MySQL数据同步到ES集群(MySQL数据库与ElasticSearch全文检索的同步)
Posted 延锋L
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL数据同步到ES集群(MySQL数据库与ElasticSearch全文检索的同步)相关的知识,希望对你有一定的参考价值。
简介:mysql数据库与ElasticSearch全文检索的同步,通过binlog的设置对MySQL数据库操作的日志进行记录,利用Python模块对日志进行操作,再利用kafka的生产者消费者模式进行订阅,最终实现MySQL与ElasticSearch间数据的同步。
视频地址:
- mysql与elasticsearch同步1-数据库binlog的设置及python读取
- mysql与elasticsearch同步2-kafka生产者消费者模式消费binlog
- mysql与elasticsearch同步3-elasticsearch的增删改同步数据库
博客地址:
目录
P01-数据库binlog的设置及python读取
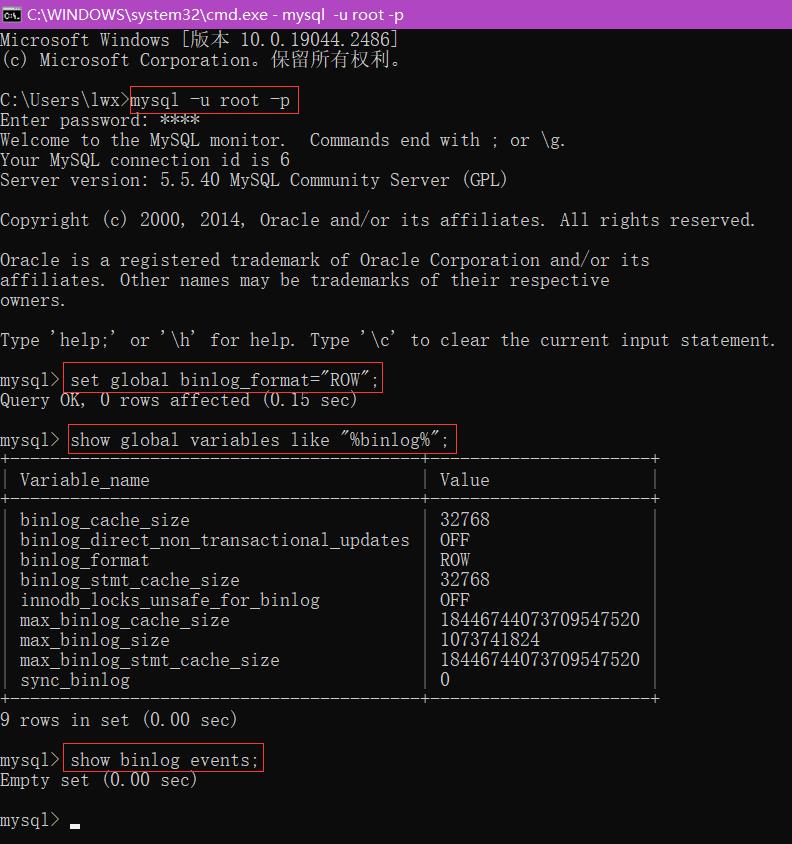
mysql -u root -p
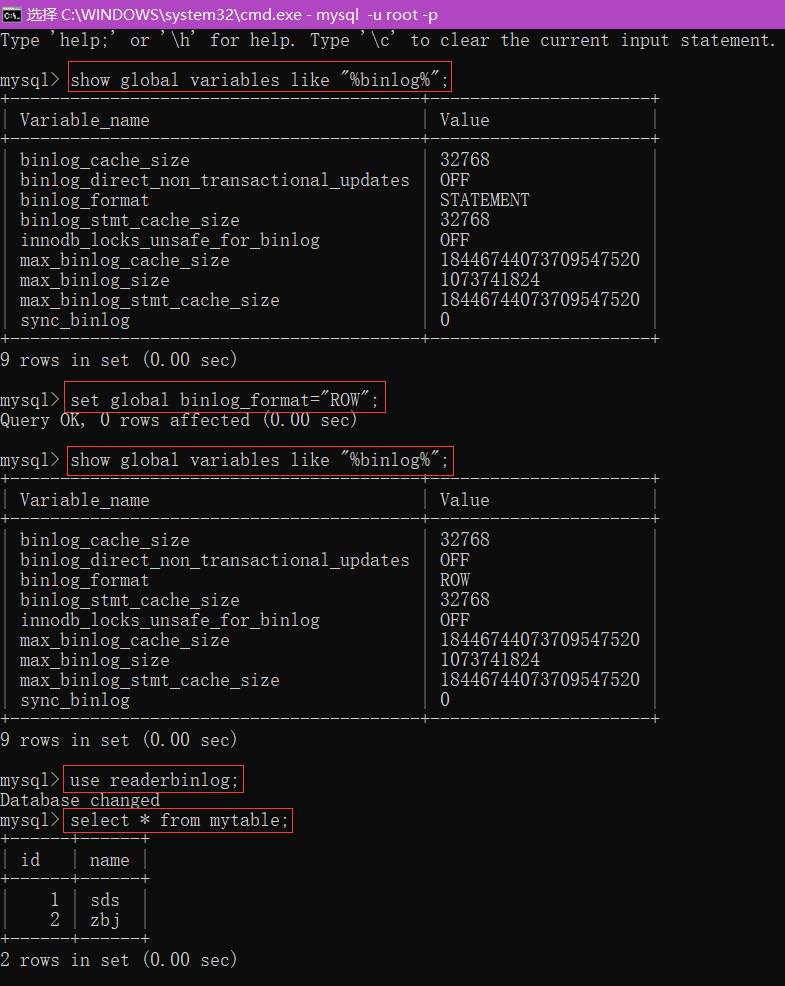
show global variables like "%binlog%";
show binlog events;
set global binlog_format="ROW";
create database readerBinlog default charset=utf8;
use readerBinlog;
create table mytable(id int(11), name varchar(20));
insert into table mytable values(1, "孙大圣");
mysql> use readerbinlog;
Database changed
