MySQL 从删库到跑路
Posted 老王不掉头发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 从删库到跑路相关的知识,希望对你有一定的参考价值。
技术事简单报,看老王带你入门mysql,从删库到跑路
本篇文章适用于大学学习MySQL的入门同学,理解不深,欢迎交流
目录
limit是mysql特有的,其他数据库中没有,不通用。(Oracle中有一个相同的机制rownum)
12、DQL(select)DML(insert delete update)
和事务相关的语句只有:DML语句。(insert delete update)
对视图进行怎删改查,会影响原表数据。(通过视图影响原表数据的,不是直接操作的原表)
一.认识SQL语句
老王刚上大学的时候,SQL语句属实是给老王的心里留下了不小的阴影,各种多表联查各种join属实是给老王整不会了,接下来,老王就用自己的理解,带着大家逐步的了解SQL语句
1)什么是SQL语句,什么是表?
老规矩,看看度娘你会发现你什么都没看懂,通俗的来说,你可以把SQL语句当成数据库的各个管家,有查询的,有删除(删库)的等等,你需要他们做事情的时候,只需要通过一些逻辑的设定,从而达到操纵数据库的效果。
提到数据库,不得不提到一个重要的东西,表
什么是表?别问老王,看图说话
在数据库中,表即为table ,table是数据库的基本组成单元,所有的数据都用表格的方式呈现给我们,说白了就是方便看
一个合格成熟的数据库里全是表,那么一个成熟的表里有什么?
行:被称为数据/记录(data)
列:被称为字段(column)也可以记作列名
每一个字段应该包括那些属性?
字段名、数据类型、相关的约束(后续说,字面意思就是约束这一行,例如这一行只能写文字或者数字,后续老王会给大家详细的解释什么是约束)
2)SQL语句的分类
在SQL语句中,所有的SQL语句分为五大类
DQL(数据查询语言):查询语句,凡是select语句都是DQL
DML(数据操作语言):insert delete update,对表中的数据进行增删改
DDL(数据定义语言):create drop alter,对表结构的增删改
TCL(事务控制语言):commit提交事务,rollback回滚事务。(T:transaction)
DCL(数据控制语言):grant授权、revoke撤销权限等
老王没记住过,都是考试背的,在老王的印象中,SQL类型就是增删改查
既然是为了给广大大学生的考试秘籍,就不得不提到MySQL的机制了(划重点,必考)
DB,DBMS,SQL之间的关系
DB: Database(数据库,数据库实际上在硬盘上以文件的形式存在)
DBMS:Database Management System (数据库管理系统,常见的有:MySQL Oracle DB2...)
SQL:结构化查询语言,是一门标准通用的语言,标准的SQL适合于所有的数据库产品
SQL属于高级语言,只要能看懂英语单词写出来的SQL语句,可以读懂什么意思,SQL在执行的时候,实际上内部也会先进行编译,然后再执行SQL,编译由DBMS完成
关系:DBMS——(执行)——》SQL——(操作)——》DB
划重点,这个要考,也是MySQL的跑码的顺序,也是学习数据库的根本,简而言之DBMS负责执行SQL语句,通过执行SQL语句来操作DB中的数据 。
二.了解MySQL
1)通过CMD访问MySQL
在电脑装好MySQL数据库之后(百度,切记别点错,依稀想起被数据库卸载支配的恐惧), 按下电脑的windows键+R,打开运行,输入cmd即可进入黑窗口。

这就是黑窗口,在黑窗口中,我们可以通过一个简单的语句访问MySQL
mysql -uroot -p
Enter password:password后面就是自己设置的Mysql密码,数据即可(记得-p后面按下回车,这样密码就可以像上面代码块一样隐藏起来)
当你进入看到Welcome to the MySQL monitor.这句话的时候,说明你的Mysql已经安装成功了,这个时候我们就可以用黑窗口完成一系列的SQL语句
常用的语句
查看有哪些数据库
show databases;(这个不是sql语句,属于 mysql的命令)
创建属于我们自己的数据库
create database 数据库名
进入数据库
use 数据库名;(这个不是sql语句,属于mysql的命令。)
查看当前使用的数据库中有那些表?
show tables;
导入sql文件(文件以sql结尾,这样的文件被称为“sql脚本”。 什么是sql脚本呢?
