2017上海QCon之旅总结(下)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2017上海QCon之旅总结(下)相关的知识,希望对你有一定的参考价值。
本来这个公众号的交流消息中间件相关的技术的。十月去上海参加了QCon,第一次参加这样的技术会议,感受挺多的,所以整理一下自己的一些想法接公众号和大家交流一下。
三天的内容还挺多的,之前已经有上篇和中篇,这一片是最后一篇,内容包含以下三个议题:
- 《携程第四代架构之软负载SLB实践之路》
- 《恒生中间件如何助理证券经纪业务发展》
- 《Heron的Exactly-Once实现》
《携程第四代架构之软负载SLB实践之路》
这场分享主要介绍了携程软负载的设计和实现。
首先我们先弄清楚什么是软负载,然后再来看这篇分享的内容。
这里的软负载一词确切的含义应该是通过软件进行负载均衡。负载均衡可以通过硬件设备实现,也可以通过软件实现。而由于硬件成本高,所以往往当系统的量达到一定阶段(这个时候堆硬件的成本已经不可以接受了)就会转向采用软件进行负载均衡的方式。LVS是业界最著名的软负载。
回到携程软负载的分享中,这场分享主要介绍了携程遇到的一些问题及解决方案:
- 如何设计一个业务开发人员可以使用的软负载系统?
- 如何提供高频调用且稳定返回的API?