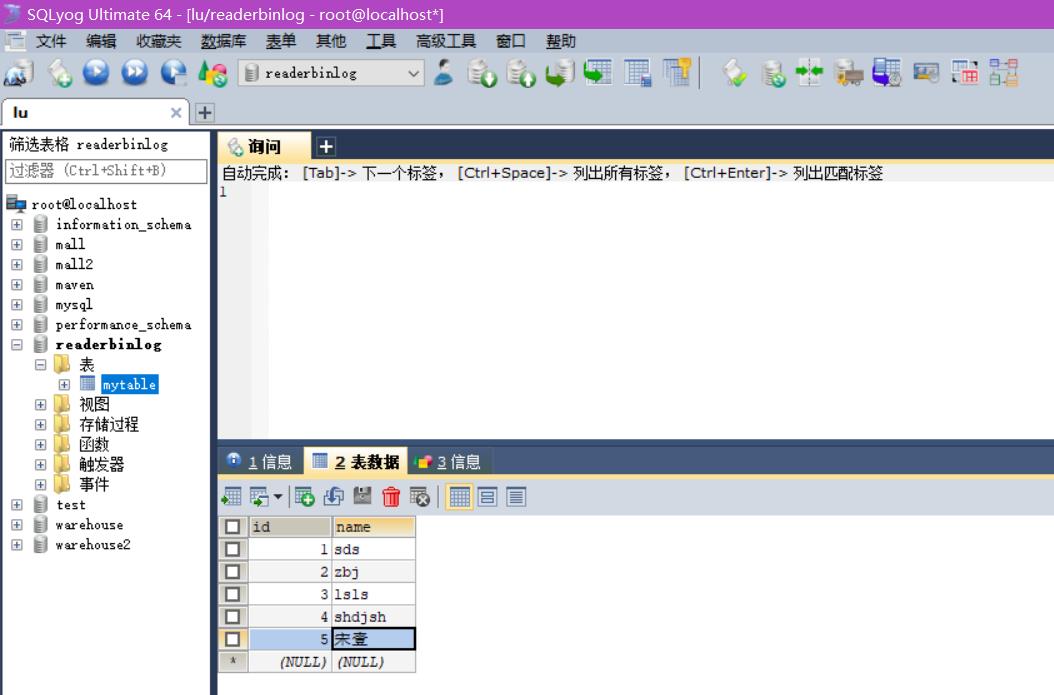
mysql> select * from mytable;
+------+------+
| id | name |
+------+------+
| 1 | sds |
| 2 | zbj |
+------+------+
2 rows in set (0.00 sec)
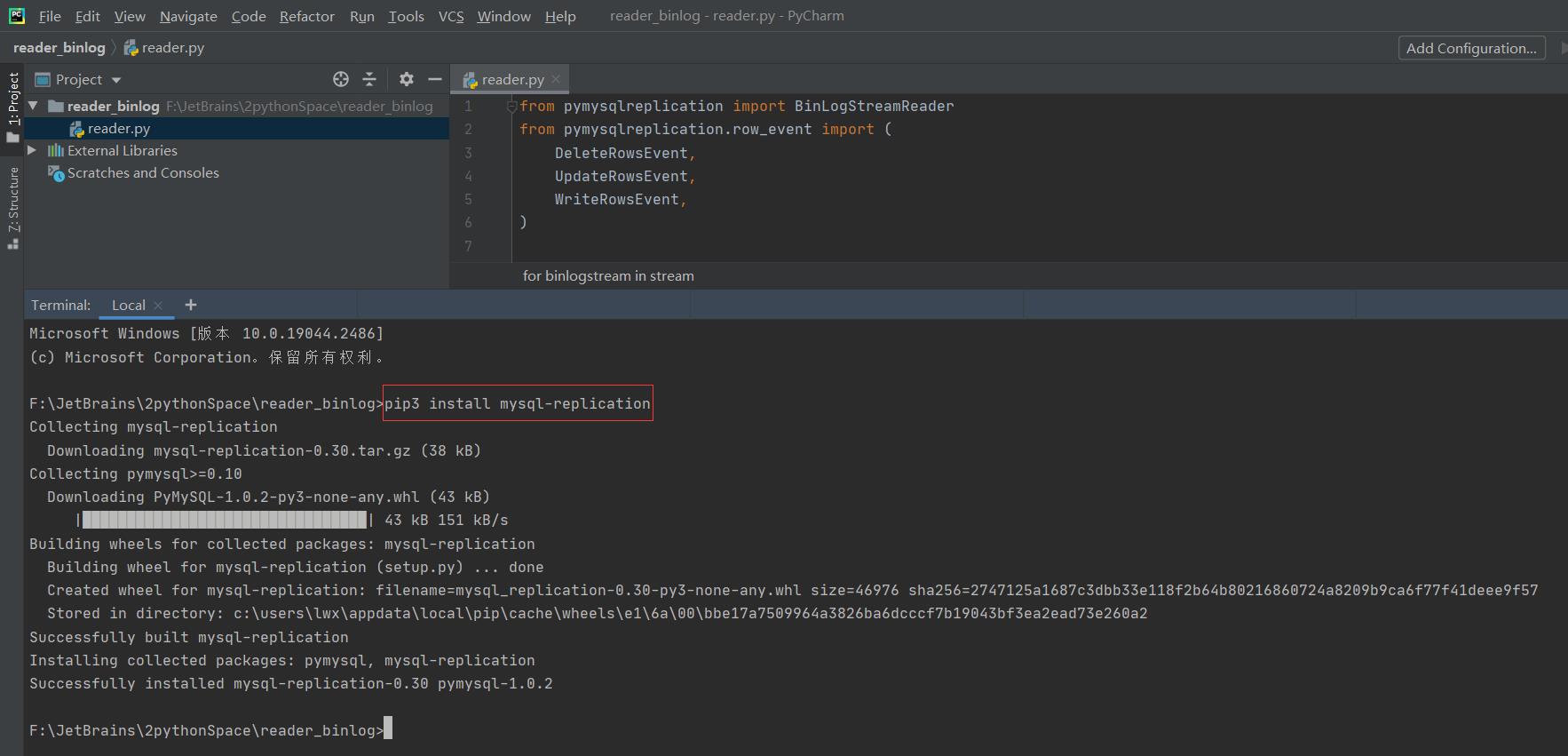
pip3 install mysql-replication
【MySQL】Server-id导致Slave_IO_Running: No主从复制故障_ITPUB博客
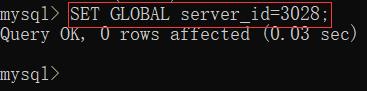
(1236, 'Misconfigured master - server id was not set')
- mysql> SET GLOBAL server_id=3028;
- Query OK, 0 rows affected (0.00 sec)
程序汇总
reader.py
from pymysqlreplication import BinLogStreamReader
from pymysqlreplication.row_event import (
DeleteRowsEvent,
UpdateRowsEvent,
WriteRowsEvent,
)
import json
import sys
MYSQL_SETTINGS =
"host": "localhost",
"user": "root",
"password": "root"
stream = BinLogStreamReader(connection_settings=MYSQL_SETTINGS,
server_id=2,
blocking=True,
only_schemas="readerbinlog",