当一个文件的扩展名是.sql,并且该文件中编写了大量的sql语句,我们称这样的文件为sql脚本。
注意:直接使用source命令可以执行sql脚本。
sql脚本中的数据量太大时,无法打开,请使用source命令完成初始化。)
source sql文件绝对路径
删除数据库:drop database 需要删除的数据库名字;
查看表结构:desc dept;
表中的数据 :select * from emp;(查看表中的数据)
mysql> select databases; 查看当前使用的是哪个数据库
mysql> select version(); 查看mysql的版本号
\\C 命令结束一条语句
exit 退出mysql
注意奥:SQL语句是不区分大小写的,但是建议还是规范书写,因为你永远不知道在后面的JavaWeb中,你的不规范命名和书写会带来多大的麻烦(老王的亲身体会)
三.SQL查询语句
在SQL语句中,查询语句是最难的,因为有N多的表等你拼接,绝对不要把查询想得太简单,但是当你发现查询的奥妙,你会觉得这玩意跟数独一样有意思
1)简单的查询语句
注:sql语句不区分大小写。粗体均为关键字,其余为查询或需要处理的名字;
语法格式:
select 字段名1,字段名2,。。。 from 表名;注意,在SQL语句中, 任何一条sql语句以“;” 结尾。不然你会发现一个尴尬的事情
老王当年因此以为电脑坏了来着。学习编程的时候,你要把CMD当成傻子,你不告诉它该我写完了该执行了就会出现这么尴尬的事情
2)简单查询
在练习查询语句之前,先给大家看一下老王练习SQL语句的表
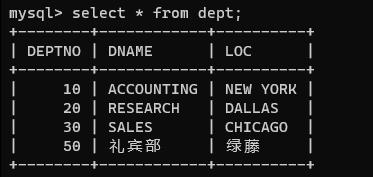
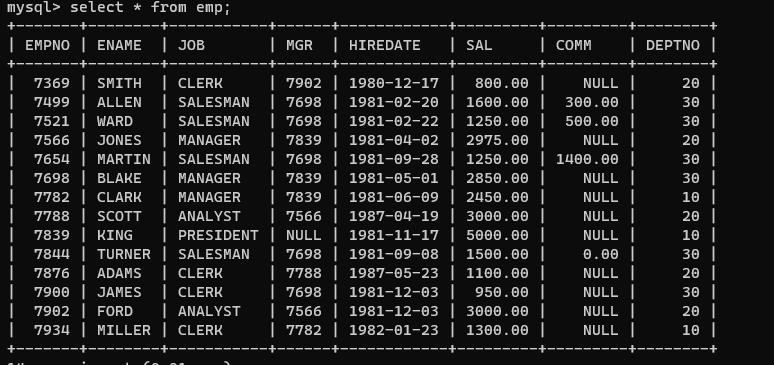
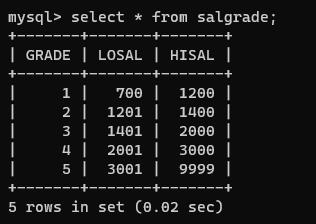
英语好的同学们请自行翻译并创建表格进行练习,有了这些表,就可以通过上面简单的查询语法做到一些简单的题目
例如:分别查询三个表格
查询salgrade表
select * from salgrade;
查询emp表
