显著性检测:'Saliency Detection via Graph-Based Manifold Ranking'论文总结
Posted peijialun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了显著性检测:'Saliency Detection via Graph-Based Manifold Ranking'论文总结相关的知识,希望对你有一定的参考价值。
对显著性检测的一些了解:
一般认为,良好的显著性检测模型应至少满足以下三个标准:
1)良好的检测:丢失实际显著区域的可能性以及将背景错误地标记为显著区域应该是低的;
2)高分辨率:显著图应该具有高分辨率或全分辨率以准确定位突出物体并保留原始图像信息;
3)计算效率:作为其他复杂过程的前端,这些模型应该快速检测显著区域。
最早在心里学和神经科学等多个学科上,就开始进行显著物体的检测。在计算机视觉领域,已经在人类关注机制的建模方面做出了努力,特别是自下而上的注意机制。 这种过程也称为视觉显著性检测。在检测显著性区域时通常分为自上而下和自下而上两种方法,在本文中主要运用自下而上的方法。
1)自上而下(top-down):即从比较一般的规则开始,逐渐增加新文字以缩小规则覆盖范围,直到满足预定条件为止,也称为生成-测试(generate-then-test)法,是规则逐渐特化(specialization)的过程,是从一般到特殊的过程。
2)自下而上(bottom-up):即从比较特殊的规则开始,逐渐删除文字以扩大覆盖范围,直到满足条件为止;也称为数据驱动(data-driven)法,是规则逐渐泛化(generalization)的过程,是从特殊到一般的过程。
自顶向下是覆盖范围从大到小搜索规则,自底向上则正好相反;前者更容易产生泛化性能较好的规则,而后者更适合于训练样本较少的情形;另外,前者对噪声的鲁棒性比后者要强;因此,在命题规则学习中通常使用前者,而后者则在一阶规则学习这类假设空间非常复杂的任务使用较多。
传统的显著性检测方法:
1. 模拟生物体视觉注意机制的选择性注意算法。
方法:特征提取->归一化->特征综合/显著度计算->显著性区域划分/兴趣点标定。
显著值是像素点在颜色、亮度、方向方面与周边背景的对比值。
L. Itti, C. Koch, & E. Niebur .A model of saliency based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(11):1254-1259, 1998.
2. 模型是在Itti的模型基础之上运用马尔可夫随机场的特点构建二维图像的马尔可夫链,通过求其平衡分布而得到显著图。
算法步骤:
特征的提取:与Itti 算法类似
显著图生成 :马尔可夫链方法 将低层视觉机理与数学计算融合
J. Harel, C. Koch, &P. Perona. Graph-based visual saliency. Advances in Neural Information Processing Systems, 19:545-552, 2006.
3. 基于空间频域分析的算法,显著图通过对剩余谱R(f)做傅里叶逆变换得到。
Xiaodi Hou, Jonathan Harel and Christof Koch: Image Signature: Highlighting Sparse Salient Regions (PAMI 2012)
4. 在Spectral Residual基础之上提出的,该方法通过计算图像的四元傅里叶变换的相位谱得到图像的时空显著性映射。
事实上,图像的相位谱即图像中的显著性目标。图像中的每一个像素点都用四元组表示:颜色,亮度和运动向量。
PQFT模型独立于先验信息,不需要参数,计算高效,适合于实时显著性检测。
Chenlei Guo, Qi Ma, Liming Zhang: Spatio-temporal Saliency detection using phase spectrum of quaternion fourier transform. CVPR 2008
