R语言社区主题检测算法应用
Posted tecdat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言社区主题检测算法应用相关的知识,希望对你有一定的参考价值。
使用R检测相关主题的社区
创建主题网络
对于Project Mosaic,我正在通过分析抽象文本和共同作者社交网络来研究UNCC在社会科学和计算机和信息学方面的出版物。
我遇到的一个问题是:如何衡量主题之间的关系(相关性)?特别是,我想创建一个连接类似主题的网络可视化,并帮助用户更轻松地浏览大量主题(在本例中为100个主题)。
在本教程中,我通过组合来自两个非常棒的资源的代码来实现这一目标:
- Tyler Rinker的主题建模回购(参见“关于主题的词语分布的网络”)
- Katherine Ognyanova的网络可视化教程。
数据准备
我们的第一步是加载作为LDA输出的主题矩阵。LDA有两个输出:字主题矩阵和文档主题矩阵。在本教程中,我上传了以前保存为平面(csv)文件的已保存LDA结果。
作为加载平面文件的替代方法,您可以使用topicmodels包lda函数的输出来创建任何单词主题和文档主题矩阵。获取函数的输出并在输出上lda运行该posterior函数。
# load in author-topic matrix, first column is word
author.topic <- read.csv("./author_topics.csv", stringsAsFactors = F)
# load in word-topic matrix, first column is word
top.words <- word.topics[order(-word.topic[,i])]
name$topic_name[i] <- paste(top.words[1:5], collapse = " + ")
}
# rename topics
colnames(author.topic) <- c("author_name",name$topic_name)
与摘要是文档的标准LDA不同,我运行了一个“以作者为中心”的LDA,其中所有作者的摘要被合并并被视为每个作者的一个文档。我跑这是因为我的最终目标是使用主题建模作为信息检索过程来确定研究人员的专业知识。
创建静态网络
在下一步中,我使用每个主题的单词概率之间的相关性创建一个网络。
首先,我决定只保留具有显着相关性(20%+相关性)的关系(边缘)。我使用20%,因为它对于100个观察维基百科的样本具有0.05的统计显着性水平。
cor_threshold <- .2
接下来,我们使用相关矩阵来创建igraph数据结构,删除所有具有小于20%最小阈值相关性的边。
library(igraph)
让我们绘制一个简单的igraph网络。
par(mar=c(0, 0, 3, 0))
y30")
title("Strength Between Topics Based On Word Probabilities", cex.main=.8)

每个数字代表一个主题,每个主题都有编号以识别它。
我的第一个观察是,似乎有三个主要的集群。
让我们使用社区检测,特别是igraph中的标签传播算法来确定网络中的群集。
clp <- cluster_label_prop(graph)
class(clp)
title("Community Detection in Topic Network", cex.main=.8)
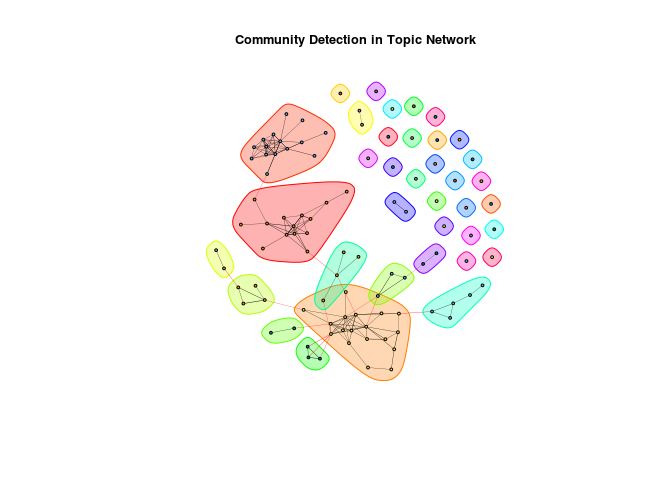
社区检测发现了13个社区,以及每个孤立主题的多个额外社区(即没有任何联系的主题)。
与我最初的观察结果类似,该算法找到了我们在第一个图中识别的三个主要聚类,但也添加了其他较小的聚类,这些聚类似乎不适合三个主要聚类中的任何一个。
让我们保存我们的社区,并计算我们将在下一部分使用的学位中心性和中介性。
V(graph)$community <- clp$membership
V(graph)$degree <- degree(graph, v = V(graph))
动态可视化
在本节中,我们将使用visNetwork允许R中的交互式网络图的包。
首先,让我们调用库并运行visIgraph一个交互式网络,但是使用igraph图形设置在igraph结构(图形)上运行。
library(visNetwork)
这是一个良好的开端,但我们需要有关网络的更多详细信息。
让我们通过创建visNetwork数据结构走另一条路。为此,我们将igraph结构转换为visNetwork数据结构,然后将列表分成两个数据帧:节点和边缘。
data <- toVisNetworkData(graph)
nodes <- data[[1]]
删除没有连接的节点(主题)(度= 0)。
nodes <- nodes[nodes$degree != 0,]
让我们添加颜色和其他网络参数来改善我们的网络。
library(RColorBrewer)
col <- brewer.pal(12, "Set3")[as.factor(nodes$community)]
nodes$shape <- "dot"
s$betweenness))+.2)*20 # Node size
nodes$color.highlight.background <- "orange"
最后,让我们用交互式情节创建我们的网络。您可以使用鼠标滚轮进行缩放。
visNetwork(nodes, edges) %>%
visOptions(highlightNearest = TRUE, selectedBy = "community", nodesIdSelection = TRUE)
按ID选择
学生+规模+项目+有效性+过程
糖尿病+卡罗莱纳州+北卡罗来纳州+教育+北方
教师+数学+学校+小学+学生
地位+女性+性别+个人+理论
数据+跟踪+动作+分类+视频
物种+数据+序列+病例+遗传
学生+学校+学校+干+成就
victimization + criminal + victims + rates + violence
older + aging + adults + successful + older_adults
joint + control + controls + balance + lateral
protein + flexibility + properties + structure + families
security + system + configuration + attacks + smart
mobile + information + application + search + data
genes + gene + expression + genetic + genome
energy + intervention + data + hypertension + dietary
health + patients + hospitals + racial + rate
providers + work + care + hiv + violence
health + ability + cognitive + outcomes + factors
power + users + information + user + systems