select * from emp;
查询dept表
select * from dept;3) 重命名查询结果的列
select xx更改前x as xx更改后x from emp;
select xx更改前x xx更改后x from emp;(as关键字可以省略)
注:MySQL中可以使用中文作为列的名称,例如年薪,在用中文更改名称时,强调给字符加单引号,双引号也可以通过编译并使用,但仅限于MySQL,Oracle 及其其他数据库中不承认双引号修饰的字符。
4)查询全部字段
select * from 表名;(*表示全部)
实际开发中不建议使用*,效率很低。
5)条件查询
语法格式:
select 字段,字段.. from 表名 where 条件;
执行顺序:先from,然后where,最后select
先给大家解析一下,SQL语句中有什么逻辑条件;
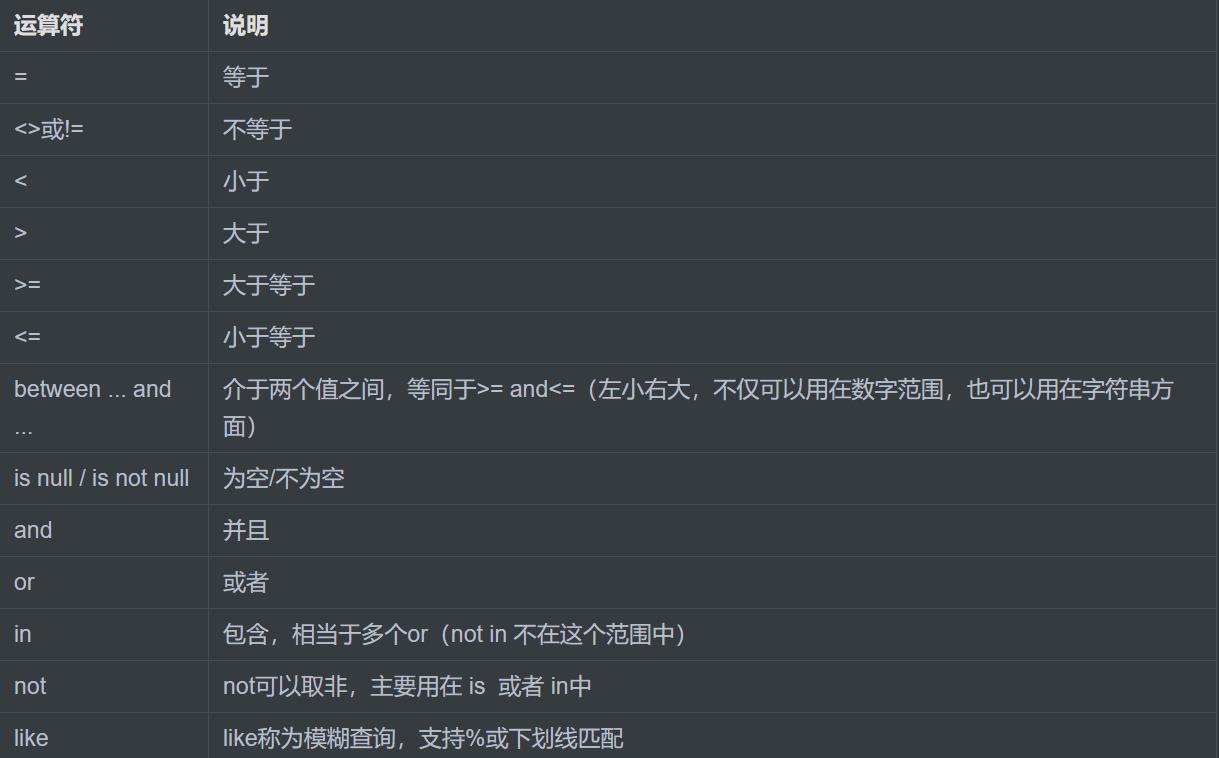
6)between
查询数据范围:select sal from emp where between 1000 and 3000;
也可以用作字符串方面
查询字符串的开头:select name from emp where between 'A' and 'B' ;
左闭右开,查询字符串开头
7)and 与 or 的优先级问题
例如 找出 工作岗是AAA以及BBB的员工
select ename,job from emp where job = 'manager' or job = 'salesman';
and 永远被翻译为 并且 ,or 永远被翻译为 或者
and与or 联合使用的例:找出薪资大于一千并且部门编号是20或30部门的员工
select name,jobId ,sal from emp where sal>1000 and (jobId = 20 or jobId =30);
加括号,小心乱套,不加?小心他给你查询工资大于100或者id=20的(离谱的优先级),容我吐槽这个优先级就很迷,四舍五入就是从左往右运行,所以,在这种参杂着and or 的逻辑运算的时候,亲,建议您加括号叭!