5. 这篇文章中,他们提出应当同时考虑局部信息和全局信息,例如注意力应该集中在某些特定区域而不是分散,距离视觉焦点更近的点容易被观察到等等,效果拔群。
S. Goferman, L. Zelnik-Manor, and A. Tal. Context-Aware Saliency Detection. CVPR 2010.
Saliency Detection via Graph-Based Manifold Ranking通过基于图形的流型排序进行显著性检测
本文的目的:综合利用图像中背景、前景的先验位置分布及连通性,得到显著物体分割的更好结果。
采用的方法:通过基于图的流形排序对图像元素(像素或区域)与前景线索或背景先验的信息进行排序。图像元素的显著性是基于给定种子(queries)的相关性来定义的。通过流行排序的方法将此先验扩散到并增加得到前景的比较可靠的估计。这些节点基于背景和前景种子的相似性来排序(通过关联矩阵(affinity matrices))。随后将前景的信息用类似的流行排序的方法加强,显著性检测以两阶段方案进行,以有效地提取背景区域和前景显著对象。
算法流程: SLIC图像过分割;构建相对应的图;背景先验的流行排序算法;自适应分割;前景上的流形排序算法
我们观察到背景通常呈现与四个图像边界中的每一个的局部或全局外观连通性,并且前景呈现外观一致性。在这项工作中,我们利用这些线索来计算基于超像素排名的像素显著性。对于每个图像,我们构造一个闭环图,其中每个节点都是一个超像素。我们将显著性检测建模为流形排序问题,并提出了用于图形标记的两阶段方案。在第一阶段,我们通过使用图像每一侧的节点作为标记的背景种子点来开拓边界先验。从每个标记结果中,我们根据节点与这些种子点的相关性(即排名)计算节点的显著性作为背景标签。然后将四个标记的图集成以生成显著图。在第二阶段,我们将在第一阶段的结果显著映射进行二值分割,并将标记的前景节点作为显著种子点。基于每个节点与最终映射的前景种子点的相关性来计算每个节点的显著性。
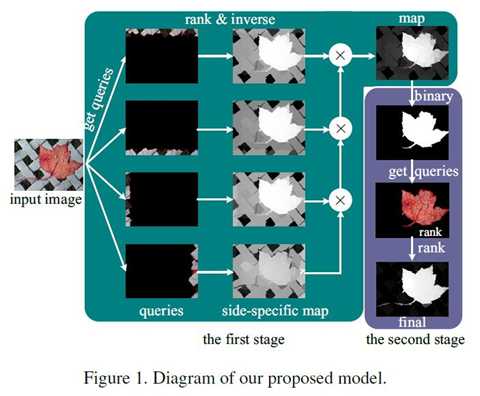
详细流程:
1. Graph Construction 图形构建
我们构造单层图G =(V,E),如图2所示,其中V是一组节点,E是一组无向边。在这项工作中,每个节点都是由SLIC算法生成的超像素。
使用k-regular图来利用空间关系。首先,每个节点不仅连接到与其相邻的节点,还连接到与其相邻节点共享公共边界的节点(参见图2)。通过扩展具有相同k度的节点连接范围,我们有效地利用了局部平滑线索。其次,我们强制连接图像四边的节点,即任何一对边界节点都被认为是相邻的。因此,我们将该图表示为闭环图。当显著对象出现在图像边界附近或某些背景区域不相同时,这些闭环约束很有效。
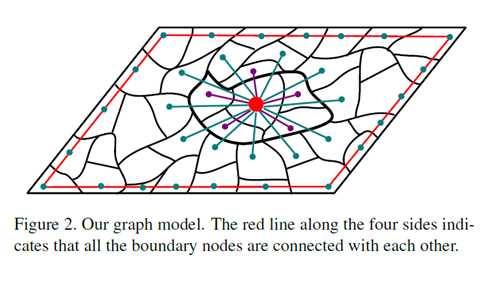
由于边缘的约束,很明显构造的图形是稀疏连接的。也就是说,关联矩阵W的大多数元素是零。在这项工作中,两个节点之间的权重由:
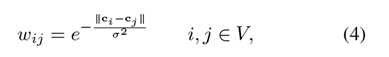
其中ci和cj表示对应于CIELAB颜色空间中的两个节点的超像素的平均值,并且σ是控制权重强度的常数。权重是根据颜色空间中的距离计算的,因为它已被证明在显著性检测中是有效的。当空间距离减小时,节点之间的相关性增加,这是显著性检测的重要信息。通过权重我们将邻接矩阵W可以求出。
2. Manifold Ranking 流行排序
给定数据集X={x1,…,xl,xl+1,…,xn}∈R(m*n),一些数据点被标记成种子点,其余的节点需要根据他们与种子点的相关性进行排序。让f:X→Rn记作成一个排序函数,他对于每一个数据点xi分配一个排序值fi,f可以被看成一个向量f=[f1,f2,…,fn]T.让y=[y1,y2,…,yn]T作为一个指示向量,如果xi是一个种子点,则yi=1,否则等于0。然后,我们在数据集上定义一个图G=(V,E),这里V代表数据集X,边缘E由邻接矩阵W=[wij]n*n加权。通过求解以下优化问题来计算种子点的最佳排名:
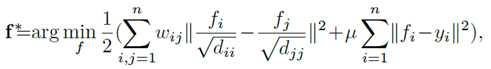 (1)
(1)