- 如何解决多角色运维冲突的问题?
- 如何解决心跳检测的瓶颈问题?
- 如何利用好这个绝佳的监控场所?
第一个问题:如何设计一个业务开发人员可以使用的软负载系统?
携程对应用进行了抽象,将所有提供统一服务的应用抽象为一个group,group有如下属性:
- id
- domain和path
- 健康检测链接health-check
- 机器列表servers

这层抽象主要是为了屏蔽掉Nignx的只是壁垒,因此业务人员就不在需要了解Nignx的配置内容。
第二个问题:如何提供高频调用且稳定返回的API?
这个问题的来源是抽象出来的Group文件的变更合并到配置文件,这些变更导致写修改配置文件的时间变长的问题。
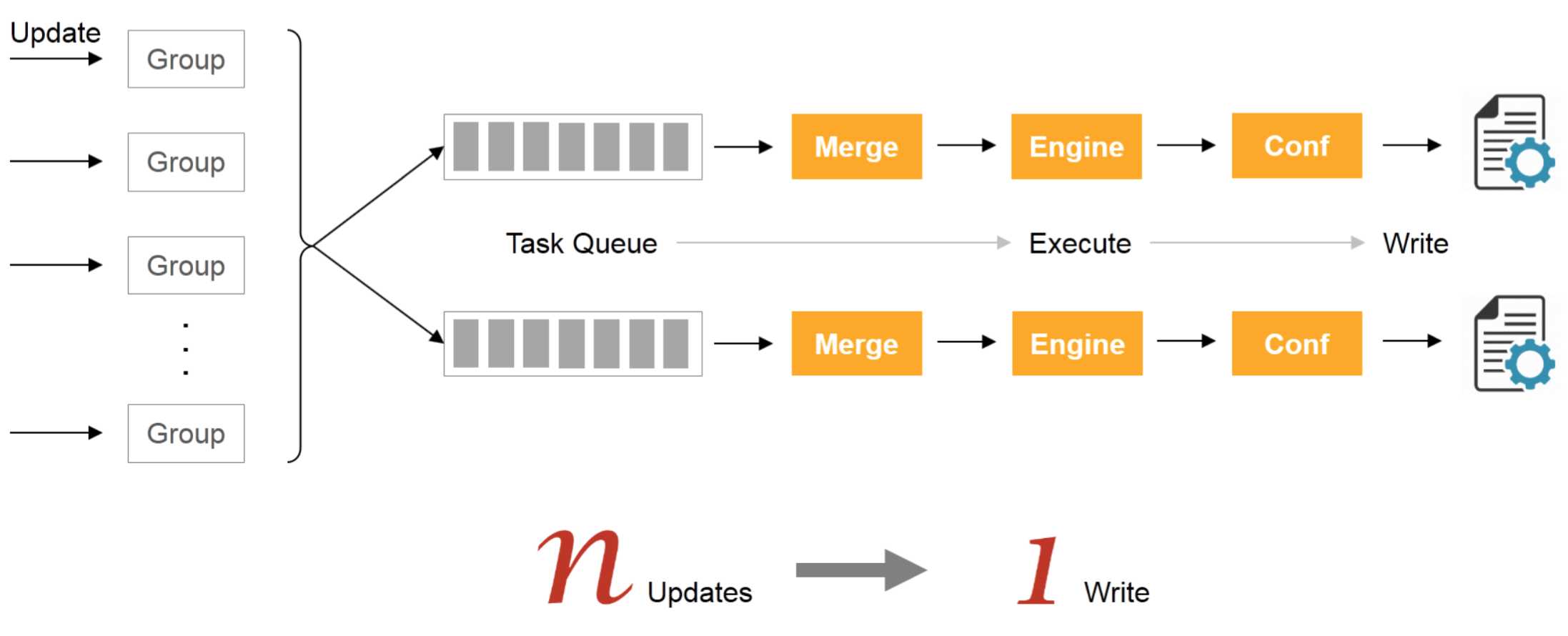
携程采用了增加队列,然后合并操作的方式,PPT中称为伪并发的方式解决Group变更导致的写入问题。
第三个问题:如何解决多角色运维冲突的问题?
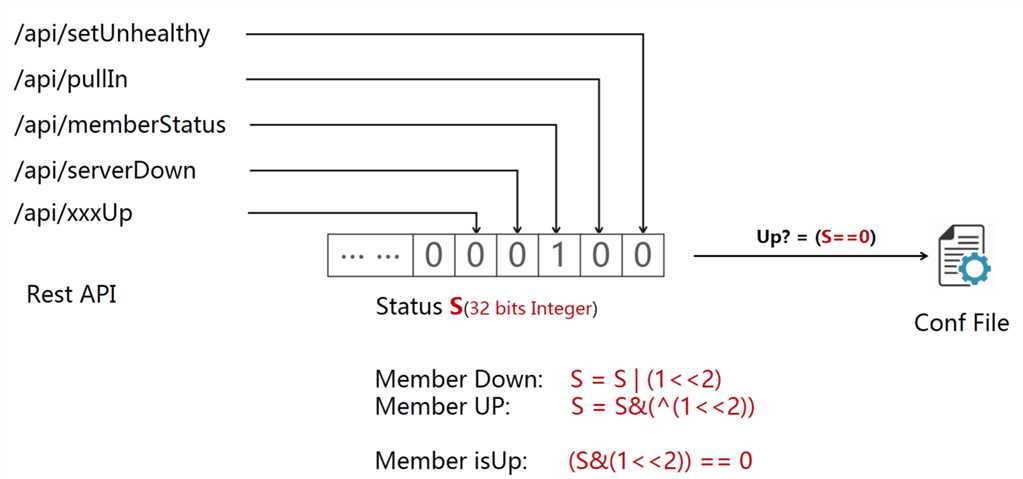
这个其实非常简单的小技巧了,用多个位来标识不同的状态,最终根据值的结果来提供服务。
因为SLB节点的状态无非两种:提供服务 or 不提供服务,这里只要有一位为1就标识不可提供服务。
第四个问题:如何解决心跳检测的瓶颈问题?