8)in与or
例:找出工作岗位是AAA和BBB的员工
select ename,job from emp where job='AAA' or job='BBB';
当然他不只一种写法,这玩意都给你CV下来了,肯定有意义
select ename,job from emp where job in ('AAA','BBB');
你看看这个or,是不是事儿贼多,他俩效率没有区别,但是我更喜欢第二种,可读性更好一点点
注意奥,in后面的每一项,都是一个值,不是区间,例如下面这玩意
select ename , job from emp where sal in(1000,5000);
这玩意要找的是,1000块和5000块,这可不是1000-5000,就离谱;
9)模糊查询like
重点来了,like 就离谱
在这里面,你需要搞明白两个特殊的符号 第一个是% 第二个是_(像极了正则表达式)
%:任意多个字符 ; _ : 任意一个字符;
例:找出名字所有姓张的员工;
select ename from emp like '张%';
例:找出第二个字母是A的员工;
select ename from emp like '_A%';
例:(过分的来了,就离谱)找出名字里有下划线的;
select ename from emp like '%\\ _%';
这世界上有个东西叫转义符,只需要在前面打一个捺斜杠就完事了(\\);
10)数据排序:
升序,降序,例如,按照工资的升序排序
select enamel,sal from emp order by sal;
在没有指定升降的情况下, 关键字order by 默认升序排序,asc表示升序,desc表示降序,那么如果我想降序或升序,就变成了这样;
select enamel,sal from emp order by sal asc;//升序
select enamel,sal from emp order by sal desc;//降序
那么问题来了,按照工资的升序排列,当工资相同的时候,再按名字的升序排列;怎么做?
select enamel,sal from emp order by sal desc,ename asc;
我也不知道语法怎么规定的,但是这个逗号后面的原理,大概就是从左到右,越靠右越弟弟。当前面的字段相等(无法排序),后面这个弟弟才会启用,相当于是个备胎;啥也不是;
11)分组函数
分组函数还有另外一个名字:多行处理函数;
特点:输入多行,最终输出的结果为一行,自动忽略null;
注意:分组函数不能直接卸载where后面,会报错;
但是可以嵌套,至于为什么,这部分,往下看,会有的;
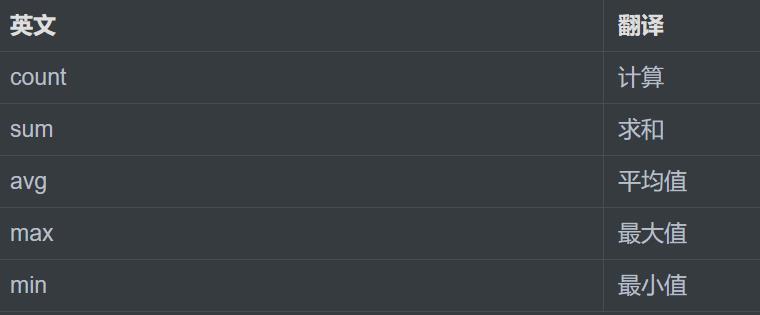
所有分组求和的函数都是对某一组的数据进行操作
找出工资总和:select sum(sal) from emp;
找出最高工资: select max(sal) from emp;
找出平均工资:select avg(sal) from emp;
找出平均人数:select count(ename)from emp;
......
