大数据之Hadoop(MapReduce):shuffle之ReduceTask工作机制
Posted 浊酒南街
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之Hadoop(MapReduce):shuffle之ReduceTask工作机制相关的知识,希望对你有一定的参考价值。
1.ReduceTask工作机制
ReduceTask工作机制,如图4-19所示。
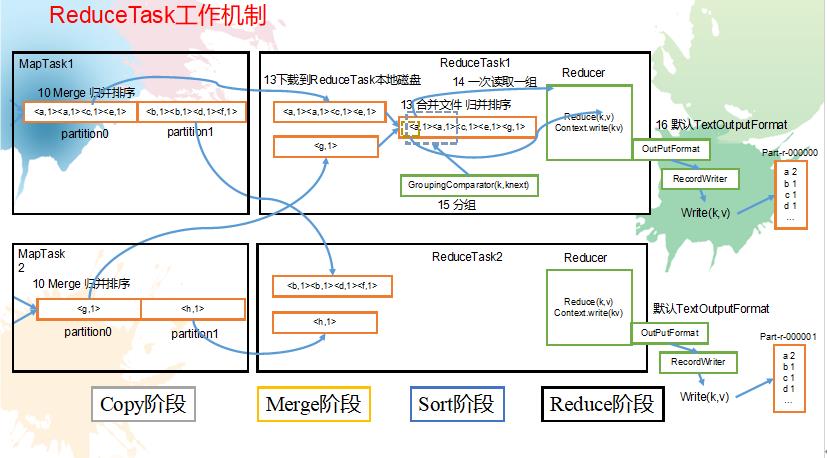
2.具体阶段
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
3.设置ReduceTask并行度(个数)
ReduceTask的并行度同样影响整个Job的执行并发度和执行效率,但与MapTask的并发数由切片数决定不同,ReduceTask数量的决定是可以直接手动设置:
// 默认值是1,手动设置为4
job.setNumReduceTasks(4);
4.实验:测试ReduceTask多少合适
(1)实验环境:1个Master节点,16个Slave节点:CPU:8GHZ,内存: 2G
(2)实验结论:
表4-3 改变ReduceTask (数据量为1GB)
MapTask =16
ReduceTask 1 5 10 15 16 20 25 30 45 60
总时间 892 146 110 92 88 100 128 101 145 104
5.注意事项

以上是关于大数据之Hadoop(MapReduce):shuffle之ReduceTask工作机制的主要内容,如果未能解决你的问题,请参考以下文章