其中参数μ控制平滑度约束(第一项)和拟合约束(第二项)的平衡。 也就是说,良好的排名函数不应该在附近点之间变化太多(平滑约束),并且不应该与初始种子点赋值(拟合约束)相差太多。 通过将上述函数的导数设置为零来计算最小解。通过变换,最终的的排名函数可以写成:
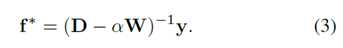 核心公式
核心公式
3. Saliency Measure 显著性测量
给定表示为图形的输入图像和一些显著的种子节点,每个节点的显著性被定义为由等式3计算的其排名分数,等式3被重写为f * = Ay以便于分析。矩阵A可以被认为是学习的最佳关联矩阵,其等于(D-αW)-1。第i个节点的排名得分f *(i)是第i行的A和y的内积。因为y是二进制指示符向量,所以f *(i)也可以被视为第i个节点与所有种子点的相关性的总和。
在传统的排序问题中,种子点是用参考图像手动标记的。然而,由于所提出的算法选择了显著性检测的种子点,其中一些可能是不正确的。因此,我们需要为每个种子点计算置信度(即显著性值),其被定义为由其他种子点(除了其自身)排名的排名得分。为此,我们在通过公式3计算排名分数时将A的对角元素设置为0。最后,我们使用归一化排名得分f *来衡量节点的显著性。当给出显著的种子点时,使用1-f *来给出背景种子点。
4. Two-Stage Saliency Detection 两个阶段的显著性检测
这一节详细介绍了使用背景和前景种子点排名的自下而上显著性检测的两阶段方案。
4.1 Ranking with Background Queries 背景种子点排序
使用图像边界上的节点作为背景种子,即标记数据(种子点样本)来对所有其他区域的相关性进行排序。具体来说,使用边界先验构建四个显著图,然后将它们整合到最终映射中,这被称为分离/组合(SC)方法。
以顶部图像边界为例,我们将此侧的节点用作种子点,将其他节点用作未标记的数据。因此,给出指示符向量y,并且基于等式3中的f*对所有节点进行排序。它是一个N维向量(N是图的节点总数)此向量中的每个元素表示节点与背景种子点的相关性,其补码是显著性度量。我们将此向量标准化为0到1之间的范围,使用顶部边界先验的显著性映射,St可写为:
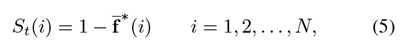
其中i表示索引图中的超像素节点, f*(i)表示归一化向量。
类似地,我们使用底部,左侧和右侧图像边界作为种子点来计算其他三个边界Sb,S1和Sr的显著性映射。我们注意到,显著图是用不同的指标向量y计算的,而权重矩阵和度矩阵D是固定的。也就是说,我们需要为每个图像计算一次矩阵的逆(D-αW)。由于超像素的数量很小,因此矩阵在方程3中的逆矩阵可以有效地计算。因此,四个映射的总计算负荷很低。通过以下过程整合四个显著性图:
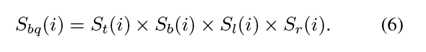
使用SC方法生成显著性图有两个原因。首先,不同侧面的超像素通常不相似,应该具有较大的距离。如果我们同时使用所有边界超像素作为种子点(即,指示这些超级像素是相似的),则标记结果通常不太理想,因为这些节点不可压缩(参见图4)。其次,它减少了不精确种子点的影响,即参考真实的突出节点被无意中选择作为后台种子点。如图5的第二列所示,使用所有边界节点生成的显著性图很差。由于标记结果不精确,具有显著对象的像素具有低显著性值。通过整合四个显著性图,可以识别对象的一些显著部分(尽管整个对象未被均匀地突出显示),这为第二阶段检测过程提供了足够的提示。


虽然显著对象的大部分区域在第一阶段突出显示,但某些背景节点可能无法被充分抑制(参见图4和图5)。为了缓解这个问题并改善结果,特别是当对象出现在图像边界附近时,通过使用前景种子点进行排名来进一步改进显著性图。
4.2 Ranking with Foreground Queries 背景种子点排序
第一阶段的显著性映射是使用自适应阈值的二分制分割(即显著前景和背景),其便于选择前景显著对象的节点作为种子点。我们期望所选择的种子点尽可能多地覆盖显著对象区域(即具有高召回率)。因此,阈值被设置为整个显著图上的平均显著性。一旦给出显著种子点,就形成指示符向量y使用等式3以计算排序向量f*。如在第一阶段中执行的那样,排名向量f*在0和1的范围之间归一化,以形成最终的显著图。
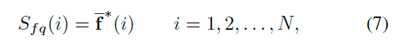
其中i是在图上超像素节点的索引,f*表示归一化向量。