only_events=[WriteRowsEvent, UpdateRowsEvent, DeleteRowsEvent])
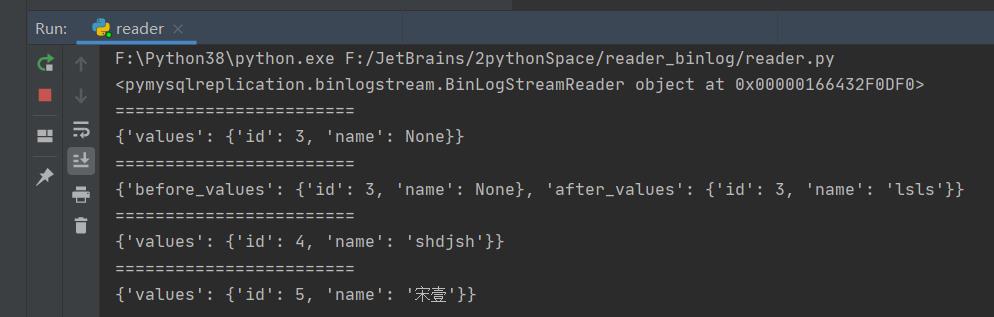
print(stream)
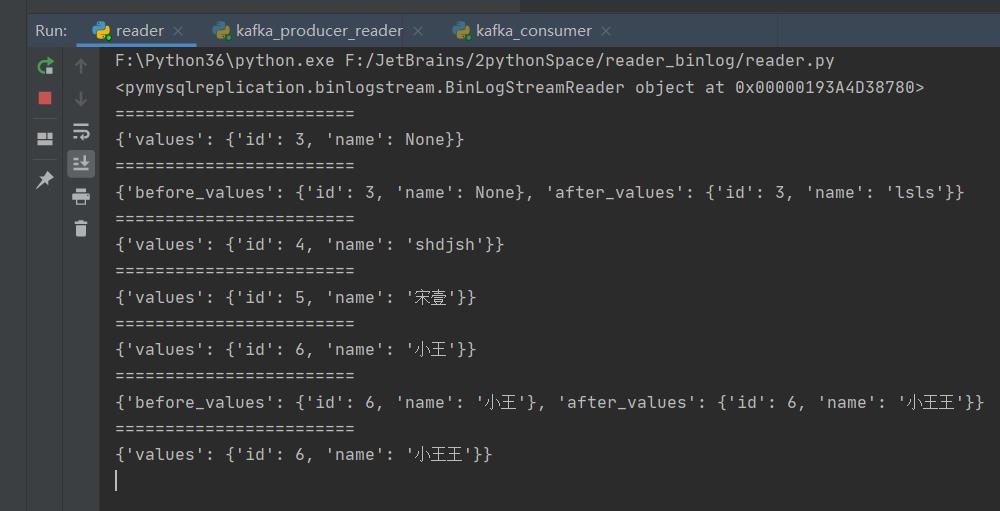
for binlogstream in stream:
for row in binlogstream.rows:
print("========================")
print(row)运行截图
P02-kafka生产者消费者模式消费binlog
zookeeper安装
zookeeper下载地址:Index of /zookeeper

kafka安装
kafka下载地址:Apache Kafka
cd windows
dir
kafka-server-start
kafka-server-start ..\\..\\config\\server.properties
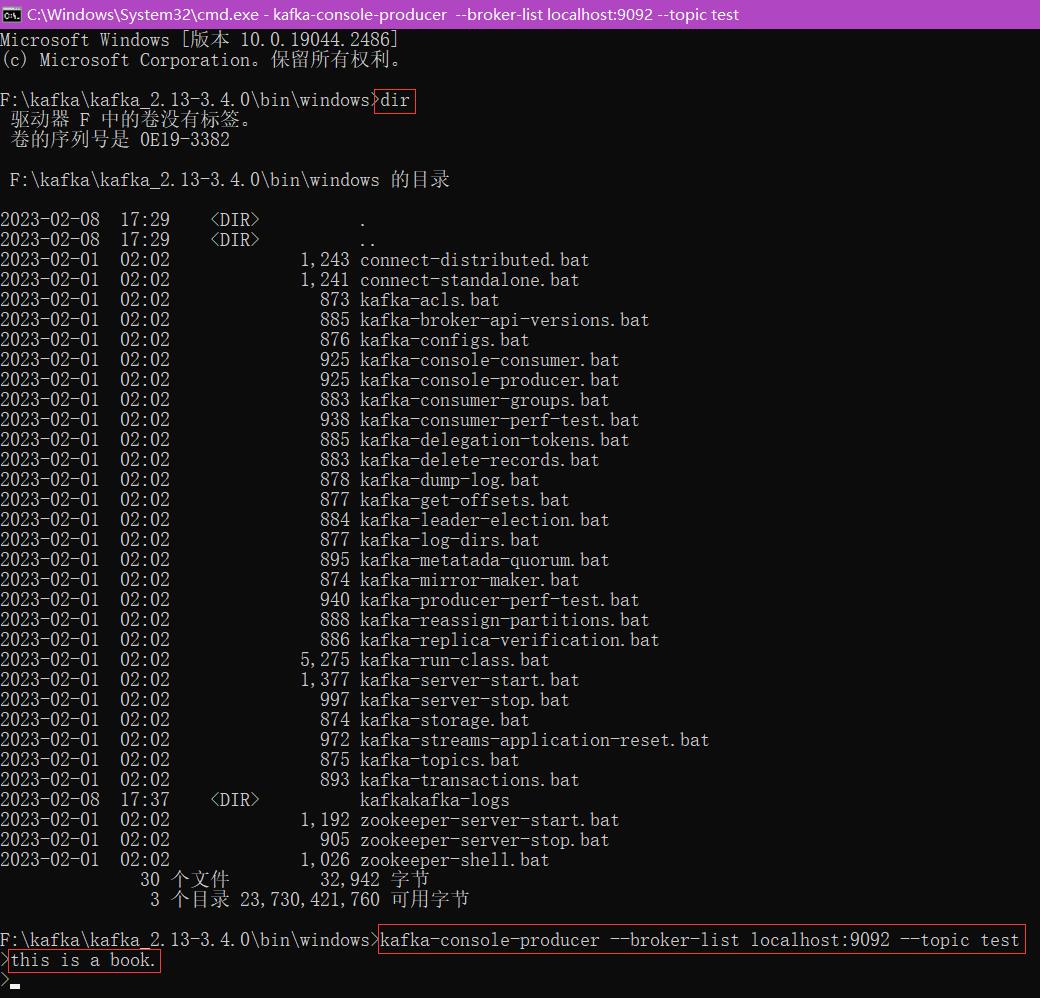
kafka-console-producer --broker-list localhost:9092 --topic test
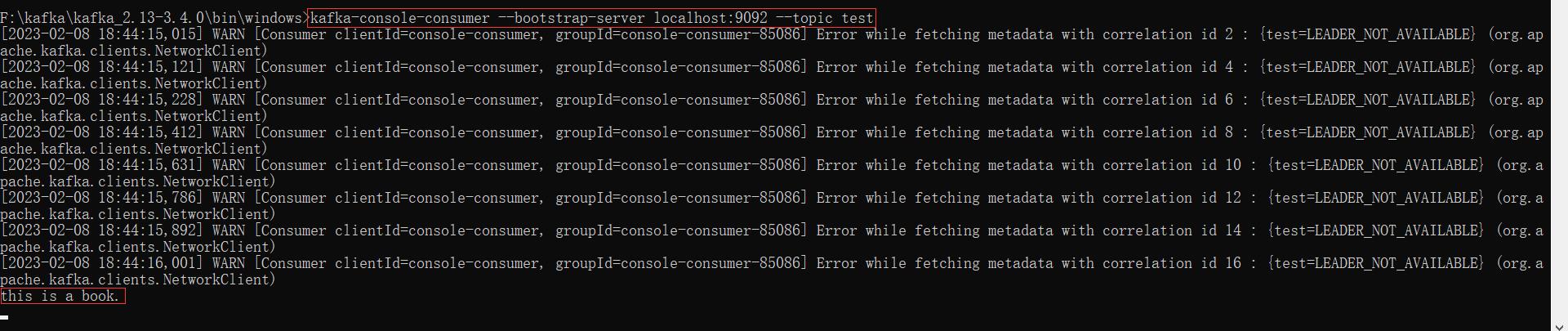
kafka-console-consumer --bootstrap-server localhost:9092 --topic test
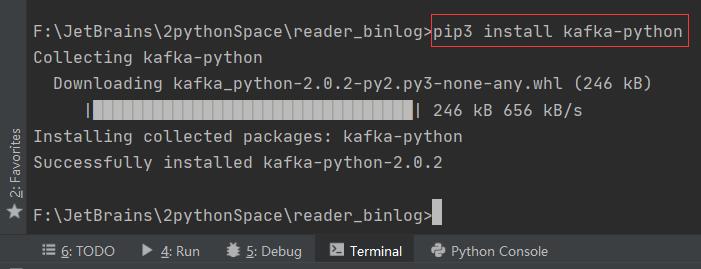
pip3 install kafka-python
程序汇总
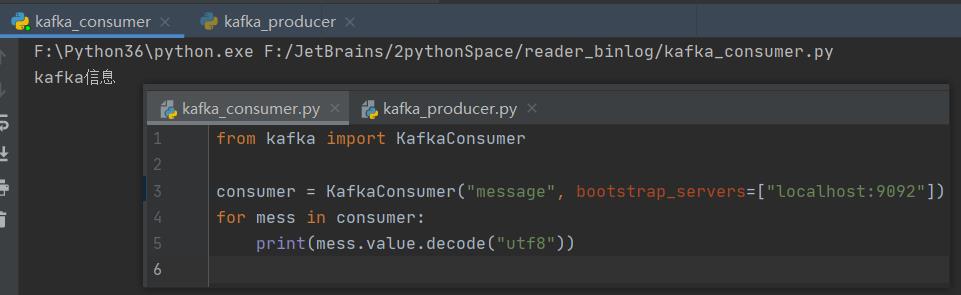
kafka_consumer.py
from kafka import KafkaConsumer
consumer = KafkaConsumer("message", bootstrap_servers=["localhost:9092"])
