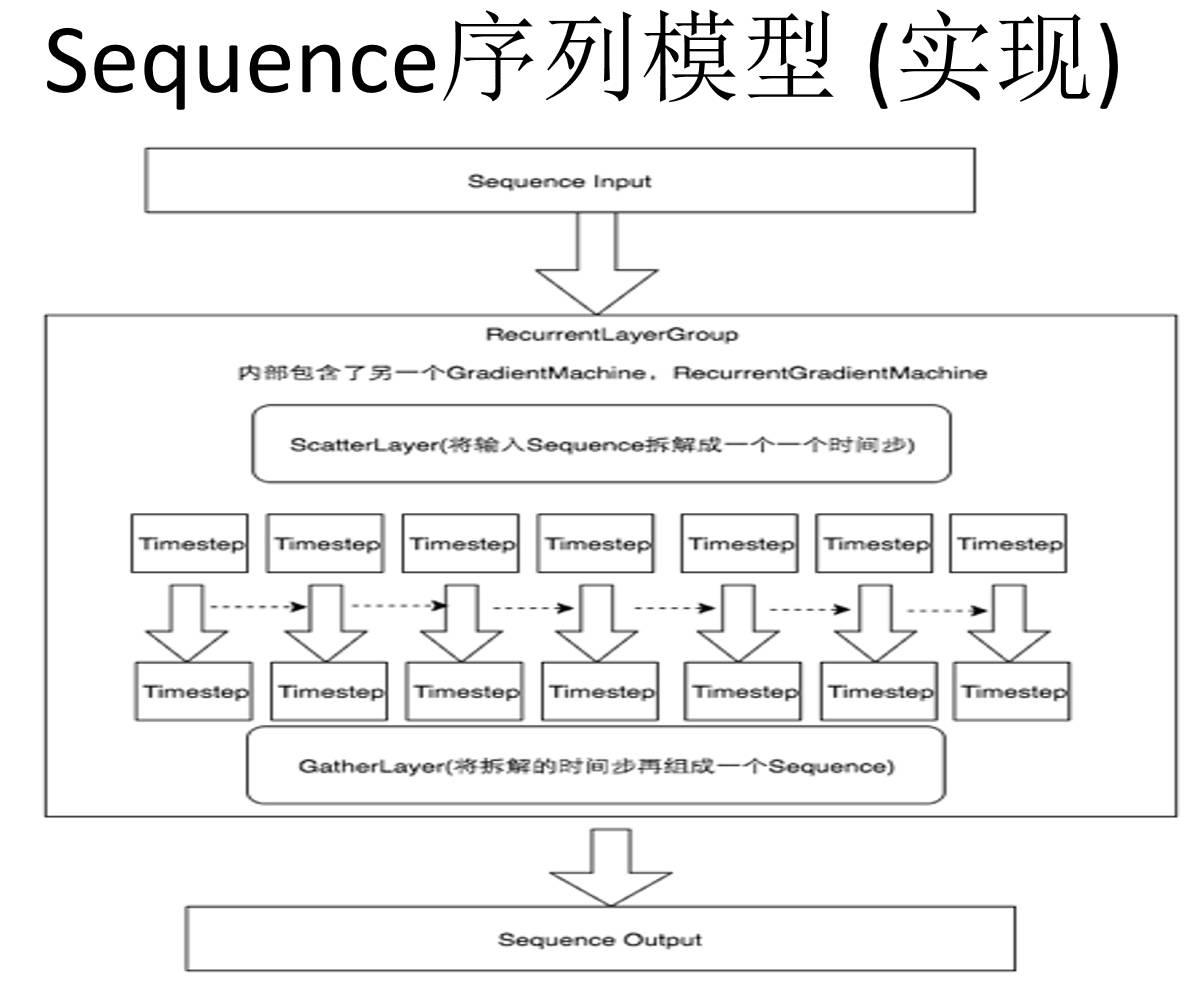
PaddlePaddle中对于序列模型的处理也和其他的神经网络框架不一样。但是这也充分说明我们的框架是比较务实的。具体实现是这样的,在其他层来看,sequence都是一整条输入,但是对于某些特定的层,PaddlePaddle会将输入序列打散成不同的时间步,然后在这个层内部对每个时间步进行处理,当然这个处理都是自定义的。这个时间部处理完了以后我们再用一个GatherLayer将拆解的时间步重新组合成一个sequence再输出出来,就是一个打散再聚合的过程。
每个时间步之间是有通信的,比如做语音识别前一秒的语音和后一秒的语音有一定关系,这种通信Paddle是采用一种叫Memory的机制,就是在特殊的RNN的层里,定义一种Memory,上一个时间步的神经网络,可以将需要记住的东西放到Memory中,下一个时间步可以引用这个Memory,这样就实现了Memory的共享。Paddle是支持任意复杂的RNN结构,你知道的任何的RNN结构都是支持的,当然也可以自己搭配不同的结构。
Sepuence序列模型最难的一点在于batch计算,为什么要做batch计算呢?因为矩阵维度要足够大,才能充分发挥GPU的能力,才能加速运算 (SPMD)。但是Sepuence序列模型有一个问题就是输入是参差不齐的。那么怎么对这种输入进行计算?