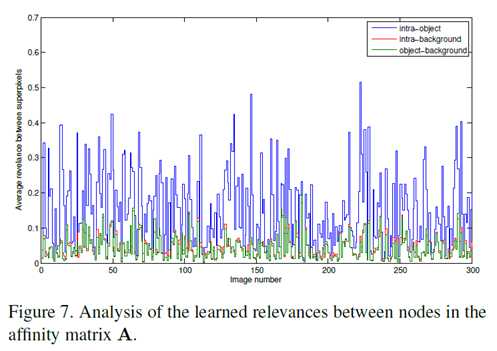
我们注意到在这个阶段可能会错误地选择节点作为前景种子点。尽管有一些不精确的标记,但是如图6所示,所提出的算法可以很好地检测到显著对象。这可以解释如下。突出物体区域通常相对紧凑(在空间分布方面)并且外观均匀(在特征分布方面),而背景区域则相反。换句话说,对象内相关性(即显著对象的两个节点)在统计上远大于对象背景和背景内相关性,这可以从关联矩阵A推断出。为了显示这种现象,我们计算了从具有真实标签[2]的数据集中采样的300个图像中的每一个A中的对象内,背景内和对象与背景的平均相关性值,如图7所示。因此,对象节点与参考值得显著种子点的相关性值总和远大于对所有种子点的背景节点的相关性值的总和。也就是说,可以有效地抑制背景显著性(图6的第四列)。类似地,尽管图5的第一阶段之后的显著性图不精确,但是在第二阶段中前景种子点的显著性映射之后可以很好地检测到显著对象。算法总结了所提出的显著对象检测算法的主要步骤。

算法:基于流形排序的自下而上显著性
输入:一幅图像和所需的参数
- 将输入图像分割成超像素,构造具有超像素作为节点的图G,并通过等式4计算其度矩阵D和权重矩阵W。
- 计算(D-αW)-1并将其对角线元素设置为0。
- 形成指示符向量y,其中图像每一侧的节点作为种子点,并通过等式3和5计算它们对应边界的映射。
- 二分值Sbq形成突出的前景种子点和指示符向量y。通过等式3和7计算显著性映射Sfq。
输出:代表每个超像素的显著性值的显著性映射Sfq。
MATLAB代码:
clear all;close all;clc;
addpath(‘./others/‘);
%%------------------------设置参数---------------------%%
theta=0.1; % 控制边缘的权重
alpha=0.99; % 控制流行排序成本函数两个项的平衡
spnumber=200; % 超像素的数量
imgRoot=‘./test/‘; % 测试图像的路径
saldir=‘./saliencymap/‘; % 显著性图像的输出路径
supdir=‘./superpixels/‘; % 超像素标签的文件路径
mkdir(supdir);
mkdir(saldir);
imnames=dir([imgRoot ‘*‘ ‘jpg‘]);
disp(imnames);
imname=[imgRoot imnames.name];
threshold=0.6;
input_im=imread(imname);
input_im=im2double(input_im);
gray=rgb2gray(input_im);
edgemap = edge(gray,‘canny‘); %输出边缘为1其余为0的二值化图像
[m,n]=size(edgemap);
w=[m,n,1,m,1,n];
outname=[imname(1:end-4) ‘.bmp‘];
imwrite(input_im,outname);
[m,n,k] = size(input_im);
%%----------------------生成超像素--------------------%%
imname=[imname(1:end-4) ‘.bmp‘];% the slic software support only the ‘.bmp‘ image
comm=[‘SLICSuperpixelSegmentation‘ ‘ ‘ imname ‘ ‘ int2str(20) ‘ ‘ int2str(spnumber) ‘ ‘ supdir]; %<filename> <spatial_proximity_weight> <number_of_superpixels> <path_to_save_results>
system(comm);
spname=[supdir imnames.name(1:end-4) ‘.dat‘];
fid = fopen(spname,‘r‘); %permission”是打开方式参数, r是读出
A = fread(fid, m * n, ‘uint32‘)‘; %fread(fid, N, ‘str‘) N代表读入元素个数, ‘str‘是格式类型
A = A + 1;