分组函数也可以组合起来用;
例如:
select count(*),sum*(*) from emp;
12) count
count(*)和count(具体的某个字段),他们有什么区别?
count(*):不是统计某个字段的个数;统计的一定是总记录条数;
而count(comm):表示统计comm不为NULL的数据总数量;
13)group by和having
group by:按照某些字段或者某个字段进行分组;
having: 对分组之后的数据进行再次过滤;
案例:找出每个工作岗位(job)的最高薪资(sal)。
select max(sal) from emp group by job;
注意:分组函数一般都会和group by联合使用,任何一个分组函数(max min count)都是在group by语句执行完才会执行,当一条select里面没有group by的时候,整张表的数据会自成一组。
多字段能不能联合起来一块分组?
例:找出每个部门(deptno),不同工作岗位(job),的最高薪资(max(sal));
句子都断好了,这个怎么写?
select deptno,job,max(sal) from emp group by deptno,job;
例:找出每个部门(deptno)的最高薪资,要求显示最高薪资大于2500的
select max(sal),deptno from emp group by deptno having max(sal)>2900;
👆虽然这种用法效率低,但是胜在思路清晰,没毛病,好用就行了;
14)单行处理函数
什么是单行处理函数? 输入一行,输出一行。
计算每个员工的年薪?(工资+补助X12=年薪)
select ename,(sal+comm)*12 as yearsal from emp;
但是,如果工资和年薪,有一个是空值,那么他的年薪可就变成null了;
那么重点来了,所有数据库都是这样规定的,只要有NULL参与的运算结果一定是NULL;
ifnull() 空处理函数
语法:ifnull(可能为Null的数据,当作什么看);
那么计算员工的年薪,为了保证不出NULL ,就变成了
select ename,(sal+ifnull(comm,0))*12 as yearsal from emp;
练习以及答案:
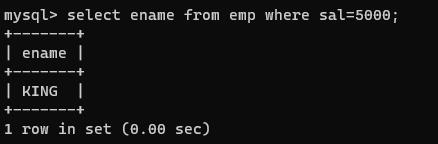
查询员工工资等于5000的姓名?
select ename from emp where sal=5000;
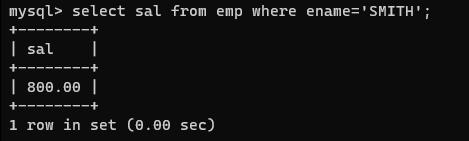
查询SMITH的工资?
select sal from emp where ename='SMITH';
找出工资高于3000的员工?
select ename,sal from emp where sal>3000;
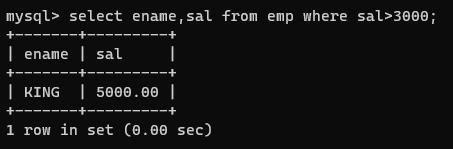
找出工资不等于3000的?
select ename,sal from emp where sal <> 3000;
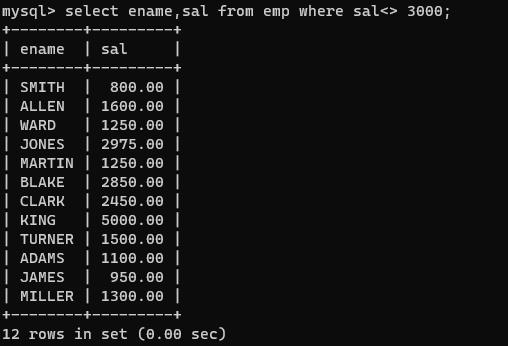
找出工资在1100和3000的员工,包括110和3000?
