2017上海QCon之旅总结(中)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2017上海QCon之旅总结(中)相关的知识,希望对你有一定的参考价值。
本来这个公众号的交流消息中间件相关的技术的。上周去上海参加了QCon,第一次参加这样的技术会议,感受挺多的,所以整理一下自己的一些想法接公众号和大家交流一下。
三天的内容还挺多的,原计划分上下两篇总结一些自己听的分享的,发现内容太长所以又拆出了中篇,下面进入正题。
《Service Mesh:下一代微服务》
这次分享是我第一次听到Service Mesh这个名词,在此之前对它一无所知,只是当下都是微服务,所以冲着这个主题就去了解了一下。
Service Mesh对我来说很陌生,可能对很多人也是,所以我打算从稍微熟悉一点的词——微服务——来入手了解这块内容。
什么是微服务?
“微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中各个微服务可以独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务,每个微服务就是一个较小的业务服务。”——这个是我能找到的可能不准确,但是最容易理解的微服务的介绍了。
翻译一下就是说将一个复杂的系统拆分为独立的服务,各个小的服务之间协同工作来完成复杂系统的内容。
比如电商系统拆分为:用户、商品、促销、物流、交易、支付等多个子系统。子系统又可以继续拆分为更小的系统,比如交易系统可以继续拆分为购物车、下单等等。跟写代码拆不多,会将一个系统拆分为各个模块,每个模块之间通过接口交互来协同完成工作。
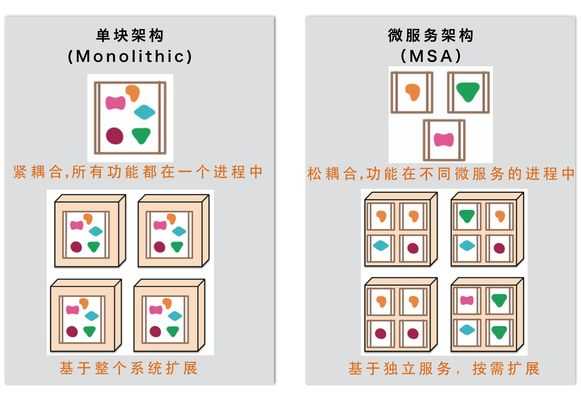
这个图简单的描述了微服务架构和传统架构的区别:
- 传统架构中,各个功能组成了一个系统,运行在一个进程中
- 微服务架构中,各个独立的功能单独部署,通过配合完成工作
微服务独立部署就带来了一些问题:
- 服务之间如何通信?
- 服务A如何发现服务B?
- 服务都可以水平扩展,那服务A如何确定调用服务B的那个进程?
当前的微服务是怎么做的?
以上的一些问题是微服务最直观的问题,那么现在的微服务是怎么做的呢?
(只从我司的微服务架构和我自己了解的内容描述,不一定准确)
1. 使用容器
服务拆分之后单个服务的机器要求会降低很多,所以会使用到虚拟机,类似Docker这样的技术,每个服务独立运行在一个虚拟机中。
对于服务的水平扩容之类的会变的很简单:服务本身是无状态的,直接拷贝镜像,然后启动一个新的虚拟机即可。这块完全可以做到自动化。
2. RPC
拆分开之后面临的第一个问题就是如何调用服务。目前的做法都是会有一个RPC中间件来完成远程的调用,比如阿里的Dubbo框架就是做RPC的。
3. 注册中心
增加了RPC之后,还有一个问题是如何感知到服务,即服务A如何找到服务B,这里就需要一个注册中心。所有服务都注册到服务中心,发生调用时就可以通过注册中心拿到服务列表,然后进行RPC调用。
4. 负载均衡
有了服务调用,就会有负载均衡的问题,简单的做法是在RPC框架中集成负载均衡的策略,做到尽量均衡的调用服务。这块很复杂,也可以独立拆出来做一个软负载中心。
目前我们的微服务基本是这样,前期都整合在分布式服务框架中(包含RPC、服务发现等),后面越来越复杂,慢慢的把负载均衡这些功能又单独拆出来做了软负载中心等。
下一代微服务是怎么样的?
说完了我们现在是怎么做服务拆分的,接着看看这次分享带来的内容。
什么是Service Mesh?
“A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.”
