hadoop 3.x 配置日志功能
Posted code never lies
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop 3.x 配置日志功能相关的知识,希望对你有一定的参考价值。
打开$HADOOP_HOME/etc/hadoop/yarn-site.xml,增加以下配置(在此配置文件中尽量不要使用中文注释)
1 <!--logs-->
2 <property>
3 <name>yarn.log-aggregation-enable</name>
4 <value>true</value>
5 </property>
6 <!-- logs keep time -->
7 <property>
8 <name>yarn.log-aggregation.retain-seconds</name>
9 <value>604800</value>
10 </property>
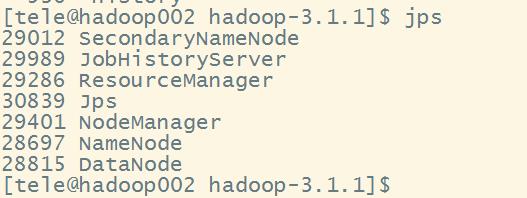
依次执行以下命令start-dfs.sh,start-yarn.sh.mr-jobhistory-daemon.sh start historyserver启动完毕后jps
接下来执行MapReduce程序
hadoop fs -rm -r -f /usr/tele/hadoop/wcoutput
hadoop jar /opt/module/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /usr/tele/hadoop/wcinput /usr/tele/hadoop/wcoutput
执行完毕后打开mapreduce管理界面(8088),再打开history(19888),然后打开logs
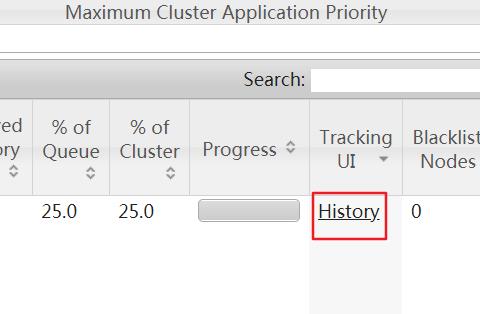
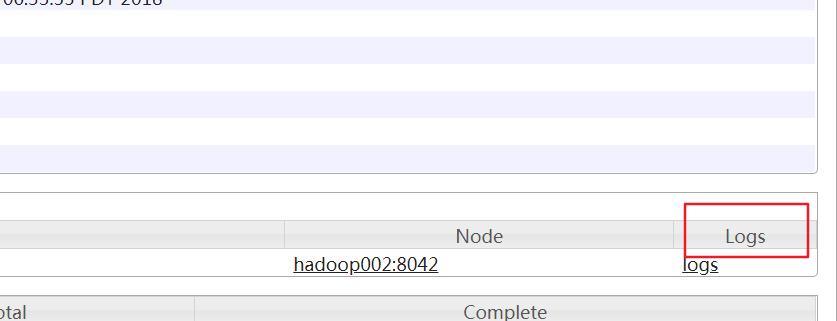
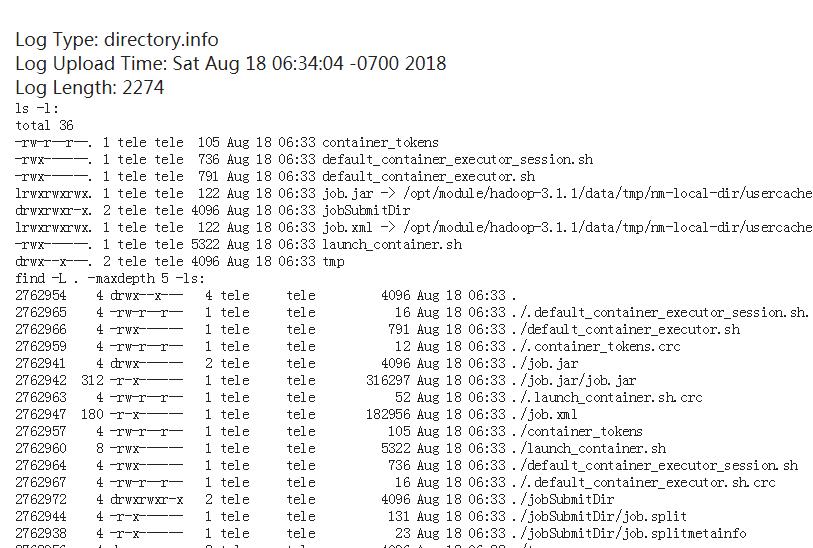
注意的是如果启用了日志聚集功能,那么在userlogs下生成的yarn的作业日志目录在被上传到hdfs上之后就会从linux上删除掉了,大概在执行完mapreduce程序的几秒后
history打不开的请参考https://www.cnblogs.com/tele-share/p/9498698.html
以上是关于hadoop 3.x 配置日志功能的主要内容,如果未能解决你的问题,请参考以下文章