从删库到恢复到跑不了路-数据恢复工程师解说顺丰删库事件
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从删库到恢复到跑不了路-数据恢复工程师解说顺丰删库事件相关的知识,希望对你有一定的参考价值。
本文由北亚数据恢复中心(http://www.frombyte.com)张宇所写,如有错误,祝愿各位中秋节删库还跑不了路。
事件回顾:
据悉,顺丰科技数据中心的一位邓某因误删生产数据库,导致某项服务无法使用并持续590分钟。事发后,顺丰将邓某辞退,且在顺丰科技全网通报批评。真实地玩了一把“从删库到跑路”。
毫无疑问地,我们又突然象被打了鸡血般,整了整衣领,挺了挺胸,存在感立马爆棚,拉个小板凳,就着中秋节的月光,絮絮叨叨地讲讲想当年。
想当年,我国那啥机构,设备升级改造,生产库在线热迁,脚本写错,rm掉了,然后,我们XXX,全部恢复所有数据(此处省略几万字,包含数十个自我标榜的“牛X”助词)。可惜,得替用户保密。
想当年,那啥机构,因为那啥,然后,……,算了,不能说,反正老传奇了。
啥也不能说,就从技术角度聊一聊,论删库到恢复,再到跑不了路的作死人生。
我肯定不会聊找个收费或开源数据恢复软件恢复,丢不起那人。
不聊Windows,因为基本和它无关。
仅限Unix、Linux上删除oracle、db2、mysql、Hadoop等的情况,就以rm -f为例吧。
数据库的载体有多种实现方式,文件或裸设备。多数情况下,系统会以文件的方式(一切皆为文件)对数据库数据文件进行管理。一套数据库,简单地看,物理上可以理解为一个或多个文件。删库,也就是删一个或多个文件了。
文件是存储在文件系统内的。Unix和Linux上有很多种文件系统,这些文件系统保留相同的VFS文件访问接口,确保用户透明地使用每种文件系统(当然,也会有一些小差异,但一般都会遵循POSIX之类的标准)。但实际上,不同的文件系统在内核设计上千差万别,这也导致了rm -f的不同底层表现,再导致每个文件系统在rm -f后恢复的可能性、难度的不同。简单地说,删除文件后的恢复,并不是文件系统规范中约定的技术细节,文件系统设计人员压根就没考虑过。
在文件系统上恢复一个删除的库,大概的思路应该是这样的: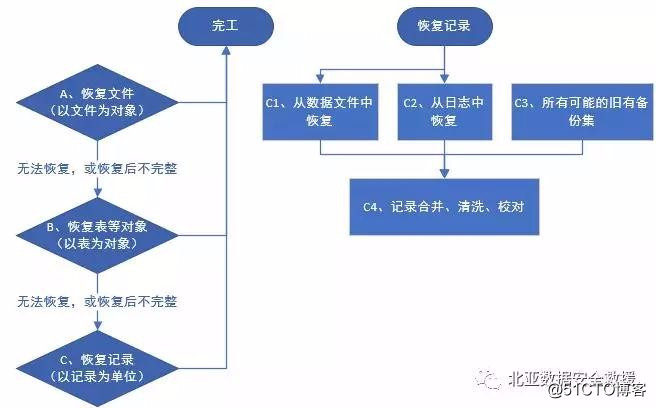
?图1:恢复被删除数据库的思路
上述方法A:
指以文件为对象进行恢复,也就是恢复文件系统上删除(或丢失)的某几个文件,不关心文件的内容,仅通过文件系统的元数据进行分析和恢复。元数据是一个文件系统的管理信息,一般不以用户文件为载体,通常只能通过底层块的二进制流进行获取和分析。
文件系统中,对文件的寻址大致是这样一个流程,每个文件系统在本文讨论的范围,几乎都不例外。
?图2 文件寻址链
“节点”表述一个文件(或目录)的摘要信息,也包括指向下一层数据单元的指针,下一层数据单元指一个或多个指向,可能是一些附加信息,但肯定会指出“数据块索引”。
“数据块索引”是指指向真正数据区的指针信息。
“数据块”就是数据本身。
除非在SSD等介质上启用TRIM通知硬盘清除数据,否则为了效率,删除数据,并不会清除数据区,只会打上可重用的标签,这是文件恢复的原理所在。
重点1:删除文件恢复的第一个有可能特别好用的方法是lsof。