B = reshape(A,[n, m]);
superpixels = B‘;
fclose(fid);
spnum=max(superpixels(:)); %实际的朝向素数量
%%----------------------设计图形模型--------------------------%%
%计算特征值 (mean color in lab color space)
input_vals=reshape(input_im, m*n, k);
rgb_vals=zeros(spnum,1,3);
inds=cell(spnum,1);
for i=1:spnum
inds{i}=find(superpixels==i);
rgb_vals(i,1,:)=mean(input_vals(inds{i},:),1);
end
lab_vals = colorspace(‘Lab<-‘, rgb_vals);
seg_vals=reshape(lab_vals,spnum,3);% feature for each superpixel
% 求得边界
%求邻接矩阵
adjloop = zeros(spnum,spnum);
[m1 n1] = size(superpixels);
for i = 1:m1-1
for j = 1:n1-1
if(superpixels(i,j)~=superpixels(i,j+1))
adjloop(superpixels(i,j),superpixels(i,j+1)) = 1;
adjloop(superpixels(i,j+1),superpixels(i,j)) = 1;
end;
if(superpixels(i,j)~=superpixels(i+1,j))
adjloop(superpixels(i,j),superpixels(i+1,j)) = 1;
adjloop(superpixels(i+1,j),superpixels(i,j)) = 1;
end;
if(superpixels(i,j)~=superpixels(i+1,j+1))
adjloop(superpixels(i,j),superpixels(i+1,j+1)) = 1;
adjloop(superpixels(i+1,j+1),superpixels(i,j)) = 1;
end;
if(superpixels(i+1,j)~=superpixels(i,j+1))
adjloop(superpixels(i+1,j),superpixels(i,j+1)) = 1;
adjloop(superpixels(i,j+1),superpixels(i+1,j)) = 1;
end;
end;
end;
bd=unique([superpixels(1,:),superpixels(m,:),superpixels(:,1)‘,superpixels(:,n)‘]);
for i=1:length(bd)
for j=i+1:length(bd)
adjloop(bd(i),bd(j))=1;
adjloop(bd(j),bd(i))=1;
end
end
edges=[];
for i=1:spnum
indext=[];
ind=find(adjloop(i,:)==1);
for j=1:length(ind)
indj=find(adjloop(ind(j),:)==1);
indext=[indext,indj];
end
indext=[indext,ind];
indext=indext((indext>i));
indext=unique(indext);
if(~isempty(indext))
ed=ones(length(indext),2);
ed(:,2)=i*ed(:,2);
ed(:,1)=indext;
edges=[edges;ed];
end
end
% 计算关联矩阵
valDistances=sqrt(sum((seg_vals(edges(:,1),:)-seg_vals(edges(:,2),:)).^2,2));
valDistances=normalize(valDistances); %Normalize to [0,1]
weights=exp(-valDistances/theta);
