Hadoop开启Yarn的日志监控功能
Posted 互联网小阿祥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop开启Yarn的日志监控功能相关的知识,希望对你有一定的参考价值。
1.开启JobManager日志
(1)编辑NameNode配置文件$hadoop_home/etc/hadoop/yarn-site.xml和mapred-site.xml

- 编辑yarn-site.xml
<!-- Site specific YARN configuration properties -->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启日志聚合 -->
<!-- 是否启用日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志存储时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>10080</value>
</property>
<!--当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚集功能时有效),如此便可通过appmaster UI查看作业的运行日志。-->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/flink/log</value>
</property>
<!-- 日志服务器的地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://localhost:19888/jobhistory/logs</value>
</property>
<!-- 正在运行中的日志在hdfs上的存放路径 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
<!-- 运行过的日志存放在hdfs上的存放路径 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
</configuration>
- 编辑mapred-site.xml
<property>
<!-- 表示提交到hadoop中的任务采用yarn来运行,要是已经有该配置则无需重复配置 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--日志监控服务的地址,一般填写为namenode机器地址 -->
<name>mapreduce.jobhistroy.address</name>
<value>hadoop101:10020</value>
</property>
<!--填写为namenode机器地址-->
<property>
<name>mapreduce.jobhistroy.webapp.address</name>
<value>hadoop101:19888</value>
</property>
#复制配置文件到集群的其他机器
scp mapred-site.xml 用户@IP地址:/目标机器文件夹路径
scp yarn-site.xml 用户@IP地址:/目标机器文件夹路径
(3)重启yarn,重启历史服务

./stop-yarn.sh && ./start-yarn.sh
#进入到hadoop的安装目录
cd $hadoophome/hadoop/sbin

kill -9 117681 && ./mr-jobhistory-daemon.sh start historyserver
(4)查看服务运行情况
jps
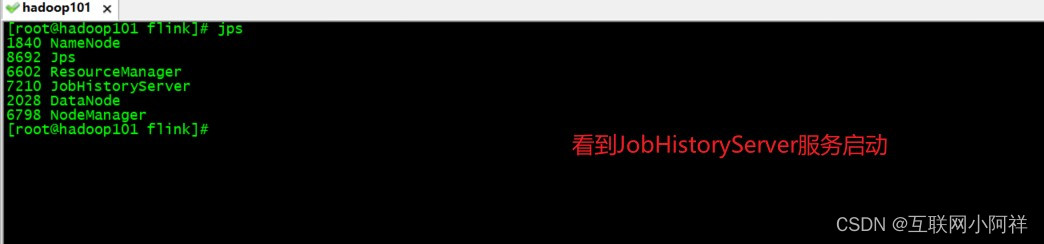
(5)运行flink on yarn

./bin/flink run -m yarn-cluster -c com.lixiang.app.FlinkDemo ./flink-demo-jar-with-dependencies.jar
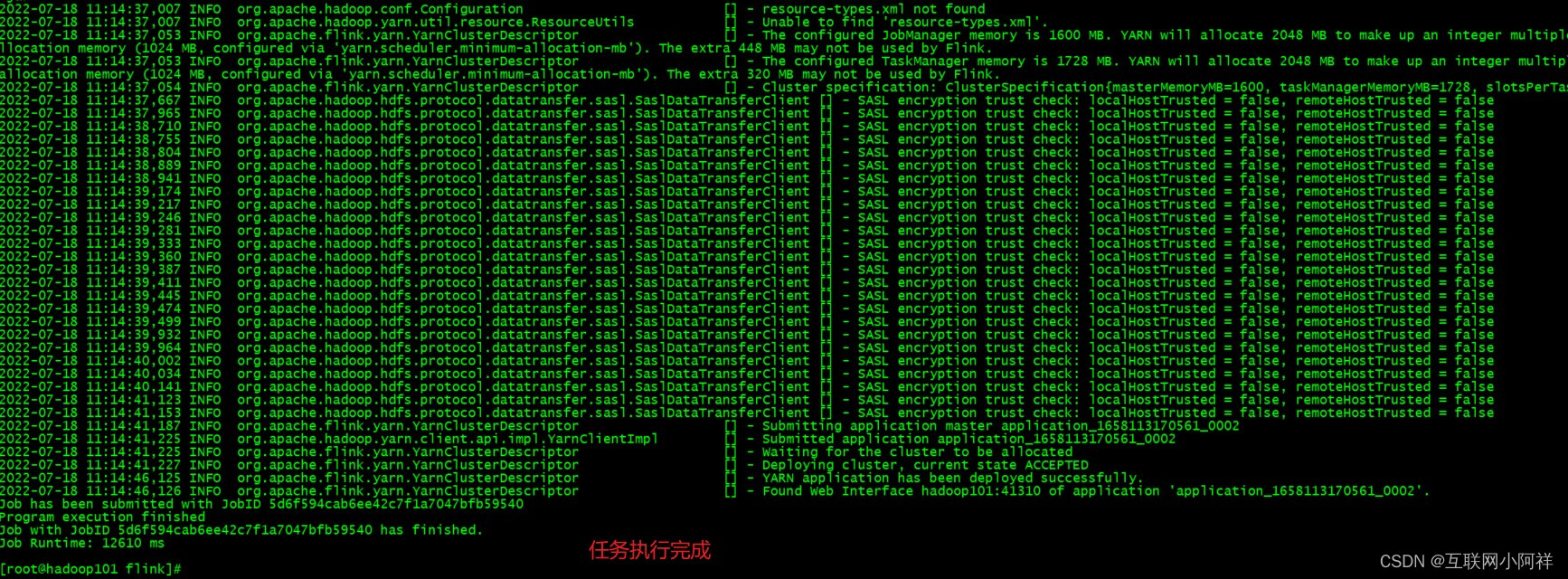
(6)查看hadoop控制台
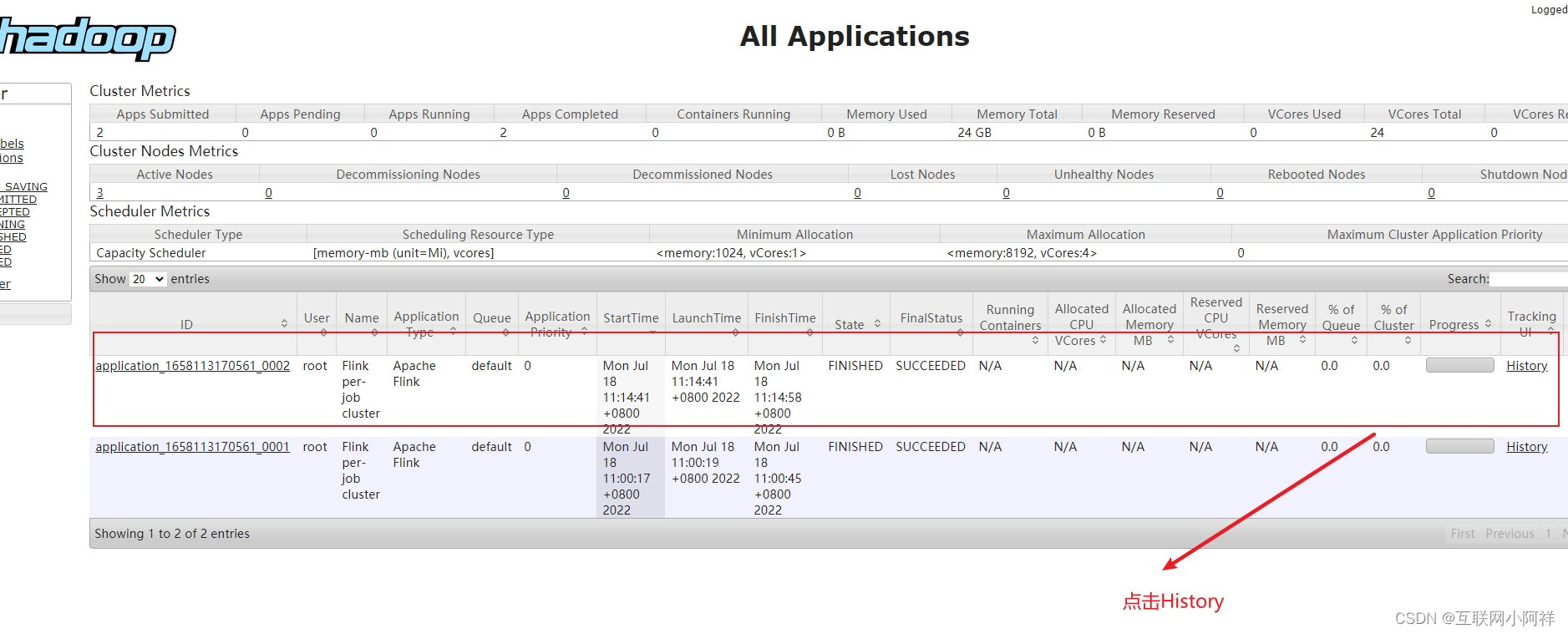
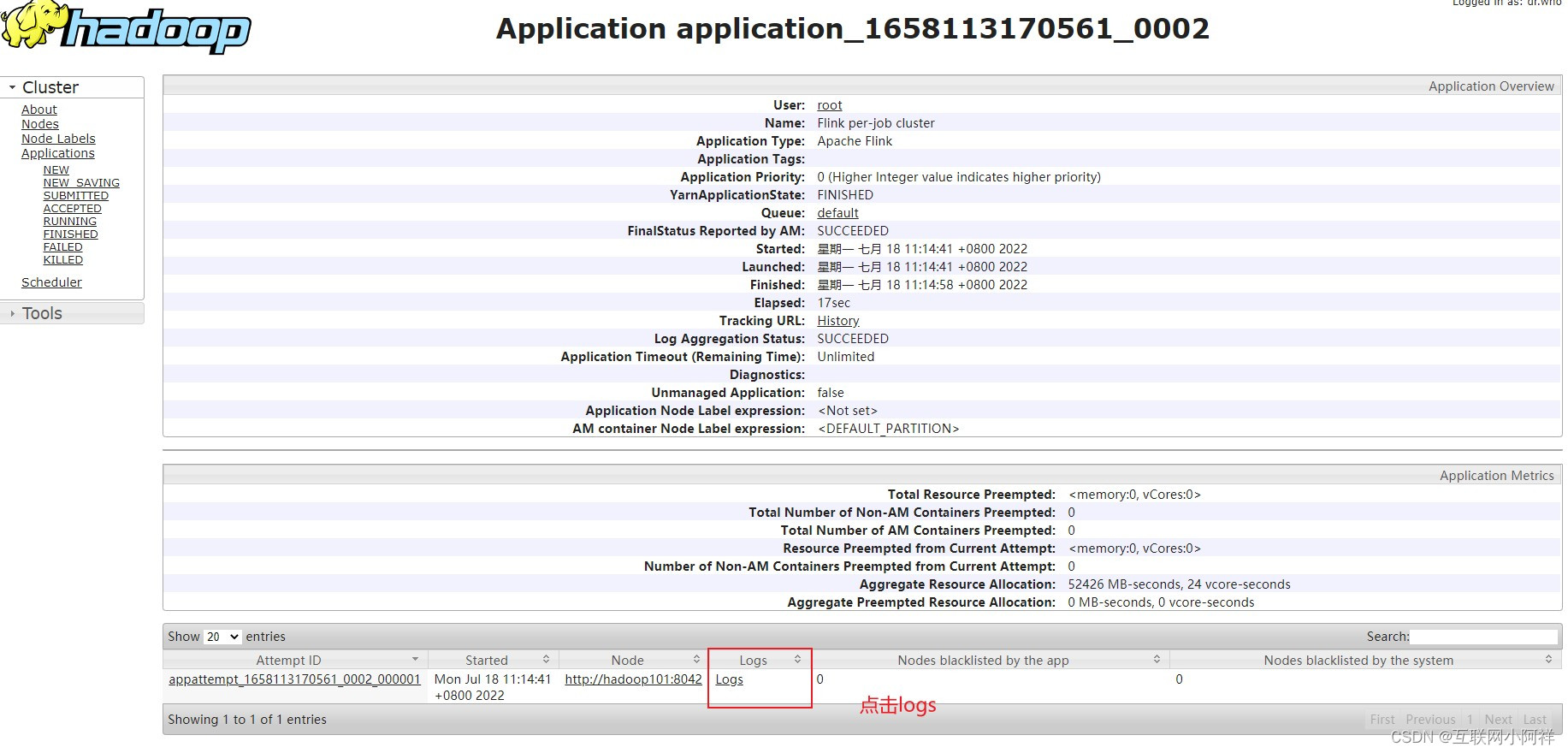
2.开启TaskManager日志
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.139.101:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>ip</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
</configuration>
CREATE EXTERNAL TABLE tweets
COMMENT "A table backed by Avro data with the Avro schema embedded in the CREATE TABLE statement"
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS
INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION '/user/hive/warehouse'
TBLPROPERTIES (
'avro.schema.literal'='
"type": "record",
"name": "Tweet",
"namespace": "com.miguno.avro",
"fields": [
"name":"username", "type":"string",