for mess in consumer:
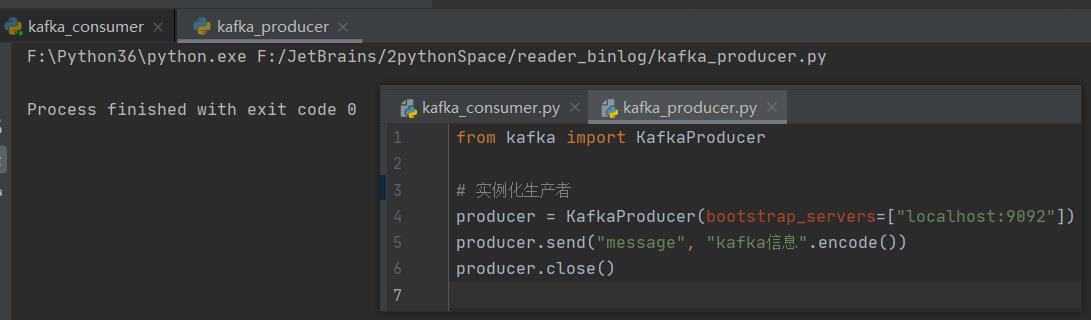
print(mess.value.decode("utf8"))kafka_producer.py
from kafka import KafkaProducer
# 实例化生产者
producer = KafkaProducer(bootstrap_servers=["localhost:9092"])
producer.send("message", "kafka信息".encode())
producer.close()kafka_producer_reader.py
from kafka import KafkaProducer
import json
# 实例化生产者
producer = KafkaProducer(bootstrap_servers=["localhost:9092"])
from pymysqlreplication import BinLogStreamReader
from pymysqlreplication.row_event import (
DeleteRowsEvent,
UpdateRowsEvent,
WriteRowsEvent,
)
MYSQL_SETTINGS =
"host": "localhost",
"user": "root",
"password": "root"
stream = BinLogStreamReader(connection_settings=MYSQL_SETTINGS,
server_id=4,
blocking=True,
only_schemas="readerbinlog",
only_events=[WriteRowsEvent, UpdateRowsEvent, DeleteRowsEvent])
# print(stream)
for binlogstream in stream:
for row in binlogstream.rows:
# print("========================")
# print(row)
row_json = json.dumps(row, ensure_ascii=False)
producer.send("message", row_json.encode())
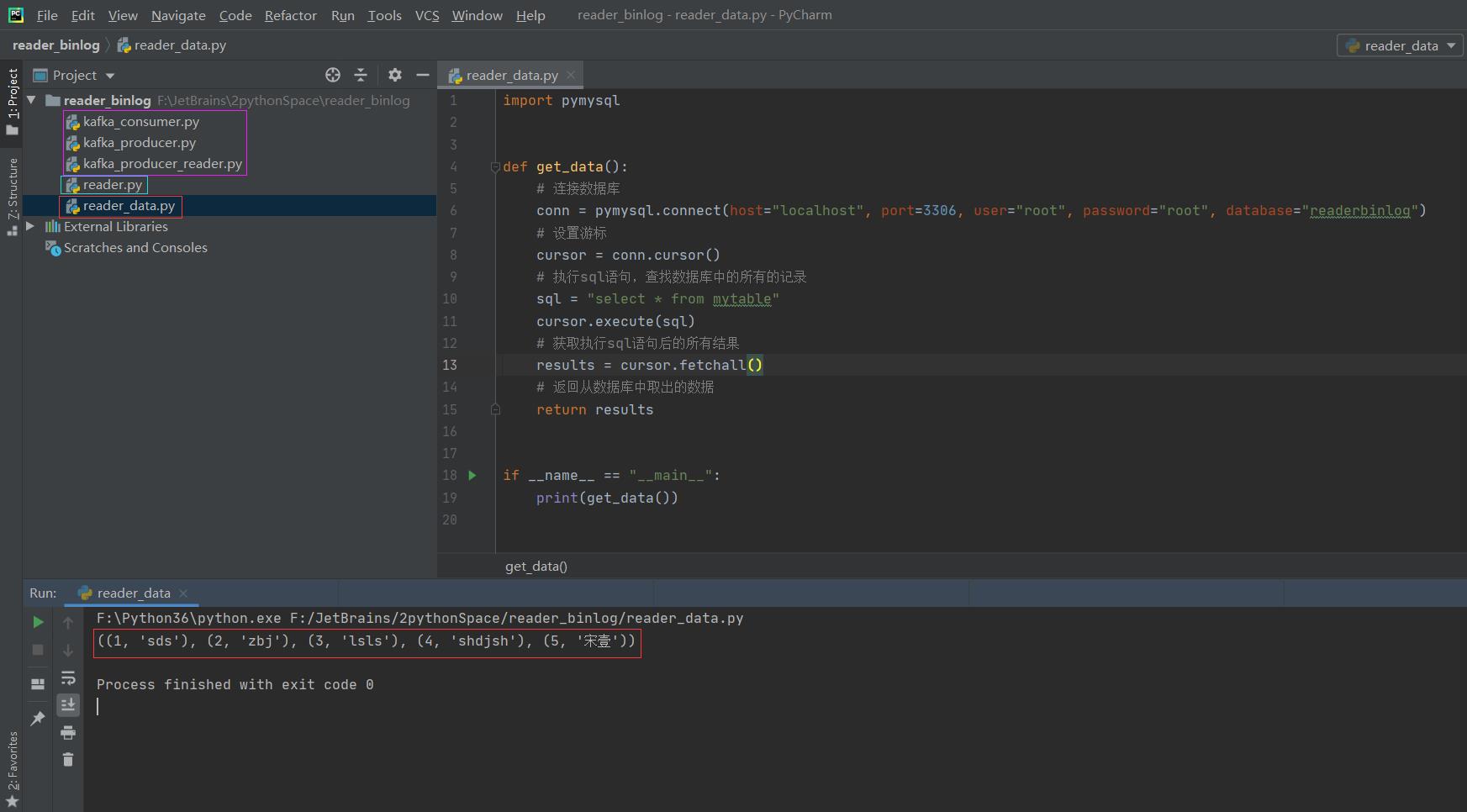
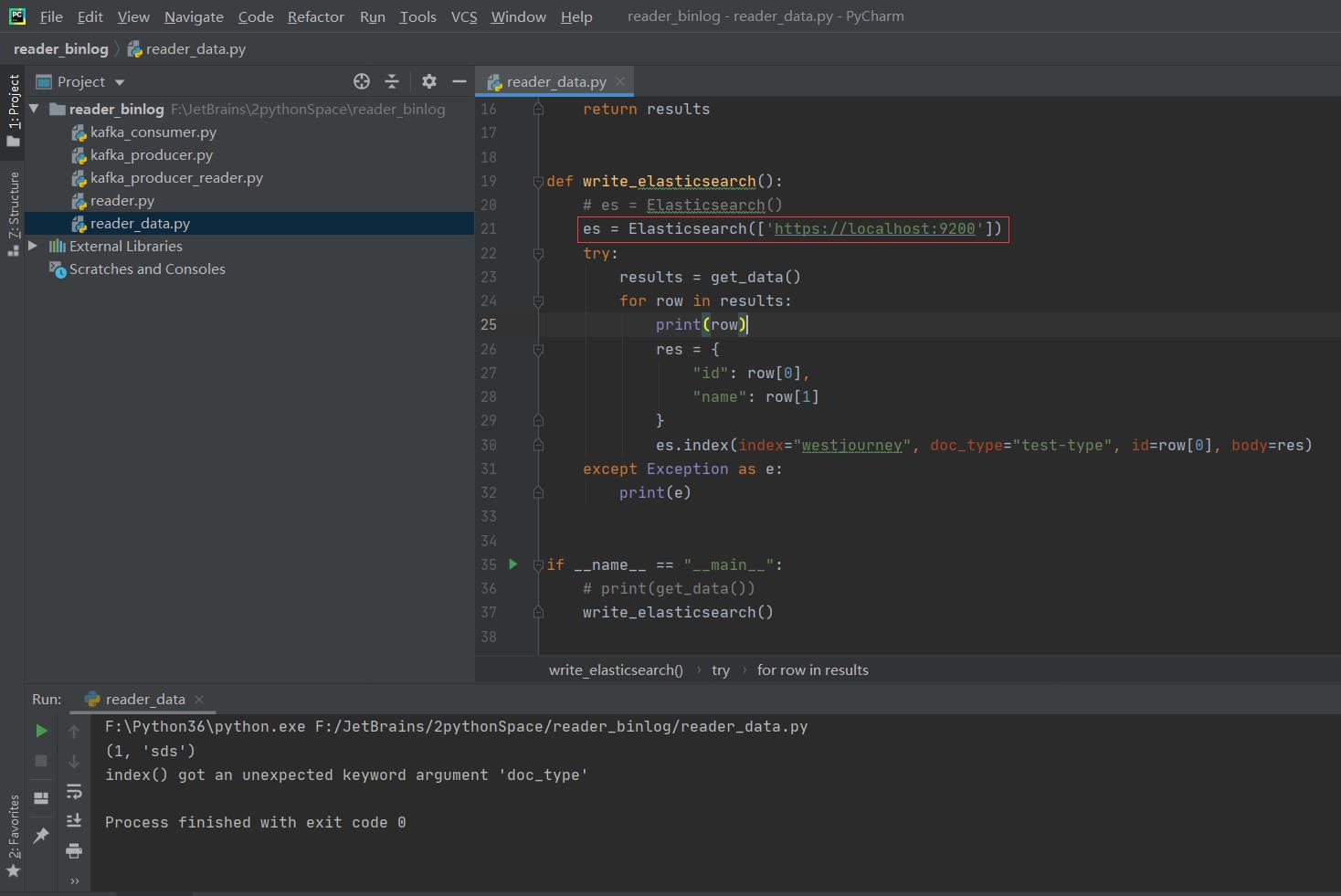
producer.close()reader_data.py
import pymysql
from elasticsearch import Elasticsearch
def get_data():
# 连接数据库
conn = pymysql.connect(host="localhost", port=3306, user="root", password="root", database="readerbinlog")
# 设置游标
cursor = conn.cursor()
# 执行sql语句,查找数据库中的所有的记录
sql = "select * from mytable"
cursor.execute(sql)
# 获取执行sql语句后的所有结果
results = cursor.fetchall()
# 返回从数据库中取出的数据
return results
def write_elasticsearch():
# es = Elasticsearch()
es = Elasticsearch(['http://localhost:9100'])
try:
results = get_data()
for row in results:
print(row)
res =
"id": row[0],
"name": row[1]
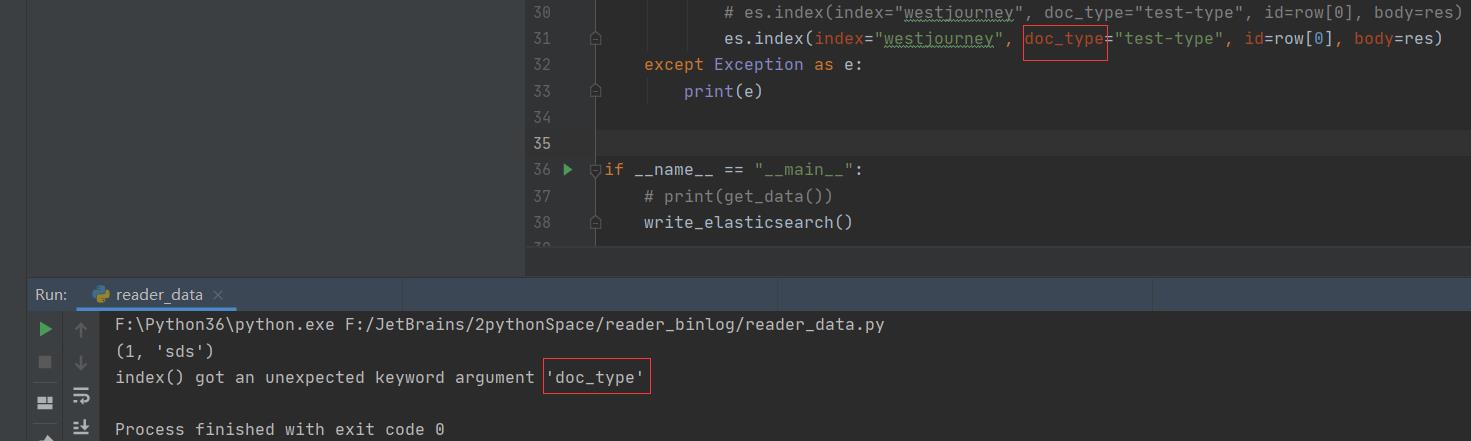