select ename,sal from emp where sal >=1100 and sal<=3000;
//between...and...是闭区间【1100,3000】
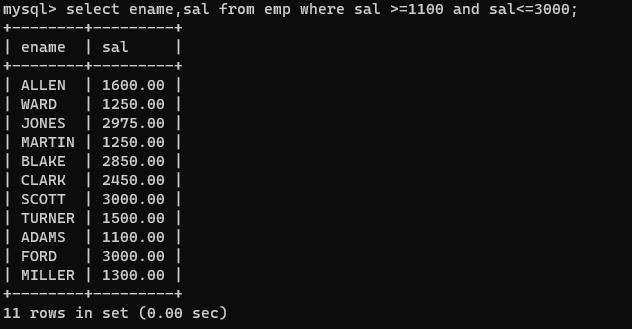
也可以写成
select ename,sal from emp where sal between 1100 and 3000
注意:between ...and... 为XX到XX之间,老王英语不好,理解这个直接理解为[1100,3000]闭区间了。
15)关于查询结果去重
啥玩意?去重不用说了吧,语法如下(关键字 distinct):
select distinct job from emp;
distinct 只能出现在所有字段的最前面! 别出BUG了;
例:统计岗位的数量?
select count(distinct job) from emp;
套娃警告!
sql语句执行顺序
一个完整的查询语句语句 怎么写?
select 5
...
from 1
...
where 2
...
group by 3
...
having 4
...
order by 6
...
后面的小数字,就是所谓的执行顺序,语法顺序不能乱,后面的数字是语句的执行顺序
而在前面提到的,where后面为什么不能使用max等函数,就是因为执行顺序的原因,在where后还没有调用group等分组函数,所以无法使用
四.连接查询
1.连接查询
1.1什么是连接查询?
在实际开发中,大部分情况下,都不是从单表中查询数据,一般都是在多张表联合查询取出最终的结果。实际中,一般一个业务都会对应多张表,比如:学生和班级两张表
1.2 连接查询的分类?
根据语法出现的年代来划分,包括:
SQL 92(老龄化DBA可能还在用,DBA:数据库管理员,反正我不懂);
SQL 99(比较新的语法,吐槽20年前的语言);
根据表的连接方式划分,包括:
内连接:等值连接,非等值连接,自连接;
外连接:左外连接,右外连接;
全连接(很少用)
1.3 笛卡尔乘积现象
笛卡尔发现的,别问,不懂
案例:找出每一个员工的部门名称,要求显示员工名和部门名
//两个表在一起,需要从一个表取员工名字,另一个表取部门名称 select ename,dname from emp,dept; //👆这个是错的奥。但是这个叫笛卡尔乘积现象 他会把员工表的每个人,和部门表相匹配,相当于 一个SMTIH 一个人跑了四次部门表的查询,如果在查询中,没有任何限制的话,那么查询结果条数将会是两张表的乘积,这个现象就叫笛卡尔乘积现象。四舍五入在还数学的债 //结果就这样的👇
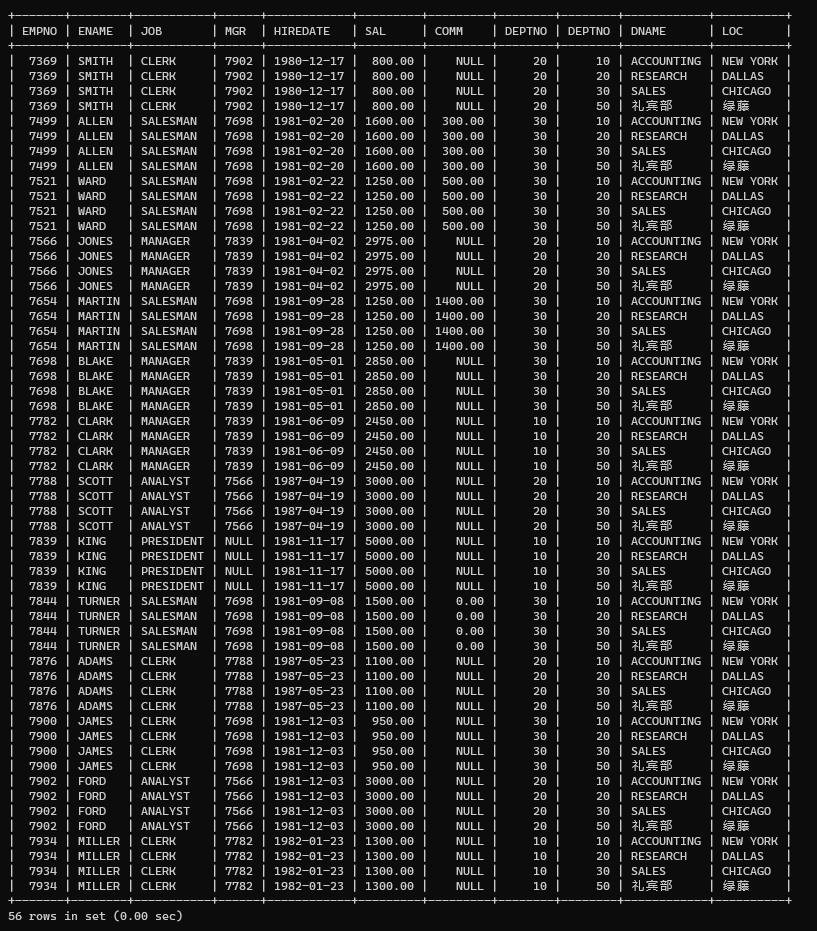
插入:关于表的别名:
select e.name,d.dname from emp e,dept d;
执行效率高,可读性好(以后起别名,效率高省内存);
言归正传,那么问题来了,怎么避免笛卡尔积现象呢?