W = adjacency(edges,weights,spnum);
% 最优化关联矩阵 (公式3)
dd = sum(W); D = sparse(1:spnum,1:spnum,dd); clear dd;
%S = sparse(i,j,s,m,n,nzmax)由向量i,j,s生成一个m*n的含有nzmax个非零元素的稀疏矩阵S;即矩阵A中任何0元素被去除,非零元素及其下标组成矩阵S
optAff =eye(spnum)/(D-alpha*W);
mz=diag(ones(spnum,1));
mz=~mz; %将A的对角元素设置为0
optAff=optAff.*mz;
%%-----------------------------显著性检测第一阶段--------------------------%%
% 为每个超像素计算显著性值
% 作为种子点的上边界
Yt=zeros(spnum,1);
bst=unique(superpixels(1,1:n));
Yt(bst)=1;
bsalt=optAff*Yt;
bsalt=(bsalt-min(bsalt(:)))/(max(bsalt(:))-min(bsalt(:)));
bsalt=1-bsalt;
% 下边界
Yd=zeros(spnum,1);
bsd=unique(superpixels(m,1:n));
Yd(bsd)=1;
bsald=optAff*Yd; %f*(i) 此向量中的每个元素表示节点与背景种子点的相关性
bsald=(bsald-min(bsald(:)))/(max(bsald(:))-min(bsald(:))); % 归一化向量
bsald=1-bsald; %补码
% 右边界
Yr=zeros(spnum,1);
bsr=unique(superpixels(1:m,1));
Yr(bsr)=1;
bsalr=optAff*Yr;
bsalr=(bsalr-min(bsalr(:)))/(max(bsalr(:))-min(bsalr(:)));
bsalr=1-bsalr;
% 左边界
Yl=zeros(spnum,1);
bsl=unique(superpixels(1:m,n));
Yl(bsl)=1;
bsall=optAff*Yl;
bsall=(bsall-min(bsall(:)))/(max(bsall(:))-min(bsall(:)));
bsall=1-bsall;
% 四个边组合
bsalc=(bsalt.*bsald.*bsall.*bsalr);
bsalc=(bsalc-min(bsalc(:)))/(max(bsalc(:))-min(bsalc(:)));
% 为每个像素分配显著性值
tmapstage1=zeros(m,n);
for i=1:spnum
tmapstage1(inds{i})=bsalc(i);
end
tmapstage1=(tmapstage1-min(tmapstage1(:)))/(max(tmapstage1(:))-min(tmapstage1(:)));
mapstage1=zeros(w(1),w(2));
mapstage1(w(3):w(4),w(5):w(6))=tmapstage1;
mapstage1=uint8(mapstage1*255);
outname=[saldir imnames.name(1:end-4) ‘_stage1‘ ‘.png‘];
imwrite(mapstage1,outname);
%%----------------------显著性检测第二阶段-------------------------%%
% 自适应阈值二值化 (i.e. mean of the saliency map)
th=mean(bsalc); %阈值被设置为整个显著图上的平均显著性
bsalc(bsalc<th)=0;
bsalc(bsalc>=th)=1;
% 为每个超像素计算显著性值
fsal=optAff*bsalc;
% 为每个像素分配显著性值
tmapstage2=zeros(m,n);
for i=1:spnum
tmapstage2(inds{i})=fsal(i);
end
tmapstage2=(tmapstage2-min(tmapstage2(:)))/(max(tmapstage2(:))-min(tmapstage2(:)));