# es.index(index="westjourney", doc_type="test-type", id=row[0], body=res)
es.index(index="westjourney", doc_type="test-type", id=row[0], body=res)
except Exception as e:
print(e)
if __name__ == "__main__":
# print(get_data())
write_elasticsearch()运行截图
P03-elasticsearch的增删改同步数据库
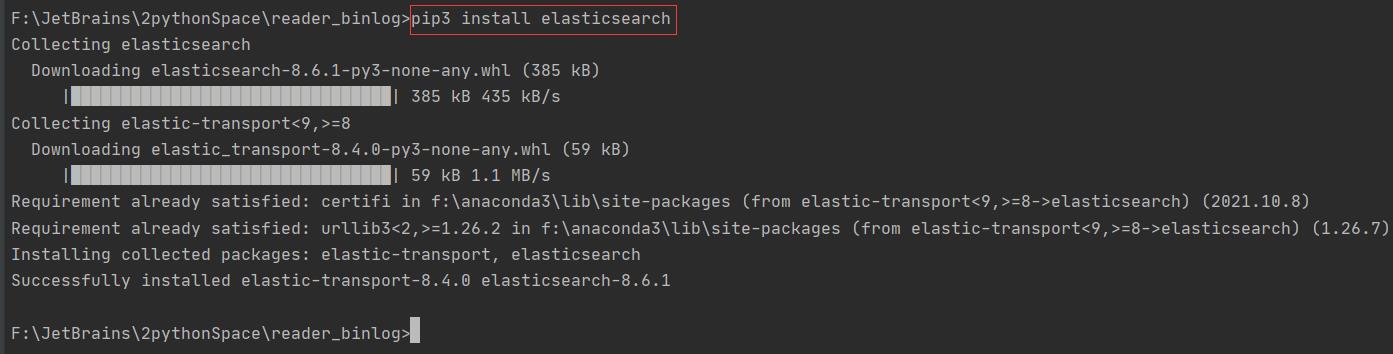
pip3 install elasticsearch
谷歌浏览器es head插件。
import pymysql
from elasticsearch import Elasticsearch
def get_data():
# 连接数据库
conn = pymysql.connect(host="localhost", port=3306, user="root", password="root", database="readerbinlog")
# 设置游标
cursor = conn.cursor()
# 执行sql语句,查找数据库中的所有的记录
sql = "select * from mytable"
cursor.execute(sql)
# 获取执行sql语句后的所有结果
results = cursor.fetchall()
# 返回从数据库中取出的数据
return results
def write_elasticsearch():
# es = Elasticsearch()
es = Elasticsearch(['http://localhost:9100'])
try:
results = get_data()
for row in results:
print(row)
res =
"id": row[0],