Linux系统中使用rm -rf删除文件后,其实文件节点只是从目录树中移除,文件内容还是在系统后台等待回收,此时有机会使用系统进程号将文件拷贝出来。
# lsof |grep data.file1
??# cp /proc/xxx/xxx/xx ?/dir/data.file1
这个方法和我的专业关系不大,详情查google。
如果lsof找不出来,那就可以考虑从文件系统角度进行删除恢复了。
按恢复的方法,文件系统大致分为三类:
I类:
UFS(Solaris、BSD等使用),Ext2/3/4(Linux最通用的文件系统),JFS(Aix最早使用),OCFS1/2,HTFS(SCO)。
这类文件系统,使用固定的节点长度,和固定的节点区域。文件系统上的所有文件(或目录)都会在节点表中有唯一一个编录对应,用来做寻址文件的起点。这类文件系统在删除文件时,一般会将节点进行清0操作(因为节点编号和位置是物理上固定的,删除文件后必须可以重用,节点区操作也较为集中和频繁,一般设计时会在删除时顺手清0),清0后,节点到数据块索引之间的纽带就断开了,原本一对一的映射关系,变成了N对N,N是文件总数。
所以,这类文件系统在删除文件后恢复时,往往名称和目录对应较为困难,像医院的PACS、OA、邮件系统、语音库、地质采样、多媒体素材,也包括数据库文件等的对应。(插播广告:我们,也就是北亚数据恢复中心,www.frombyte.com,视钱如命,这种没人做的活,我们接)。
特殊地,一些linux上的开源数据恢复软件,ext3grep之类的,为何能恢复Ext3/4上删除的文件呢?
是因为,Ext3/4文件系统支持日志回滚,系统会在格式化时创立一个日志文件(用户不可见),典型的大小有32M~128M之间,在删除文件时,节点会先行复制到日志文件中,再进行删除,以确保操作意外中断时,可回到上一个干净的稳定状态。
但缺点也显而易见,日志是不断循环回滚的,如果时间太久,或文件系统操作频繁,就没那么容易了。典型地,如果删除大量文件,靠这个方法,只能恢复一部分。
当然,可以再给一计了。重点2:删除后,如果lsof搞不定,有可能的话,第一时间dd文件系统进行归档保护。别以为不断地ls,find会有奇迹出现,会雪上加霜的。
II类:
XFS、ReiserFS、JFS2(for AIX)、ZFS、NetApp WALF、EMC Isilon、StorNext、NTFS。
这类文件系统,节点区域为可变区域,删除数据时很多时候不会清除数据。
原因大概是:
1、区域可变,节点大小就可以设大一些,清除太浪费性能;
2、区域可变,缓冲区就不一定很好命中,清除节点时只需在位图上做手脚就行了;
3、区域可变,可考虑区域重定向,原区域也就没必要理会了。
节点不做清除,意味着“节点->数据块索引->数据块”的链条不会被打断,自然也就容易恢复数据了。
其实也是有难度的,删除一个文件,必然要表现在文件系统层面释放,所以,可能“节点->数据块索引->数据块”整个链条会成为游离态,也可能象zfs一样,会出现非常多的副本,分拣也会有难度。不同的文件系统,会有很多信息之间存在关联,比如JFS2中索引块会记录上一项、下一项;ZFS会在节点中记录下一项数据的HASH等,根据这些匹配点,就可以匹配、择优找到最恰当的数据恢复起点。因不同的文件系统,有不同的针对性的方法。
III类:其他吧。
比如Vxfs、HFS+结构上像II类,但因为节点区域往往集中在前部,命中率较高,在设计上,删除文件就会做清0或重构树操作,数据恢复的难度又如同I类。
