深入浅出zookeeper之一:功能及本质
Posted owenandhisfriends
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出zookeeper之一:功能及本质相关的知识,希望对你有一定的参考价值。
zookeeper(下文简写为zk)大家都不陌生。但是,看到很多同学对zookeeper的理解过于程式化,有些地方甚至需要背,是大可不必的。把本质理解了,概念性和功能介绍都可以推出来的,而且架构要活学活用,透过现象看本质,才能对技术和技术领悟有大的提升。下面来看下zk的功能及本质。
zookeeper的定义及用途
我们先了解官方的定义。
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
Apache ZooKeeper 是一个致力于开发和维护开源服务器,该服务器实现高可用的分布式协调框架。
ZooKeeper is a high-performance coordination service for distributed applications. It exposes common services - such as naming, configuration management, synchronization, and group services - in a simple interface so you don‘t have to write them from scratch.
zookeeper是一个高性能的分布式应用协调服务框架。它以简单接口形式实现了一系列的通用服务,比如** 命名、配置管理、同步、分组 **等,因此你不必从一堆草稿中去实现他们.
zookeeper的本质功能
通过官方的定义介绍,我们知道了zk是一个server,擅长分布式协调功能。我们来分析下功能的本质实现是怎样的。
zk的数据模型是以znode的形式存储和组织。与标准文件系统类似,是一个树形结构,根节点是‘/‘。
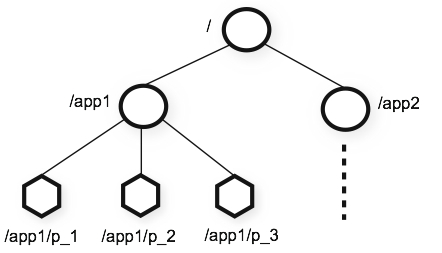
图中每个节点都是一个znode,类似于文件系统中的一个文件,形成了一个树形结构,每个znode内部还可以存储不超过1M的数据。这些znode可以是持久的,还可以是短期的(ephemeral )。
短期的(ephemeral )znode当创建他的客户端session超时,会被zk主动删除。有点类似给文件加锁,进程异常退出后,锁立刻解除。
zk的数据模型类似文件系统,这点也没什么特别的。本质还是kv形式,如果kv的value还要求是kv格式,那么就和zk的数据模型一样。表示成树形的格式,更容易表示层级关系。
zk的特别之处在于:
- zk内部的选主和写数据机制。有超过一半的zk集群节点选出来的主节点,成为集群的leader节点,负责主写和同步其他丛属follower节点。底层用的ZAB(ZooKeeper Atomic Broadcast)协议。
- 短期的(ephemeral )znode功能。方便实现锁类操作,在分布式中处理超时状态。
- 客户端可以设置监控watch某个znode的功能,当znode发生变化(版本号变更)时,会主动通知watch的客户端有变化了。该功能让客户端不必轮询,能够有序地知道znode变更顺序。
命名、配置管理、同步、分组等功能,都是通过1、2两点结合实现的。我们自研的业务如果想实现,也都能想到,或者用类似方式实现。
zk内部的选主和写数据机制。就不那么容易想了,只能依靠论文实现。所以这点更要好好学习下,这种方法很有特点,并且不容易想出来,也不容易理解。
与已有自研业务的区别
自研业务中,实现zk功能的,比较像的是配置中心(下文简称cc)。
一般实现cc,采用一主多从,主节点负责写,从节点只读。主节点通过binlog同步从节点,保证最终一致性。
主节点有两个写数据途径:
1、通过管理台的配置中心更新配置表;
2、通过客户端api上报服务状态,更新客户端节点负载和健康状况。
3、把心跳和变更回包作为一个协议,通知客户端配置更新。
如果从节点死机,不影响集群服务,对应的客户端寻找新的从节点去读。
如果主节点死机,cc只提供读服务,要人工来恢复。
影响:故障期间不能新增或修改配置以及配置项的负载。
如果用zk来实现cc,在正常情况下运行方式和cc是一样的。但是当主死机后,会用算法重新选出主,对客户端透明。让主节点死机停写的概率降低。但是如果有一半的节点死掉,会造成整个zk集群不可用。
对比:
| | 自研cc | zk |
|--------|--------|--------|
|选主方式|人工配置,主死了集群只读,人工介入恢复|集群协商选主,自恢复后继续服务
|集群完全不可用条件|所有节点都死掉|一半节点死掉(可能有分区问题造成zk内部同步有问题,但是节点是可以服务的)
zk的选主方式,并没有完胜一主多从的所有场景。
- 算法比较复杂,不容易理解和实现。
- 某些重要任务,出现主写问题,为了一致性,要人工介入恢复,自动选新主切换会造成数据丢失。
- 对于业务特定的场景特点,做一些弥补方案,能降低单点主写的风险。例如搭建多套cc,并行写,都对外提供服务,因为配置节点健康和负载的少量不一致,对业务来说是可以接受的。还可以在业务中增加缓存,保证主死了能够有足够的时间恢复。
以上自研业务没有引入ZAB或paxos协议的原因。在出现zk之后,想用的业务可以直接在zk之上构建集群内节点选主功能。
注意事项
我们在zk上构建服务的时候,要注意zk死一半节点就全集群死掉的特点。要考虑到如果zk集群不服务,业务有备选方案,能够对外尽力服务。例如zk充当配置中心,client要设置缓存,或默认配置。
为了节约资源,zk集群必须是奇数台机器。但是zk的机器数变多,对性能会有较大影响。写数据同步和选主都会变得越来越慢。
解决方法:
- 读多写少:增加观察者节点来扩展读性能。观察者节点不参与主从节点的协商和选举,只负责同步主节点。
- 读少写多:根据业务特点划分set,做到平行扩展。
总结
zookeeper通过ZAB协议实现了集群内部选主和写同步功能,提高了服务的健壮性,和写操作的有序性。是实现的难点,背后有严密的数学理论推理。
通过实现,短期的(ephemeral )znode和主动通知节点变更消息的功能,客户端能够及时知道监听节点变化,在客户端和zk断开连接后,也能够自动释放节点。轻松地实现锁类服务和监听更新类需求。这些是实现名字服务、配置管理、同步、分组等服务的基础。
转载请注明来源:深入浅出zookeeper之一:功能及本质
本文链接地址:https://www.owenzhang.net/blog/121.html

以上是关于深入浅出zookeeper之一:功能及本质的主要内容,如果未能解决你的问题,请参考以下文章
ZooKeeper 到底是什么?深入阐述 ZooKeeper