"name": row[1]
# es.index(index="westjourney", doc_type="test-type", id=row[0], body=res)
es.index(index="westjourney", doc_type="test-type", id=row[0], body=res)
except Exception as e:
print(e)
if __name__ == "__main__":
# print(get_data())
write_elasticsearch()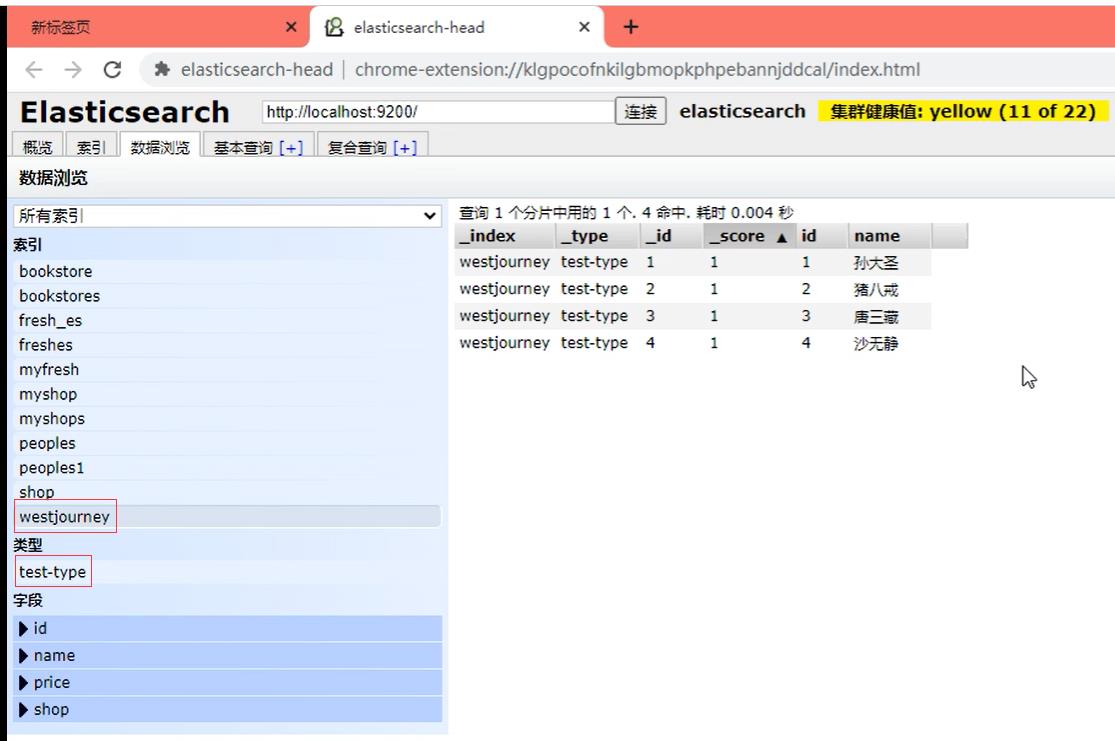
程序汇总
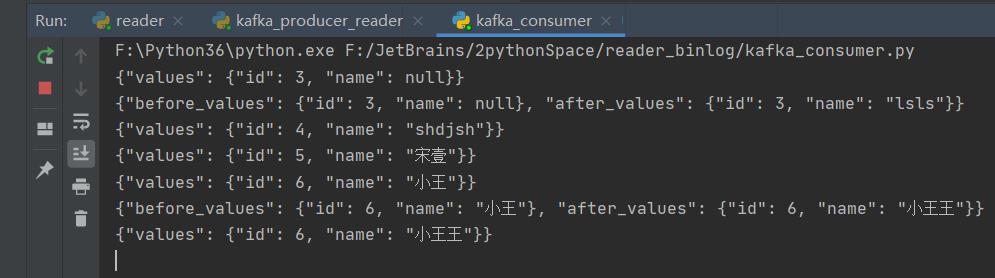
kafka_consumer.py
from kafka import KafkaConsumer
import json
from elasticsearch import Elasticsearch
consumer = KafkaConsumer("message", bootstrap_servers=["localhost:9092"])
es = Elasticsearch()
for mess in consumer:
# print(mess.value.decode("utf8"))
# 传进来的数据需要进行json转换
result = json.loads(mess.value.decode("utf8"))
# print(event["event"])
event = result["event"]
if event == "insert":
result_values = result["values"]
es.index(index="westjourney", doc_type="test-type", id=result_values["id"], body=result_values)
print("添加数据成功!")