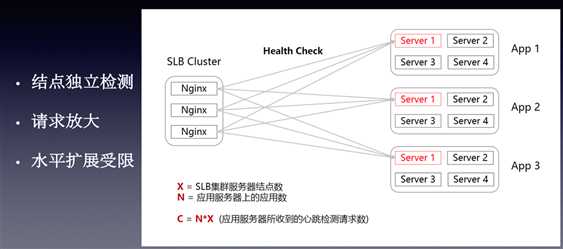
SLB服务器是有限的,远小于应用数量的,如上图,随着应用不断增加,心跳数据就会成为SLB服务器的一个负担。
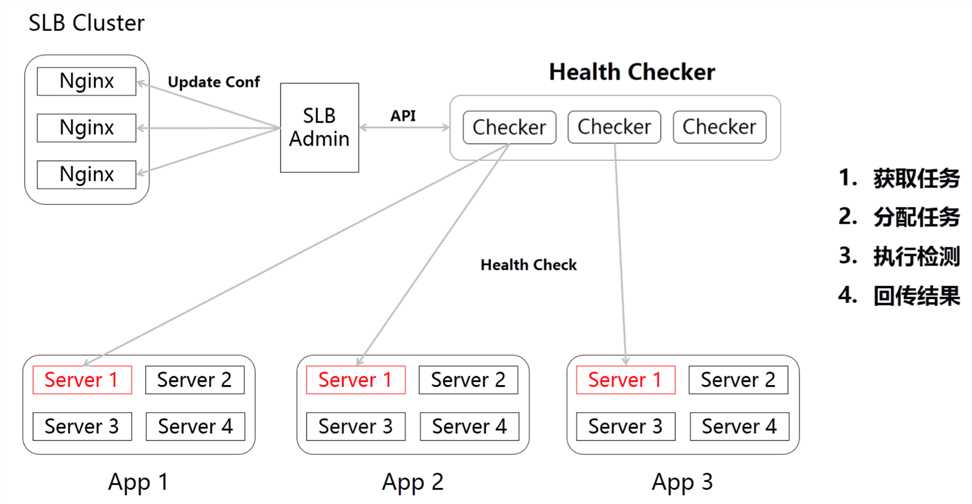
携程的处理方式也非常简单:将健康检测模块单独抽离出去,且健康检测模块也可以水平扩容,这样解决掉SLB服务端的压力。
不过这里隐含着一个问题,其实在网络环境中去判定一台机器是否可用是一个非常复杂的问题。
思考一下,如果Checker认为Server1不可用,这个时候可能是Checker本身存在问题或者Checker和Server1之间的网络存在问题,并不能断定Server1不可用。
又比如在网络分区的情况下,可能Checker认为Server1可用,但是其他应用可能无法通过网络访问到Server1。
分享现场我提出了这个问题,携程研发总监王兴朝给出的答复是这个问题确实非常复杂,确实通过单checker的方式是无法确定Server状态的(其实多Checker也很难)。携程的解决方式是由和应用在同一网段的checker去检查应用,尽量减少网络带来的问题。同时对一些状态比如5XX、4XX等会做记录,会有一些人工接入的处理措施。
其实我对这个实现并不是很满意,因为这个最困难的问题并没有解决,只是说结合人工去处理了。
第五个问题:如何利用好这个绝佳的监控场所?
这个是一个拓展的话题了,本身SLB是所有流量的入口,所以如何用好这块做好监控也是值得讨论的一个问题。
资料参考搜索2017上海QCon进行下载。
《恒生中间件如何助理证券经纪业务发展》
证券业务其实和平时接触的互联网业务相差还是比较大的,不过冲着“中间件”的标题就去听了这场分享。
这场分享除去一些证券业务背景的介绍,主要分享了一下几个问题:
- 如何将交易状态返回给客户端?
- 如何让用户以最快的速度下单?
- 如何缩短券商的清算时间?
- 业务开发要快速并且没有缺陷?
第一个问题:如何将交易状态返回给客户端?