spatial + urban + location + geographic + information
public + organizations + data + evaluation + program
framework + image + images + retrieval + features
data + systems + problem + scheme + key
women + ci + pregnancy + health + odds
visual + data + problem + analytics + events
students + instruction + disabilities + skills + literacy
image + images + visual + algorithm + object
health + care + smoking + current + data
technology + teacher + learning + teachers + chapter
systems + agents + complex + agent + control
routing + network + networks + topology + nodes
social + issues + gender + challenges + perceptions
knowledge + software + management + important + effective
members + team + virtual + teams + diversity
health + care + community + primary + primary_care
network + networks + addresses + techniques + novel
images + flow + image + building + tracking
stress + exercise + function. + age + n
health + women + care + cognitive + united
meetings + meeting + organizational + work + job
reading + schools + implementation + behavior + academic
continuum + objects + robot + object + motion
data + plans + finally + online + plan
workplace + organizational + work + temporal + workers
students + learning + course + computing + student
transition + practices + program + students + evidence.based
attacks + security + system + mechanism + protocol
urban + charlotte + economic + cities + areas
security + developers + vulnerabilities + software + secure
health + children + care + areas + florida
virtual + environment + children + technique + user
genomes + binding + genes + sites + similar
early + development + literacy + professional + childhood
structural + binding + tranion + protein + structures
agents + navigation + game + data + world
visualization + time + data + network + security
users + policy + user + access + social
data + time + factors + provide + variables
design + data + understanding + process + issues
information + risk + real + process + social
game + students + games + educational + student
health + physical + older + african + americans
firms + value + financial + information + accounting
public + environmental + commitment + values + industry
students + intervention + alcohol + college + drinking
development + housing + prices + economic + offers
novel + insight + visual + evaluation + text
land + data + urban + lidar + spatial
graph + privacy + database + social + theoretical
spatial + parallel + computing + modeling + data
youth + services + children + child + family
activity + physical + physical_activity + running + strains
patients + patient + costs + care + outcomes
genes + splicing + alternative + rna.seq + gene
data + values + applied + peak + mass
array + expression + microarray + de + probe
Select by community
首先,请注意有两个下拉菜单。第一个下拉列表允许您按名称查找任何主题(按单词概率排名前五个单词)。
第二个下拉列表突出显示了我们算法中检测到的社区。玩这个菜单。使用主题名称(使用鼠标滚动放大),您能解释主题社区似乎是什么吗?
最大的三个似乎是:
- 计算(灰色,簇4)
- 社交(绿蓝,群集1)
- 健康(黄色,群集2)
检测到的较小社区有什么独特之处?你能解释一下吗?
最后,泡沫的大小基于网络(中心)度量中介。这可以衡量该节点对整个网络连接的重要性。在此示例中,较大的节点具有较高的中介性,这意味着主题在跨主题群集时更为重要。
哪个是最大的节点?这些主题是保持网络连接的“粘合剂”。什么resesarch概念可能会将这些主题与社区之外的主题联系起来?
以上是关于R语言社区主题检测算法应用的主要内容,如果未能解决你的问题,请参考以下文章
检测算法简介及其原理——fast R-CNN,faster R-CNN,YOLO,SSD,YOLOv2,YOLOv3