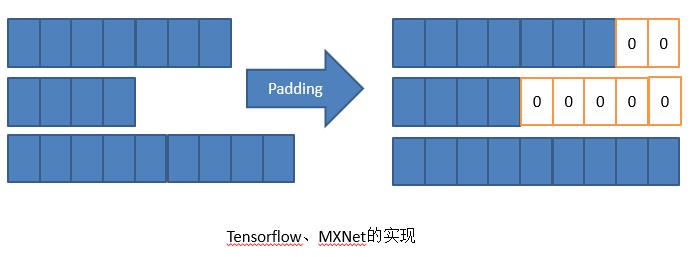
不同的网络框架的做法不一样,Tensorflow和MXNet会做Padding,将三个Sepuence全部Pading一样长,不够的后面补0,然后再依次计算。当然Padding非常有技巧,比如把Sepuence和相近长度的Padding起来,使补0补得最少。但是本质上这种实现还是一个需要多计算的方法。
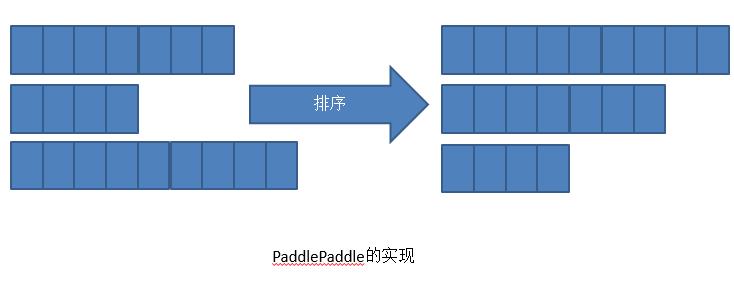
而PaddlePaddle的实现是做一个排序,不是物理排序,而是一个逻辑排序。逻辑上排序成右侧的形式我们依次去计算。但是计算到一定程度以后,空间可能会变少。这是PaddlePaddle的实现,这个优点就是没有Padding不会增加计算量,但是缺点就是排序需要时间。这两个实现并不能说谁比谁,因为是这个问题终究没有非常好的解决,我们目前还在探索这个问题。
3. PaddlePaddle实现时的一些思考
目前主流的神经网络框架可以分为两种,一种是基于OP(操作)的,就是从矩阵乘法配起,一步一步对应一个一个数学运算,配各种连接,然后大家可以直接根据数学公式把梯度推出来。