这是引用自Buoyant’s CEO William Morgan的一段描述,分享中也引用了这段话,并做了翻译:
服务网格是一个基础设施层,用于处理服务间通信。云原生应用有着复杂的网络拓扑,服务网格负责在这些拓扑中实现请求的可靠性传递。在实践中,服务网格通常实现为一组轻量级网络代理,它们与y应用程序部署在一起,而对应用程序透明。
这个是分享时对Service Mesh的定义:

我个人的理解是Service Mesh变成了基础组件,每个服务器上都会安装,然后是跨语言的,这样就避免的比如写一个RPC框架内嵌到应用中,这样就需要考虑多语言的问题了。
分享中以TCP协议的例子,介绍了在为服务中是如何慢慢演进出Service Mesh的。
最后介绍了Istio:An open platform to connect, manage, and secure microservices。
这场分享更多的是新技术入门的介绍,可以简单的理解为带着大家读了一遍ReadMe文档。
这是总结这场分享时从网上找到的资料,内容相差不多,同样包括了演进过程的介绍等,可以自行翻阅学习。
对于这样的新技术,鄙人认为可以花一些时间去了解一下,但是在国内落地应用到生产上可能还挺远的。如果你和我一样还是挣扎在如何把自己手上的工作做好,那么还是先聚焦一下把现在流行的一些方案弄清楚,毕竟一个人的精力是有限的。
《PhxQueue——微信开源高可用强一致分布式队列的设计与实现》
这场分享是这次上海QCon我最期待的一场分享了,因为我自己就是做消息中间件的。
作者是腾讯的高级工程师——梁俊杰。
分享内容大致可以分为三个部分:
- PhxQueue的开发背景,这部分包含了PhxQueue之前微信内部使用队列的介绍
- PhxQueue的设计和实现
- 最佳实践
第一部分:背景
内部队列使用场景
- 业务解耦
- 发布订阅模式
- 消息总线
- 分布式事务
- 拆分为多个本地事务
- 可靠消息传递
- 削峰和流控
- 缓存突发消息
- 按能力消费
- 延迟消费
- 定时任务-延后推
- 离线任务-随时拉
旧架构的问题
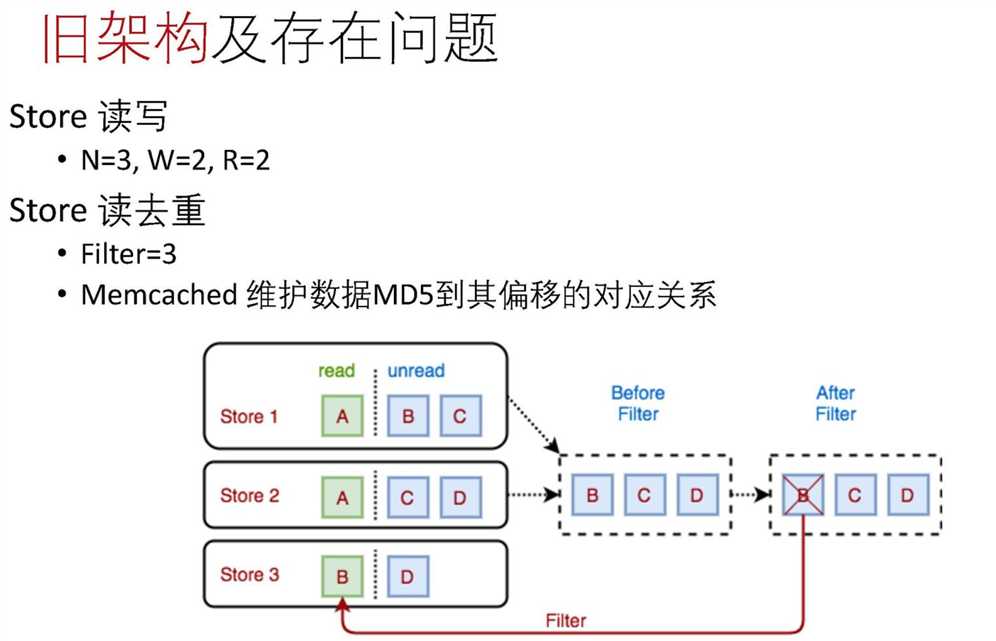
旧架构如上图,采用NRW的算法,读取数据的时候会做去重之类的处理。
