Hadoop之Shuffle机制详解
Posted pengbangxiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之Shuffle机制详解相关的知识,希望对你有一定的参考价值。
1.什么是Shuffle机制
1.1)在Hadoop中数据从Map阶段传递给Reduce阶段的过程就叫Shuffle,Shuffle机制是整个MapReduce框架中最核心的部分。
1.2)Shuffle翻译成中文的意思为:洗牌、发牌(核心机制:数据分区、排序、缓存)
2.Shuffle的作用范围
一般把数据从Map阶段输出到Reduce阶段的过程叫Shuffle,所以Shuffle的作用范围是Map阶段数据输出到Reduce阶段数据输入这一整个中间过程!
3.Shuffle图解
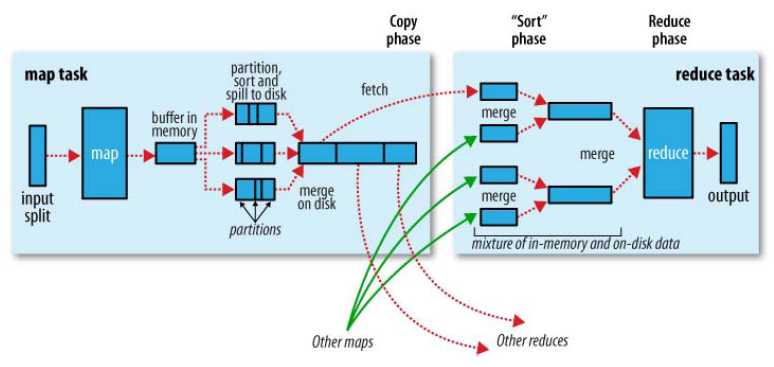
上图是官方对Shuffle过程的描述,通过图片我们可以大致的了解到Shuffle的工作流程。Shuffle并不是Hadoop的一个组件,只是map阶段产生数据输出到reduce阶段取得数据作为输入之前的一个过程。
4.Shuffle的执行阶段流程
1).Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value序列化数据,Partition分区信息等。
2).Spill 阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
3).Merge 阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
4).Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
5).Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程(一个是内存到磁盘的合并,一个是磁盘到磁盘的合并)对内存到本地的数据文件进行合并操作。
6).Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask 阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可
5.总结
Shuffle的大致流程为:Maptask会不断收集我们的map()方法输出的kv对,放到内存缓冲区中,当缓冲区达到饱和的时候(默认占比为0.8)就会溢出到磁盘中,如果map的输出结果很多,则会有多个溢出文件,多个溢出文件会被合并成一个大的溢出文件,在文件溢出、合并的过程中,都要调用partitoner进行分组和针对key进行排序(默认是按照Key的hash值对Partitoner个数取模),之后reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据,reducetask会将这些文件再进行合并(归并排序)。
合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出每一个键值对的Group,调用UDF函数(用户自定义的方法))
注意
Shuffle 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快,正是因为Shuffle的过程中要不断的将文件从磁盘写入到内存,再从内存写入到磁盘,从而导致了Hadoop中MapReduce执行效率相对于Storm等一些实时计算来说比较低下的原因。
Shuffle的缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M
关于Shuffle的概念就介绍到这里,希望对初学Shuffle的人有一定的帮助和了解!
以上是关于Hadoop之Shuffle机制详解的主要内容,如果未能解决你的问题,请参考以下文章
hadoop-MapReduce框架原理之Shuffle机制
大数据之Hadoop(MapReduce):shuffle之ReduceTask工作机制
Hadoop学习之路(二十三)MapReduce中的shuffle详解
大数据之Hadoop(MapReduce):shuffle之MapTask工作机制
大数据技术之_05_Hadoop学习_02_MapReduce_MapReduce框架原理+InputFormat数据输入+MapReduce工作流程(面试重点)+Shuffle机制(面试重点)(示例