"name":"tweet", "type":"string",
"name":"timestamp", "type":"long"
]
'
);
insert into tweets values('zhaoliu','Hello word',13800000000);
select * from tweets;
//建立外部 schema
CREATE EXTERNAL TABLE avro_test1
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS
INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION '/user/tmp'
TBLPROPERTIES (
'avro.schema.url'='hdfs:///user/hive/warehouse/student.avsc'
);
"type":"record",
"name":"student",
"namespace":"com.tiejia.avro",
"fields":[
"name":"SID",
"type":"string",
"default":""
,
"name":"Name",
"type":"string",
"default":""
,
"name":"Dept",
"type":"string",
"default":""
,
"name":"Phone",
"type":"string",
"default":""
,
"name":"Age",
"type":"string",
"default":""
,
"name":"Date",
"type":"string",
"default":""
]
"type": "record",
"name": "Tweet",
"namespace": "com.miguno.avro",
"fields": [
"name": "username",
"type": "string"
,
"name": "tweet",
"type": "string"
,
"name": "timestamp",
"type": "long"
]
CREATE EXTERNAL TABLE tweets
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS
INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION '/user/tmp'
TBLPROPERTIES (
'avro.schema.url'='hdfs:///user/hive/warehouse/tweets.avsc'
);
以上是关于Hadoop开启Yarn的日志监控功能的主要内容,如果未能解决你的问题,请参考以下文章