另一种是基于层的,每一层,把一堆数学公式封装好,只提供一个最简单的概念。基于OP(比如TensorFlow)的框架的优势是更灵活,因为它可以让研究人员构造新的东西。而基于Layer(caffe)的框架会让细节暴露的更少,会让优化变得更容易,计算更快一些。
那么PaddlePaddle是基于OP还是基于layer?PaddlePaddle是一个混合的系统,首先PaddlePaddle支持大部分Layer,但是也支持从OP开始配网络(比如矩阵乘法,加法,激活等等)。对于一些成型的layer,比如LSTM,我们使用C++对其进行重新优化。我们刚开始做的时候LSTM还没有一个专门的Layer,是从OP开始配,但是配完以后发现LSTM使用的非常广泛,所以就将其作为一个Layer重新在C++实现一遍。
所以在PaddlePaddle中我们把这些常用的OP的组合再优化成一个Layer,这样做的好处就是可以兼顾灵活性,但是最重要的还是性能。这样做的好处就是PaddlePaddle的LSTM是业界最快的,而且是从原理上就比其他框架快。
还有一个实现思考的话就是,PaddlePaddle的多机通信到底是基于MPI 还是 Spark 还是 k8s + Docker?首先PaddlePaddle的任务比较简单,因为我们不是一个网站,或者说要求很高的东西,如果运行几周挂一次还是可以接受的。比如说每个小时存一个数据点,再恢复的话并不是耗费非常大的事情。所以PaddlePaddle的网络任务需求相对简单,我们可以自己做,并不依赖于任何网络框架。
第二点就是PaddlePaddle的网络是需要高性能的网络,从头手写网络库更方便性能调优,并且RDMA可以更好的支持。同理,PaddlePaddle底层不依赖任何GPU通信框架。当然,我们未来会提供一些配置脚本,比如说在多机上更容易实现的配置脚本。
当然这些都是PaddlePaddle实现上的一些东西,目前还有一些更新的东西在做,等做完了以后再和大家分享。
神经网络可以做什么?下面用PaddlePaddle来做一些有趣的事情为大家演示一下。
1. 手写识别

首先是手写识别的例子,代码大家可以从github上直接下载。数据集是图中右侧的手写字符数据集,每一个数据都是256色的灰度图,分辨率是28×28。
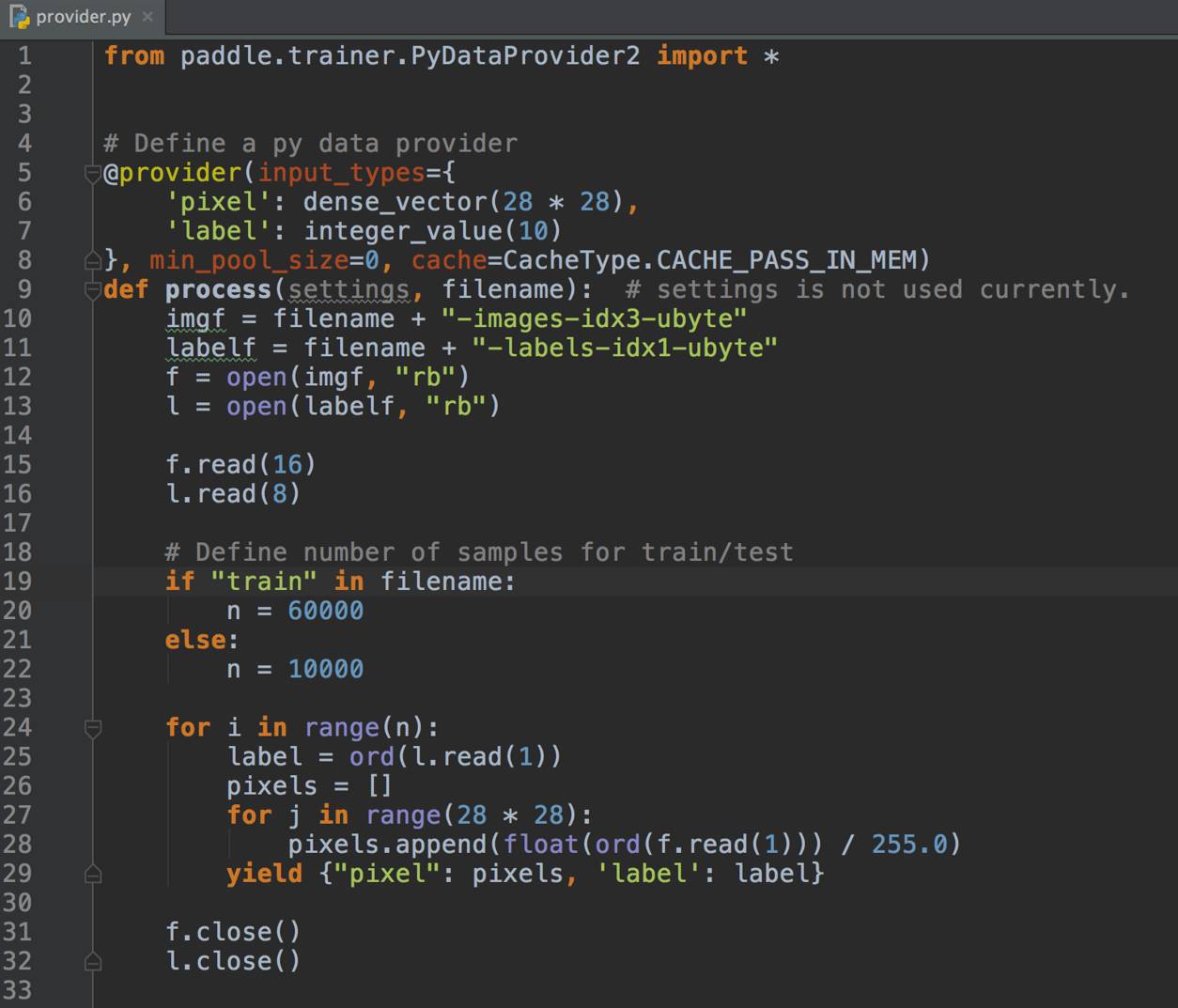