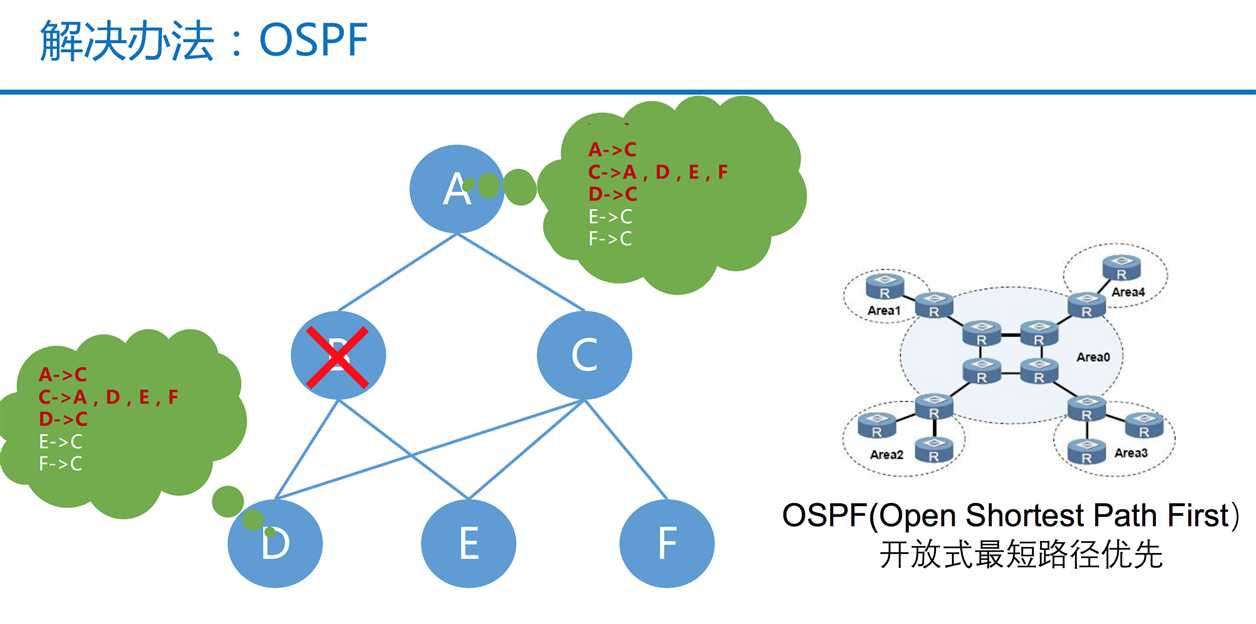
引用了OSPF算法,在B节点异常的时候,D节点的处理结果可以通过D->C->A的路径反馈给A。
关于这个算法我并不了解,有兴趣可以自己研究下。
第二个问题:如何让用户以最快的速度下单?
这块的解决方案技术含量挺高的,主要考虑到了CPU的亲和性、缓存对齐等问题,这些是Java程序员很难考虑到的点(可能99%的程序员也不会考虑到这么底层的优化)。
第三个问题:如何缩短券商的清算时间?
这个结合了证券业务的特点,在非交易时段机器都是空闲的,恒生中间件利用这个特点在非交易时段使用Docker的方式,更大限度的利用机器资源来做清算,提升效率(也是非常高效的利用机器,非常好的优化点)。
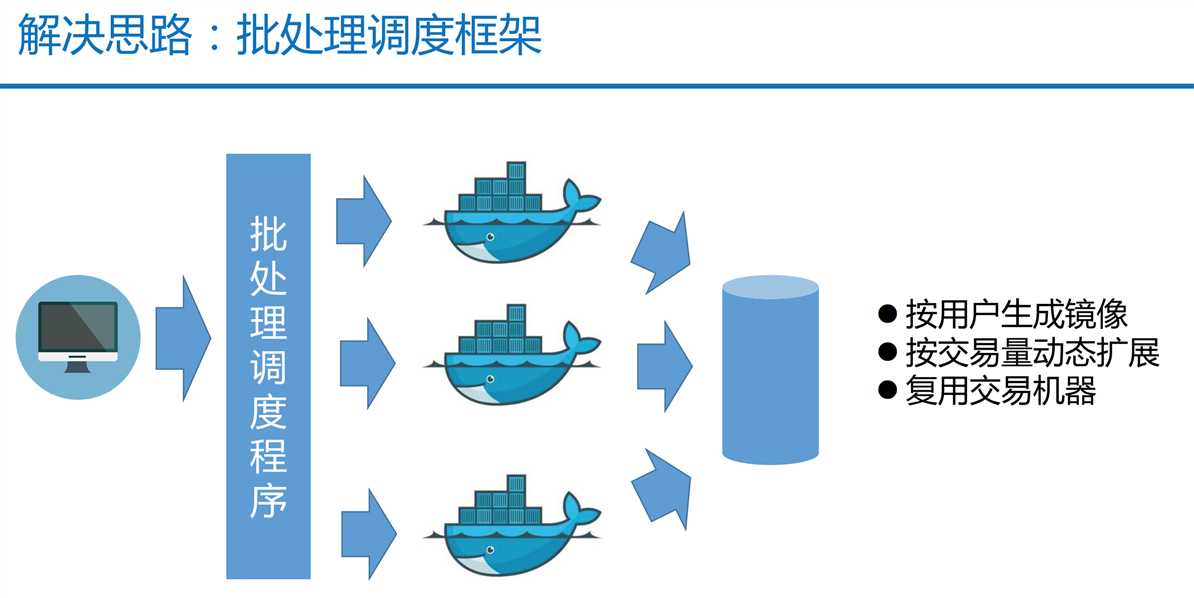
第四个问题:业务开发要快速并且没有缺陷?