PPT中描述了一些旧架构的问题:
- 积压下去重失效
- 依赖Memcached去重,Memcached容量满则去重失效
- 出队乱序
- NRW天然乱序缺陷
- 负载均衡效果差
- 负载均衡与分布式锁逻辑耦合
- 主动变更锁会导致一段时间重复出队
- 丢数据风险
- 采用异步刷盘
- 无3DC部署
以上是列出的一些问题,虽然不大理解为什么旧队列会采用这种结构(为什么不采用主从的结构来做呢?),不过这不是重点。
第二部分:PhxQueue设计和实现
主要特性:
- 同步刷盘,入队数据绝对不丢,自带内部对账
- 出入队严格有序
- 多订阅
- 出队限速
- 出队重放
- 所有模块可平行扩展
- 存储层批量刷盘、同步,保证高吞吐
- 存储层支持同城多中心部署
- 存储层自动容灾/接入均衡
- 消费者自动容灾/负载均衡
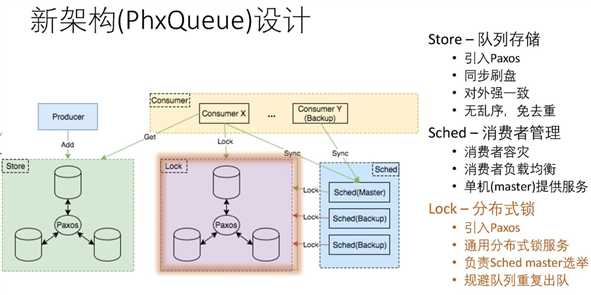
架构如上所示,引入Paxos之后:
- 保证副本一致性
- PLog直接作为消息队列的消息存储(Log即消息)
- InstanceID作为消息的偏移量
高可用
有一点提到了PLog as Queue,即消息直接存储在PLog中,这样整个系统存储的数据应该包含:
- Topic之类的元数据,可能是配置文件的形式
- 消息索引
- PLog(Paxos逻辑,同事也是消息内容)
其中数据量最大的就是消息内容,合并掉之后,存储量几乎可以认为减少了50%。
分享中,高可用部分提到每个Paxos Group会选举Master,Master会均衡分配到一组Paxos节点上。
比如group为100,节点数为3,那就取模,最终每个节点承载33个Master。这也是Paxos落地时常见的优化手段。
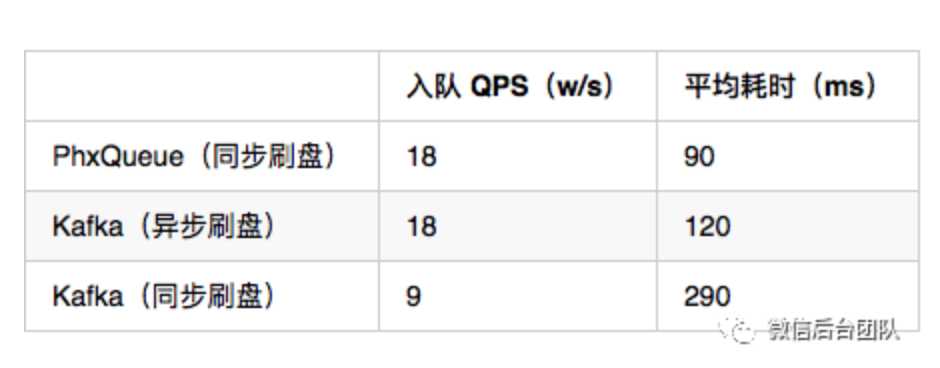
这是网上找到的微信团队介绍PhxQueue给出的性能数据(在关闭produce batch的情况下)。

PhxQueue总结
以上两部分主要是回顾了一下分享的内容,下面是我自己的总结,分以下几个部分:
- 模型
- 功能
- 性能
- 其他
模型
回顾这场分享内容,同时在网上查找了一些资料,有了以下的一个疑问:为什么PhxQueue的一些概念不和Kafka之类的业务消息中间件保持一致,便于理解?