实际上,PaddlePaddle对用户的接口是Python,不需要很深刻的编程基础,这里展示一下PaddlePaddle数据读取的代码。数据读取的话首先有两个东西,pixel和label,PaddlePaddle的数据读取只要考虑每一条数据就可以了。
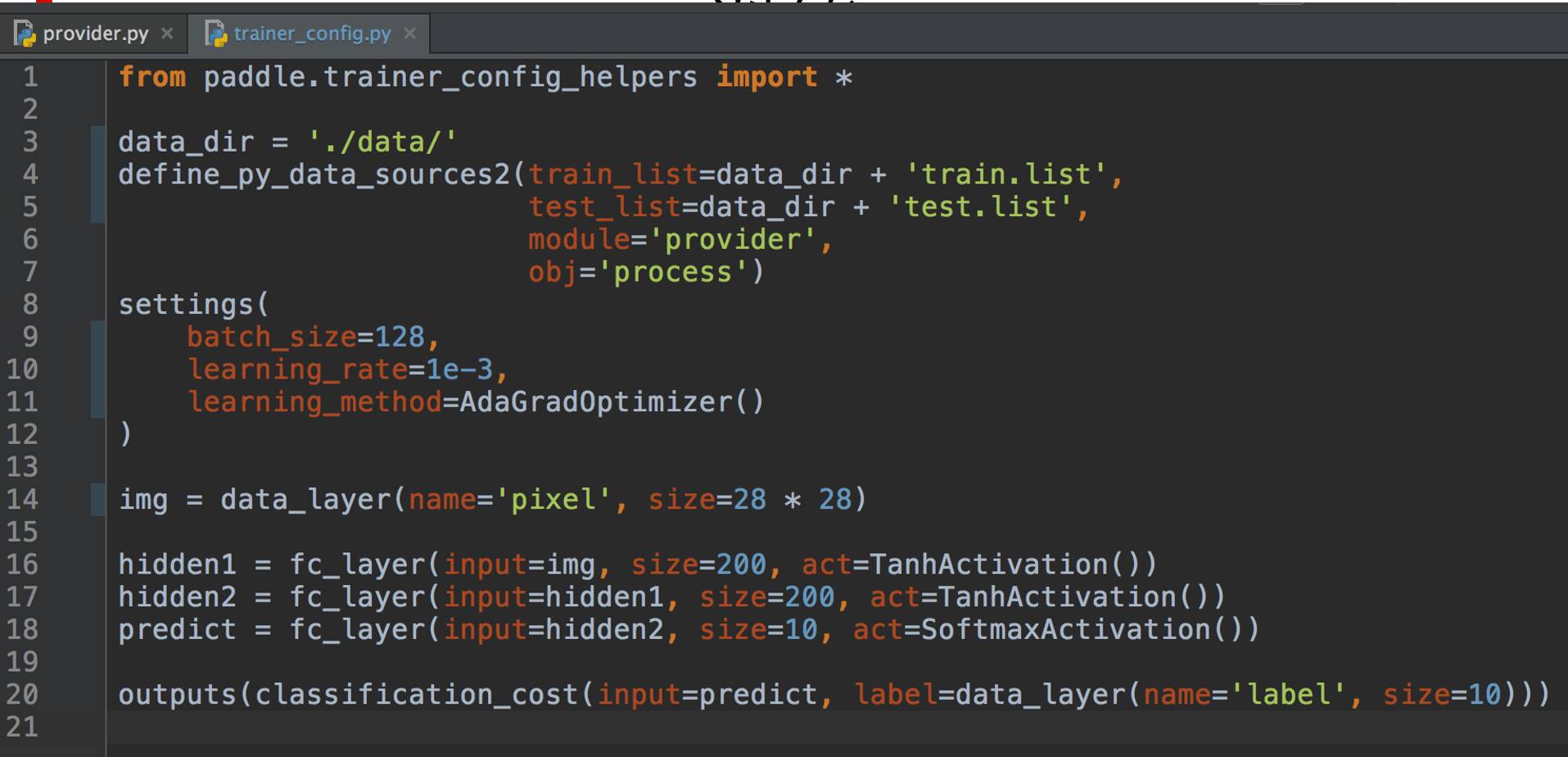
网络配置的话其实比较简单。首先数据从哪儿读,从两个文件列表里读,然后文件名,函数名。这个就是一个简单的网络,这个叠的层数多一些。
2. 情感分类

情感分类的demo也是在PaddlePaddle的主版本库里,所谓的情感分类就是判断情感趋向,比如显示器很棒就是一个好评,用了两个月以后显示器碎了,那就是差评。但是这个数据集不太好展示,因为这是一个英文的数据集,我们其实很想做一个开放的中文数据来做演示,因为中文比较有意思。
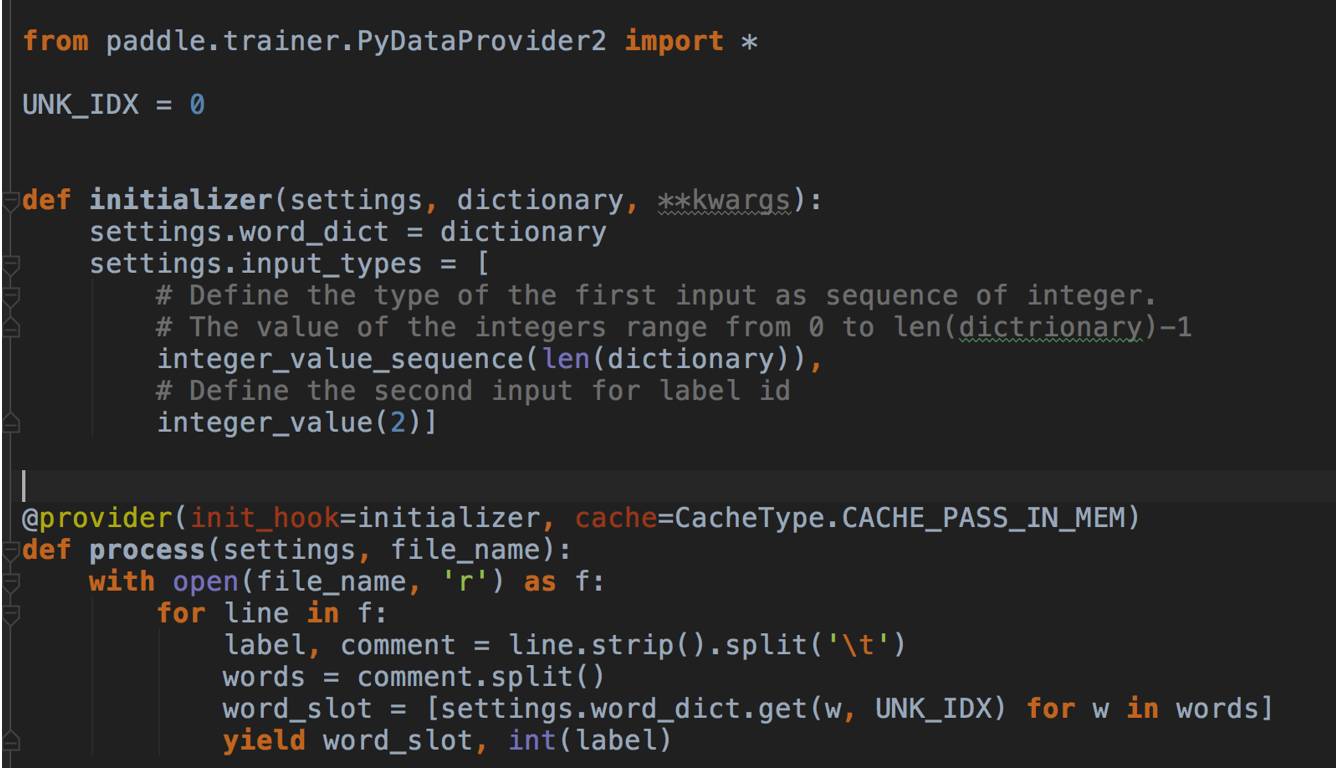
训练数据读取比刚才简单,因为是英语句子,直接读词就可以了,也不用分词。

网络配置的话,这个网络也比刚才更简单一些,首先经过一个embedding_layer,把词变成一个向量,然后输入到LSTM里,输出一个最大的值,用这个值来做分类。
通过情感分类我们还可以做什么?