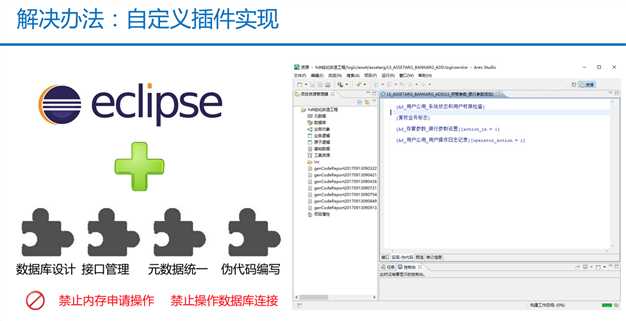
看到这个的时候还是有点震惊的,恒生把证券业务的场景不断的固话下来,最终把这些场景的业务都插件化,做业务开发的时候都可以用这种伪代码的方式(且是中文)来实现。
真的是超出了我原本对业务开发的认知。
这样在恒生做业务开发的程序员还有加之吗,以后还找得到工作吗?答:转行到券商去,写代码这么累的事就留给别人干吧:)
这场分享干货还是挺多的,特别是优化的实现上的很多小技巧。
《Heron的Exactly-Once实现》
这场分享完全是冲着Exactly-Once去的,但是实际听下来感觉重点不在Exactly-Once上,更多在他们公司的产品介绍上。
不过借这个题目聊一聊Exactly-Once语义。
Exactly-Once语义更多的是在消息队列的场景中,比如Kafka就提供了它支持Exactly-Once语义。
在消息队列中,消息分发的语义(Message Delivery Semantics)有如下几种:
- At Most Once:消息可能丢失,但不会重复投递
- At Least Once:消息不会丢失,但是可能会重复投递
- Exactly Once:消息不丢失、不重复,且只被投递一次
要弄清楚这些语义,首先先弄清楚消息为什么会丢失和重复。
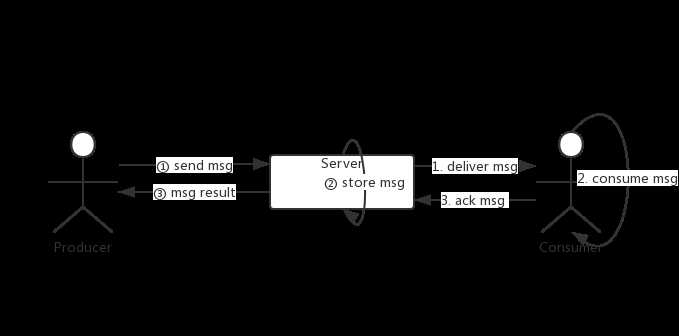
简单画了一下消息的生命周期,
发送流程有三个阶段:
- Producer向Server写入消息
- Server存储消息
- Server响应Producer写入结果
消费也有三个阶段:
- Server将消息投递给Consumer
- Consumer在本地执行消费逻辑
- Consumer应答Server自己的消费结果
在上述的步骤中,以下情况都将导致消息丢失或重复:
- 步骤①超时,此时Producer并不能确定消息是发送成功还是发送失败
- 如果Producer选择重新发送消息,那么Server可能存储了两条相同的消息,即消息重复
- 如果Producer选择不发送消息,可能Server一条消息都没有存储,那么消息就丢失了
- 步骤③的情况和步骤①是完全一致的,如果步骤②可能成功也可能失败,如果步骤③超时,则Producer也无法确定消息的情况
- 步骤1超时,此时Server不知道Consumer是否接收到了消息
- 如果Server重新发一次消息给Consumer,那么Consumer就会消费两次
- 如果Server不发送消息给Consumer,那么Consumer就可能没消费到消息
- 同样步骤3即响应给Server进度信息,如果超时,情况和步骤1完全一致
上面的流程并不准确,比如消费流程中,可能是收到消息后先ack给服务端,之后再执行消费,即步骤2、3的顺序调换。
语义的选择
- At Most Once:消息可能丢失,但不会重复投递
- At Least Once:消息不会丢失,但是可能会重复投递
- Exactly Once:消息不丢失、不重复,且只被投递一次
三种语义中,At Most Once、At Least Once都比较容易实现,Exactly Once在网络环境中则是非常困难的。