比如Kafka的消费隔离是以Consumer Group为单位的,RocketMQ也是(当然,RocketMQ最终就是按照Kafka的模型写的Java版本),PhxQueue保持概念上的一致会不会更便于理解,PhxQueue Sub的概念还是比较难以理解。
另一个点在分享会后和作者交流了解到PhxQueue的Consumer是他们团队自己维护的,然后通过RPC的方式调用业务。这点上也和现在业界的做法有点差异,我更倾向提供SDK的方式。如果只是多语言的问题,我认为可以通过其他的手段解决,比如我们自己会整合公司的分布式服务框架,提供一个HTTP模式的消费来支持不同语言,当然对于开源版本的话,大家贡献一下不同语言的客户端也不是不可以。
功能

上面摘录了阿里云MQ的文档。
- 延迟消息
PhxQueue分享中提到了延迟推,不知道是否和上面说的定时消息是一致的,支持任意级别的延迟,最长40天。
题外话
延迟消息的实现本身是一个非常有趣的问题,之前我们考虑在自己的队列中实现延迟消费。期望做到阿里云上描述的这样。参考了开源的RocketMQ的做法,然而里面延迟消息的部分代码被移除了,通过蛛丝马迹能看到开源版本的实现方案,且只支持特定的延迟级别,对比阿里云上的版本是个残缺版本。
- 事务消息
事务消息也是一个挺有意思的功能。
事务消息理解为一种可撤销的消息,主要是为了保证业务和消息的一致性,即:
- 如果业务执行成功,那么消息一定发送成功
- 如果业务执行失败,那么消息不能发送出去
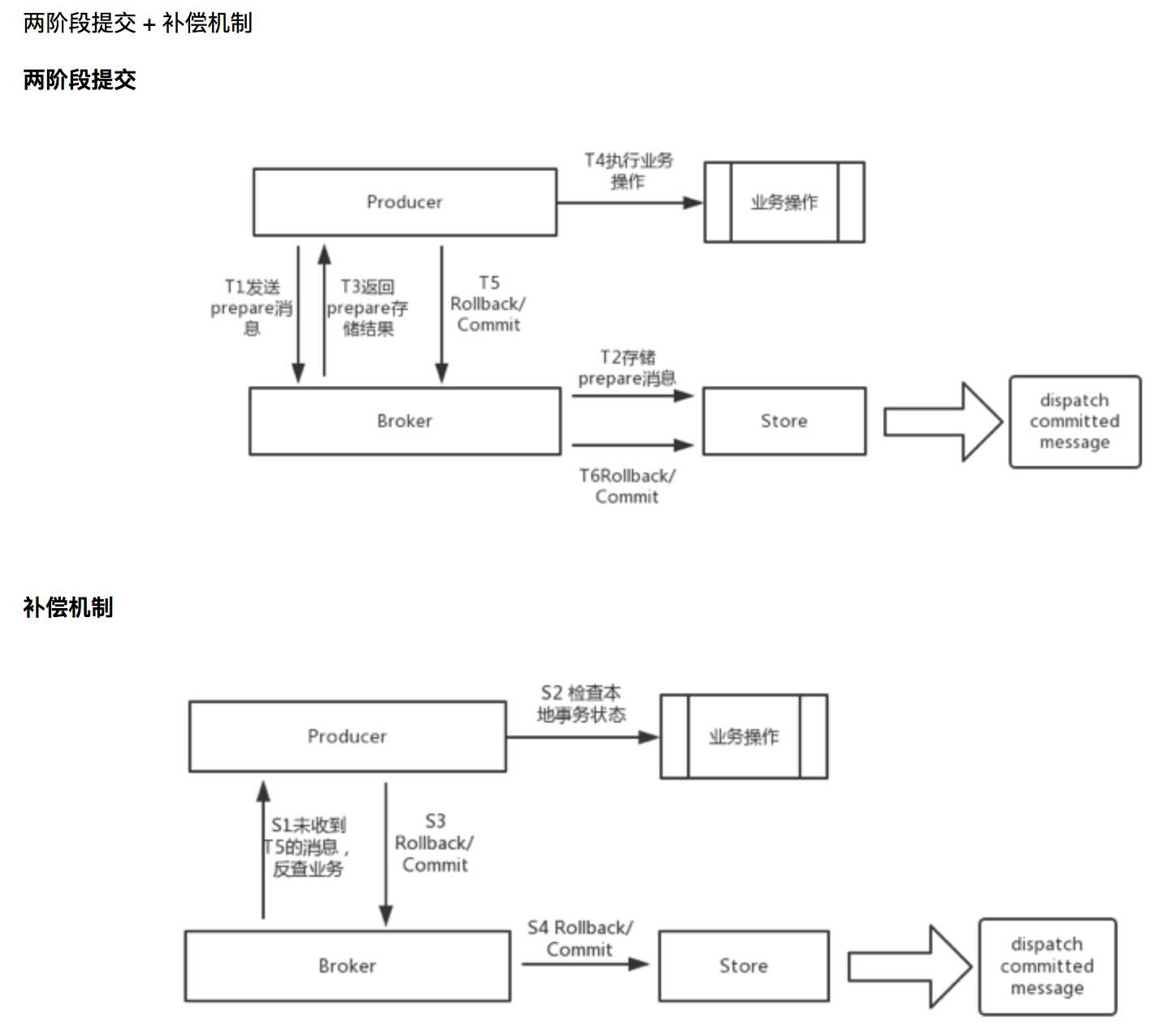
上图是之前我们考虑实现事务消息时的一个思路,通过两阶段提交和补偿机制来实现:
- 消息需要commit之后才能消费,保证只有业务成功后才会commit
- 通过补偿机制来解决commit失败的问题
(这块以后可以单独写一篇文档介绍)
不知道PhxQueue是否支持事务消息。
性能