比如ASM,严格来说,也不太像文件系统了,反正结论是文件系统本身没有太好的算法,保证删除后可恢复(但依靠文件内部结构,恢复的可靠性非常高)
比如VMFS,基本是个大块分配的文件系统,恢复方法和方案和本文多有不同,一扯内容有点多,有空专门扯。
上述,是针对完整恢复文件的思路进行描述的,但也如上文所述,有时文件是无法恢复的,也可能文件部分被破坏、覆盖。
如果文件内容都还在,但文件系统元数据部分已经无法支撑对文件信息的还原,那就可以考虑从文件内容的关联性上做文章。
比如Oracle数据文件,多数情况下,按8K为页大小,可喜的是,每一页的头部都有页校验、页编号和可能的文件编号。按页校验从磁盘底层扫描出所有数据页后,统计文件编号和页编号,幸运的话,就可能把文件拼接起来。
Oracle的控制文件会记录数据文件逻辑、物理之间的关联,分析后,文件名称、路径就不难还原了。
同样的方法,可大致适应于Sql Server、MySQL InnoDB。思维稍做变通,可适应Sybase、DB2等。
如果是MySQL MyISAM引擎,也有办法。记录是一行一行依次压入文件中的,如果某个表有主键,或特殊的字段,或特殊的表结构,就能对所有磁盘上符合条件的块进行归类。MyISAM还会有行溢出、行迁移的情况,即存在A指向B的数据关联关系,根据这个关系,也可以进一步匹配块记录的排列逻辑,从而组合数据文件。对于MyISAM,这其实也是恢复表或恢复记录的方法。
这是根据文件内容,恢复完整文件的思路。如果文件内容不完整,或副本太多导致排重难度太大呢?---恢复表或表记录。
根据表与表之间的差异,一般情况下,可以容易对找出的所有可能是数据库的片断进行归类,归类的最直接方案是按表进行。
按表归纳为相同一组单元后,就可以从记录角度进行分拣和排错了,如果可以借助于索引、空间分配、其他关联表等信息,可以容易对恢复的表单元进行数据清洗,幸运的话,数据可能是完整的。
如果表归纳为同一单元后,与索引不对应、有错误记录等,导致数据库无法修复启动,就可以按表结构,对表单元,以记录的方式进行抽取->插入新库->数据定向清洗。虽然结果可能不是完美的,但很多情况下,总比没有强。
还有图1中方法C2,从日志中恢复记录。这个日志是广义的,包括归档、过程性语句表述等一切可能有记录痕迹的数据集。在主数据文件是破坏的情况下,这些任何可能包含记录的数据集,都应该是分析的对象。也如同数据库文件,按文件、结构块、记录的思路进行最大程度的恢复。结合C1、C2、C3,再做定向性的数据集合和数据清洗,数据恢复的手段也就到头了。
忘了聊一句Hadoop了,Hadoop,Hbase在删除时触发的是节点文件系统上的文件删除行为,以最常见的Linux为例,其实就是Ext3/4上删除文件的恢复问题,如果文件恢复不了,再参考Hadoop的HASH、fsimage之类的进行数据块关联。如同上述数据库的思路。
显而易见的是,恢复方法越向后,汇总的生产数据问题越多,数据逻辑的排查和纠正将会让太多人夜不能寐,咬牙切齿,这时候,可能跑路都会被大家堵回来。得,还是乖乖地给大家买咖啡,向老板贡献全年工资和资金,装着蓬头垢面、愁眉不展的样子吧,兴许大家还能答应每天让你睡上2个小时。
以上是关于从删库到恢复到跑不了路-数据恢复工程师解说顺丰删库事件的主要内容,如果未能解决你的问题,请参考以下文章