实际中,我们可能根据业务特点选择不同的语义支持(说白了是因为做不到支持Exactly Once),比如一些统计类的业务可以接受数据丢失那么可以选择At Most Once;而对于不能接受丢失的,采用At Least Once加业务实现幂等消费来支持。
简单粗暴的支持At Most Once语义的方式即:
- 遇到超时则不重发
- Consumer在收到数据后先ack进行进度更新,之后再进行消费(如果此时Crash了,下一次则从已经更新的进度开始继续消费,所以会丢失数据)
对于At Least Once语义支持:
- 遇到超时场景就重发
- 业务自己实现幂等(重复消费一条消息对业务无影响)
- Consumer消费完消息后再ack进度(可能消费完了消息未更新进度,此时Crash下一次获取的消息是上次消费过的)
Exactly Once
能做到支持Exactly Once吗?
Exactly Once是理想的消息分发语义(谁不期望消息补充不丢呢),业务方不需要过多的考虑消息的语义。
根据上面的消息生命周期,要实现这个语义,我们需要做哪些事情呢?
- 消息发送不重复(或发送重复的消息不会被存储下来)
- 已经发送成功的消息不会丢失
- 保证消费时,如果消息被消费了,那么进度一定被更新;如果消息没被消费,进度一定不会更新
对于第一步,保证发送不会重复或者重复的消息不会被存储下来
首先,消息需要唯一的ID,来识别两条消息是否是同一条消息。
(这里的唯一ID设计又是一个有趣的问题)
其次,Server端保证幂等,即如果收到的消息的ID相同,过滤掉消息。
这里涉及Server端需要缓存多久的消息来判断消息是否重复呢?不能每条消息过来之后把历史消息遍历一遍进行判断吧?
如果消息的ID是连续的会不会有一些帮助?
第二步,保证发送成功的消息不会丢失
这里涉及到数据的可靠性,一般消息中间件中我们都会对消息进行持久化,即写入到磁盘中。
然后通过主备或者其它方式来增加数据备份,保证数据可靠性。
第三步,保证消费进度和消费行为一致
在消费之前跟新进度则可能丢失消息;
在消费之后更新进度则可能重复消费;
那就是消费和进度要同时更新!
“保证消费时,如果消息被消费了,那么进度一定被更新;如果消息没被消费,进度一定不会更新”——这个描述,很容易想到事务。
这里可以通过将业务结果和消费进度在一个事务里面进行保存来达到一致。
比如借助mysql来存储业务结果和消费进度(业务结果本身可能就是存在MYSQL中),通过事务保证了如果业务结果存储成功,那么进度一定保存成功;业务结果保存失败,那么进度也不会保存。
(业务结果没保存成功自然可以理解为没有做业务,可以重新消费消息重做业务)。
完成以上步骤,好像可以一定程度上满足Exactly Once语义。
总结
以上是最后一篇关于2017上海QCon的总结。
3天的QCon之旅,还是收获挺多的,也认识了一些朋友。如果有机会,去参加一些类似的技术会议,对个人成长还是有一些帮助的。
2017QCon上海站PPT下载:PPT下载
欢迎关注公众号交流。

以上是关于2017上海QCon之旅总结(下)的主要内容,如果未能解决你的问题,请参考以下文章
测试大咖面对面:全链路压测大数据平台质量初创团队的测试技术,尽在“测试之旅2017-上海”