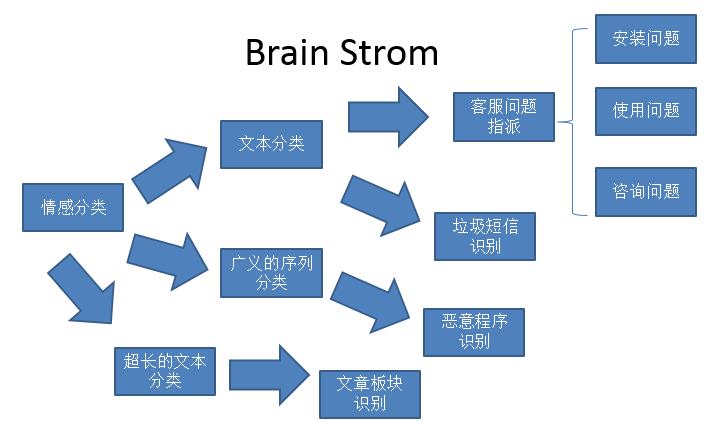
现在我们有情感分类的demo,情感分类最简单的拓展就是文本分类,文本分类可以做智能客服,比如客服有很多不同类型的问题,但是我也有很多客服把这些不同类型问题指派给相应的客服。实际上问题分类和情感分类也是一样的,目前百度上也有产品,是夜莺团队做的。再说文本分类的应用,比如说是一个手机助手的APP,我要识别垃圾短信。
那么怎么让模型有持续的学习能力能够识别不断进化的垃圾短信?我们可以再给他新的数据,他可以知道新的垃圾是什么,也可以用文本分类。再说情感分类,从文本这个角度展开成一个更广义的序列分类。然后我们可以做恶意程序的识别,因为我们写的Code也是文本序列,或者类似的文本序列,或者对Code进行一些简单的提取,总归还是可以做恶意程序的识别。再比如情感分类的文本很短,可能就是一句话,但是可以变成一个文章的识别,就是超长文本的识别。超长文本可以做文章板块,比如新闻类的APP,投稿的新闻没有分板块,用这个模型可以预先将新闻分配到一个板块里,先让机器分一遍。
PaddlePaddle中文档的演示非常多,而且是非常实用的。PaddlePaddle中的demo分这么几种,一种是图像分类一种,是自然语言处理,还有推荐系统的演示。这些都可以演示,比如机器翻译的话,可以实现从广告词到另一个广告词的翻译,这些都是我们实际已经完成的东西。

除了PaddlePaddle主版本库中的一些demo,目前PaddlePaddle还对外征集demo的创意。比如你说一个想要的东西,并提供数据集,它可以是开源或者开放的,我们去做。在我们的Github上,IM的平台上已经有人反馈说让我们做一个语音识别的演示,我们也已经放到这里面。或者你说一个特别有意思的事情,比如说智能家居或者之类的东西,我们可以做一下。当然最后一点,因为PaddlePaddle是开源的,你们也可以直接贡献自己的demo。
PaddlePaddle从9月份开源到现在,大家的评价都比较好。但是还是有一些质疑开源的版本不是最新的。但是PaddlePaddle的话,目前来看有两点,首先确实不是所有的东西都开源,有一些东西不是我们的部门写的,是别的部门写的,我们没有做协调,所以没有开源,还有就是涉及业务的代码,有保密性,比如数据是百度内部的,但是剩下的不涉及业务的代码、不涉及其他部门的代码均已经开源。而且Github的版本库是PaddlePaddle的主版本库,现在所有的开发都是基于Github开发,Github也是我们目前唯一的版本库。
联系我们

答疑环节
提问1:我想问一下目前PaddlePaddle支持的深度学习的模型,它的网络结构都有哪些?