加条件进行限制!!
//既然一起显示,就意味着两个表的部分要连在一起,那么:
select
e.ename,d.dname
from
emp e,dept d
where //判定条件,避免了笛卡尔积现象
e.deptno=d.deptno;
白学,上面这些这个以后不用,经典的92语法(滑稽),但是,这个是原理。
2.内连接
2.1 内连接中的等值连接
最大的特点:条件是等量关系。
案例:查询每个员工的部门名称,要求显示员工名和部门名;
//SQL92语法:
select
e.ename,d.dname
from
emp e,dept d
where
e.deptno=d.deptno;
问题是92 现在都不用,老了终归是老了
//SQL99:
select
e.ename,d.dname
from
emp e
join
dept d
on
e.deptno=d.deptno; //由于连接关系是等值,所以叫等值连接
join...on 语法: 表A join 表B on 连接条件 ;(后面还可以跟where)
SQL99语法 结构更加清晰,表的连接条件和后面的where条件分离开了
2.2 内连接的非等值连接
最大的特点:连接条件中的关系是非等量关系;
案例:找出每个员工的工资等级,要求显示员工名字,工资,工资等级
select
e.name,e.sal,s.grade
from
emp e
join
salfrade s
on
e.sal between s.losal and s.hisal;
2.3 内连接中的自连接
最大特点:一张表看作两张表,自己连自己
案例,找出每个员工的上级领导,要求显示员工名和对应的领导名。
员工表 empa:
//自连接
select
a.ename,b.ename
from
empa a
join
empa b
on
a.empno = b.mgr;
3.外连接
什么是外连接?他和内连接有什么区别?
内连接:假设A和B表进行连接,使用内连接,凡是A表和B表能匹配的记录查询出来,这就是内连接,AB两个表没有主副之分,两张表是平等的;
外连接:假设A和B表进行连接,使用外连接的话,AB两张表有一张是主,一张是副,主要查询主表,捎带查询副表,当副表中的数据没有和主表中的数据匹配上,附表自动模拟出Null与之匹配;
3.1外连接的分类
左外连接:左边的是主表
右外连接:右边的是主表
任何一个左(右)外连接都有一个右(左)外连接的写法;
XXX left join XXX on xxxxxx;
这个就是左外连接,左边为主表👆,副表匹配不上,会自己创造一个NULL塞到主表;
XXX right join XXX on xxxxxx;
这个就是右边为主表;
外连接最重要的特点是:主表的数据无条件的全部查询出来。比如有的表里无数据,副表没有查到相应的数据,内连接就会直接把这行删掉不要,而外连接会在上面匹配一个null,不会不显示主表当前行
2.9、三张表怎么连接查询?