mapstage2=zeros(w(1),w(2));
mapstage2(w(3):w(4),w(5):w(6))=tmapstage2;
mapstage2=uint8(mapstage2*255);
outname=[saldir imnames.name(1:end-4) ‘_stage2‘ ‘.png‘];
imwrite(mapstage2,outname);
执行结果(自己随机挑选的照片):1.原始图片 2.超像素图片 3.显著性图片第一阶段 4. 显著性图片第二阶段




5. 实验结果
在三个数据集上评估所提出的方法。第一个是MSRA数据集[23],其中包含5,000个图像,其中显著区域的基本事实由边界框标记。第二个是MSRA-1000数据集,它是MSRA数据集的一个子集,其中包含[2]提供的1,000个图像,其中包含用于显著对象的精确的人工标记参考图。最后一个是提议的DUT-OMRON数据集, 其中包含5个用户的5,172个精心标记的图像。有关此数据集的源图像,ground-truth标签和详细说明,请访问http://ice.dlut.edu.cn/lu/DUT-OMRON/Homepage.htm。
实验设置:我们在所有实验中设置超像素节点的数量N=200。该算法有两个参数:方程4中的边界权重σ,等式3中的平衡权重α。参数σ控制一对节点之间的权重强度,参数α平衡流形排序算法正则化函数中的平滑约束和拟合约束。对于所有实验,这两个参数根据经验选择σ2= 0.1和α= 0.99。
评估指标:我们通过精确度,召回率和F度量来评估所有方法。精度值对应于正确分配给提取区域的所有像素的显着像素的比率,而召回值被定义为检测到的显着像素相对于地面实况数的百分比。与之前的工作类似,通过使用0到255范围内的阈值对显著性图进行二值化来获得精确度曲线。F度量是通过精度和召回的加权谐波计算的整体性能测量:
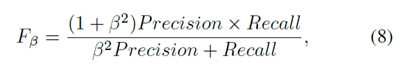
设置β2= 0.3来强调精度。
5.1 MSRA-1000

5.2 MSRA
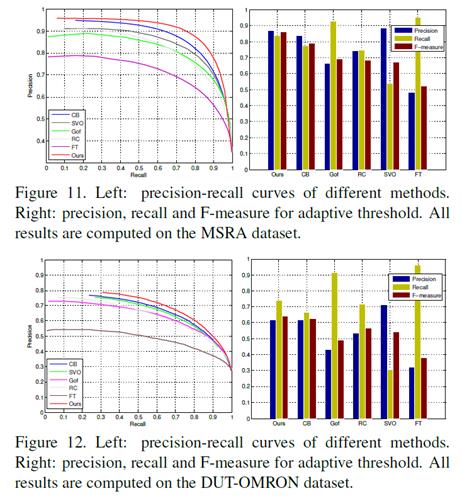
5.3. DUT-OMRON
我们在DUT-OMRON数据集上测试所提出的模型,其中图像由五个用户用边界框注释。类似于MSRA数据库上的实验,我们还计算了二元显著图的矩形,然后通过固定阈值和自适应阈值方法来评估我们的模型。图12显示建议的数据集更具挑战性(所有模型执行得更差),从而为未来工作的改进提供了更多空间。
5.4 运行时间

6. 总结
提出了一种自下而上的方法,通过图表上的流形排序来检测图像中的显著区域,其结合了局部分组线索和边界先验。我们采用两阶段方法,使用背景和前景种子点进行排名,以生成显著性图。我们在大型数据集上评估所提出的算法,并通过与十四种最先进的方法进行比较来展示有希望的结果。此外,所提出的算法在计算上是高效的。
本文两篇的参考文献也是很好的基础学习资料:
1.D. Zhou, O. Bousquet, T. Lal, J.Weston, and B. Scholkopf. Learning with local and global consistency. In NIPS, 2003. 3
2. D. Zhou, J. Weston, A. Gretton, O. Bousquet, and B. Scholkopf. Ranking on data manifolds. In NIPS, 2004. 2, 3
2018-08-31 00:46:05 裴佳伦
以上是关于显著性检测:'Saliency Detection via Graph-Based Manifold Ranking'论文总结的主要内容,如果未能解决你的问题,请参考以下文章
paper 27 :图像/视觉显著性检测技术发展情况梳理(Saliency DetectionVisual Attention)
显著性检测(saliency detection)评价指标之KL散度距离Matlab代码实现
视频显著性检测-----Predicting Video Saliency using Object-to-Motion CNN and Two-layer Convolutional LSTM(示例