elif event == "update":
# 注意更新操作,body内容要加入一个doc键,指示的内容就是要修改的内容
result_values = result["after_values"]
es.update(index="westjourney", doc_type="test-type", id=result_values["id"], body="doc": result_values)
print("更新数据成功!")
elif event == "delete":
result_id = result["values"]["id"]
es.delete(index="westjourney", doc_type="test-type", id=result_id)
print("删除数据成功!")kafka_producer.py
from kafka import KafkaProducer
# 实例化生产者
producer = KafkaProducer(bootstrap_servers=["localhost:9092"])
producer.send("message", "kafka信息".encode())
producer.close()kafka_producer_reader.py
from kafka import KafkaProducer
import json
# 实例化生产者
producer = KafkaProducer(bootstrap_servers=["localhost:9092"])
from pymysqlreplication import BinLogStreamReader
from pymysqlreplication.row_event import (
DeleteRowsEvent,
UpdateRowsEvent,
WriteRowsEvent,
)
MYSQL_SETTINGS =
"host": "localhost",
"user": "root",
"password": "root"
stream = BinLogStreamReader(connection_settings=MYSQL_SETTINGS,
server_id=4,
blocking=True,
only_schemas="readerbinlog",
only_events=[WriteRowsEvent, UpdateRowsEvent, DeleteRowsEvent])
# print(stream)
for binlogstream in stream:
for row in binlogstream.rows:
# print("========================")
# print(row)
if isinstance(binlogstream, WriteRowsEvent):
row["event"] = "insert"
elif isinstance(binlogstream, UpdateRowsEvent):
row["event"] = "update"
elif isinstance(binlogstream, DeleteRowsEvent):
row["event"] = "delete"
row_json = json.dumps(row, ensure_ascii=False)
producer.send("message", row_json.encode())
producer.close()reader_data.py
import pymysql
from elasticsearch import Elasticsearch
def get_data():
# 连接数据库
conn = pymysql.connect(host="localhost", port=3306, user="root", password="root", database="readerbinlog")
# 设置游标
cursor = conn.cursor()
# 执行sql语句,查找数据库中的所有的记录
sql = "select * from mytable"
cursor.execute(sql)
# 获取执行sql语句后的所有结果
results = cursor.fetchall()
# 返回从数据库中取出的数据
return results
def write_elasticsearch():
# es = Elasticsearch()
es = Elasticsearch(['http://localhost:9100'])
try:
results = get_data()
for row in results:
print(row)
res =
"id": row[0],
"name": row[1]
# es.index(index="westjourney", doc_type="test-type", id=row[0], body=res)
es.index(index="westjourney", doc_type="test-type", id=row[0], body=res)
except Exception as e:
print(e)
if __name__ == "__main__":
# print(get_data())
write_elasticsearch()附录
视频word笔记





sql语句-readerbinlog.sql
/*
SQLyog Ultimate v12.08 (64 bit)
MySQL - 5.5.40-log : Database - readerbinlog
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`readerbinlog` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `readerbinlog`;
/*Table structure for table `mytable` */
DROP TABLE IF EXISTS `mytable`;
CREATE TABLE `mytable` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `mytable` */
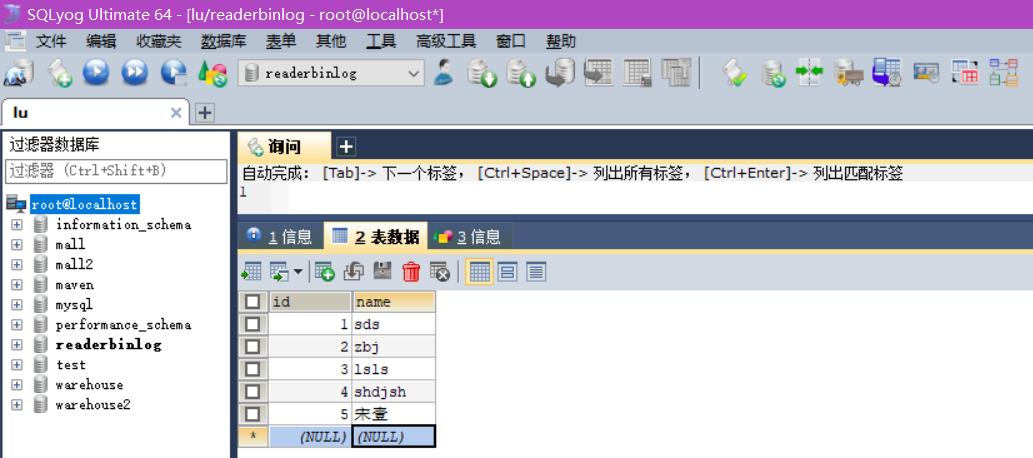
insert into `mytable`(`id`,`name`) values (1,'sds'),(2,'zbj'),(3,'lsls'),(4,'shdjsh'),(5,'宋壹');
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;ヾ(◍°∇°◍)ノ゙加油~
以上是关于MySQL数据同步到ES集群(MySQL数据库与ElasticSearch全文检索的同步)的主要内容,如果未能解决你的问题,请参考以下文章
MySQL到Elasticsearch实时同步构建数据检索服务的选型与思考
20.elasticsearch-jdbc实现MySQL同步到ElasticSearch(ES与关系型数据库同步)