案例:找出每一个员工的部门名称以及工资等级。
注意,解释一下:
A
join
B
join
C
on
表示:A表和B表先进行表连接,连接之后A表继续和C表进行连接 on后写匹配条件。
select
e.ename,d.dname,s.grade
from
emp e
join
dept d
on
e.deptno=d.deptno
join
salgrade s
on
e.sal between s.losal and s.hisal;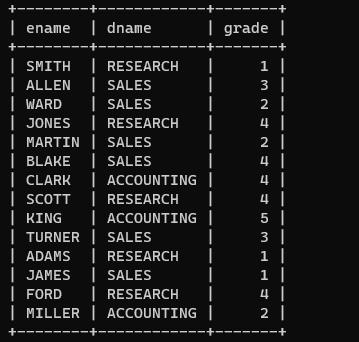
案例:找出每一个员工的部门名称、工资等级、以及上级领导。
方法一:
select
e.ename,d.dname,s.grade
from
emp e
join
dept d
on
e.deptno=d.deptno
join
salgrade s
on
e.sal between s.losal and s.hisal
left join
emp e1
on
e.mgr=e1.empno;方法二:
select e.ename,d.dname,s.grade,q.ename
from emp e
join dept d
on e.deptno=d.deptno
join salgrade s
on e.sal between s.losal and s.hisal
join emp q
on
e.mgr=q.empno
Order by s.grade;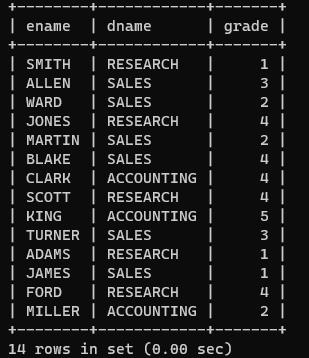
3、子查询
3.1、什么是子查询?子查询都可以出现在哪里?
select语句当中嵌套select语句,被嵌套的select语句是子查询。
子查询可以出现在哪里?
select
..(select)
From
..(select)
where
..(select)
3.2、where子句当中使用子查询
案例:找出高于平均薪资的员工信息。
select *from emp where sal>avg(sal) //错误,因为where后面不能跟avg函数
第一步:找出平均薪资
select avg(sal) from emp;
第二步:where 过滤
select * from emp where sal>2073;
第一步和第二步合并:
select *from emp where sal>(select avg(sal) from emp);
3.3、from后面嵌套子查询
案例:找出每个部门平均薪水的薪水等级
第一步:找出每个部门的平均薪水(按照部门编号分组,求sal的平均值)
select deptno ,avg(sal) as avgsal from emp group by deptno;
第二步:将以上的查询结果当做临时表t,让t表和salgrade s 表连接诶,条件是:t.avgral between
s.losal and s.histol;
select
t.*,s.grade
from
(select deptno ,avg(sal) as avgsal from emp group by deptno )t
join
salgrade s
on
t.avgsal between s.losal and s.hisal;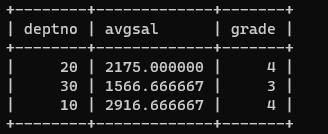
3.4、在select后面嵌套子查询。
案例:找出每个员工所在的部门名称,要求显示员工名和部门名。
select
e.ename,d.dname
以上是关于MySQL 从删库到跑路的主要内容,如果未能解决你的问题,请参考以下文章