根据PhxQueue给出的测试时结果,延迟在20ms+,这个延迟我认为是不可接受的。
比如电商中的下单业务,可能需要调用商品服务、库存服务、变更DB,之后发送一条消息出去。如果这些服务加起来只需要几个毫秒,而发送一条消息就消耗了20毫秒,显然是不可接受的(我们内部MQ的要求是99.9的请求在3ms以内)。
不知道是否有对Paxos做一些优化,比如Batching和Pipelining。
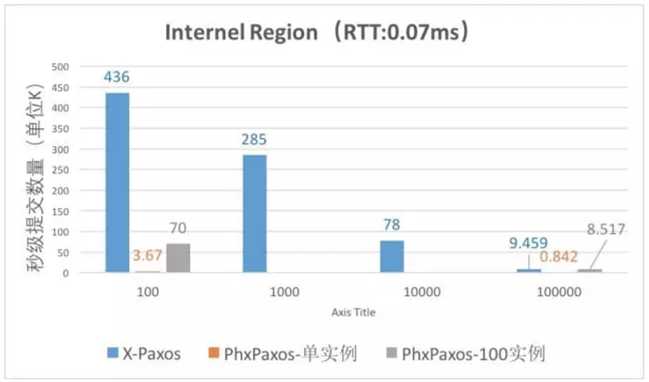
(横坐标是单事务大小Byte)
这是找到的阿里的X-Paxos和PhxPaxos的性能对比(出自阿里的一篇分享),如果确实PhxPaxos性能如上图测试结果,PhxQueue基于PhxPaxos是如何保证性能的,在电商场景中能达到生产要求吗(当然,这个资料来源是阿里的分享,本人不保证真实可靠)?
题外话
又得说题外话了,阿里虽然这样宣称,但是没见开源啊。「Talk is cheap. Show me the code.」
其他
除去以上,单单对于PhxQueue开源时提到的“我们将保持PhxQueue开源版本与内部版本的一致”的态度,就应该给予足够的尊敬(对于RocketMQ开源版本阉割掉部分功能真的是What the FXXK)。
另外作者梁俊杰真的非常Nice,认识梁俊杰算是上海QCon最大的收获之一。
未完待续...
本来计划上下两篇总结的,硬是拖成了上中下三篇。最后一篇主要想和大家聊一下《携程第四代架构之软负载SLB实践之路》和《Heron的Exactly-Once实现》。
欢迎关注公众号交流。
2017QCon上海站PPT下载:PPT下载

以上是关于2017上海QCon之旅总结(中)的主要内容,如果未能解决你的问题,请参考以下文章
测试大咖面对面:全链路压测大数据平台质量初创团队的测试技术,尽在“测试之旅2017-上海”
2021家有儿女梦想之旅上海站发布会 暨长三角地区海选启动仪式