于洋:PaddlePaddle支持什么样的模型? 常见的都支持,RNN支持所有的RNN,你也可以自己定义内部怎么连接,包括在RNN后面加一个卷积,输入数据中一些不常用的格式我们也支持。我们可以有两层的序列模型,比如对一个文章分类,每个词是一个Sepuence,这也是支持的。自然语言处理中所有的问题都支持的,而且目前做的比较好。图像问题在我们开源之前,支持力度比较薄弱,现在一些其他的图像问题我们也做,下周会开始做所有的图像东西。语音我们也有相应的产品。
提问2:PaddlePaddle有没有做移动端上面的优化计算?
于洋:这个问题是这样的。我们之前在手机百度上面有PaddlePaddle的模型跑,但是之前的模型比较小,所以都是开发一个简单的框架。移动端的开发我们会在一个半月之内放一个版本出来,那个版本是支持ARM的训练和预测。预测框架的话,可能年底会有手机端的预测框架。
提问3:我们这个PaddlePaddle是不是支持模型并行?具体怎么实现?把某一个放到单独节点?
于洋:支持。首先可以用稀疏来做,如果模型在某一层比较大,这个使用稀疏更新。还有多块显卡之间的模型并行我们也做了,可以在某些显卡上跑一些层,其他显卡跑另一些层。但是在某些节点做模型的一部分,在另一些节点做模型的下一部分,这个还没有做。在百度暂时没有更大的神经网络需求,去做多机的模型并行。
提问4: 百度的神经网络框架有没有使用专用处理器,或者FPGA?
于洋:我们的预测有专门的FPGA,但是那也是另外一个团队做的。我个人理解专用的处理器在神经网络中应用最大的一点应该是在预测里,训练的时候大家可以等一下,但是预测需要非常快,需要非常非常快的时间里有个反馈。其实预测最大的市场应该是手机,但是在手机上用专用处理器和FPGA应该不太靠谱。所以百度现在目前来讲有做专用硬件的,但也是在硬件上做预测,训练的话我们没有做尝试,可能目前对于我们来讲这不是一个非常关键的问题。但是预测对手机或者说对于其他的加速还是非常重要的。
讲师介绍
于洋,百度工程师,从事百度深度学习平台PaddlePaddle开发工作。硕士毕业于天津大学,15年毕业后加入百度深度学习实验室。随后一直从事深度学习系统的研发,主要负责深度学习系统的性能优化和功能开发工作。
延伸阅读
下面这两篇文章是两个经过广泛使用和验证过的平台:Tensorflow和Deeplearning4j。
下面是各公司针对企业的业务利用机器学习来提高产品体验的一些经验。依次是百分点、Twitter,1号店,携程,搜狗,达观数据。最后是一篇总结深度学习全球进展和预测2017的文章。
大数据杂谈
ID:BigdataTina2016

▲长按二维码识别关注
专注大数据和机器学习,
分享前沿技术,交流深度思考。
欢迎投稿,欢迎加入社区!
每一次相遇都是久别重逢。时隔一年,QCon北京站华丽归来。20+热点专题出炉,涵盖区块链、VR、TensorFlow、深度学习等潮流技术,及研发安全、移动专项、智能运维、业务架构等一手实践。国内外技术专家共襄盛举,即刻报名,尽享7折特惠。点击“阅读原文”报名。
以上是关于百度PaddlePaddle深度学习平台:面向工程师,性能优先的主要内容,如果未能解决你的问题,请参考以下文章