Zookeeper浅入浅出
Posted wtxuebc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper浅入浅出相关的知识,希望对你有一定的参考价值。
文章目录
zookeeper是什么
百度百科:
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
个人白话理解分布式协调服务:
分布式环境中有好多的分布式节点,有很多业务需要多个节点共同完成,而这些又不知道对应的rpc服务节点在哪一台主机上;(注意任何分布式节点都有可能成为客户端或者服务端,下文出现的客户端皆为发起rpc调用的一方)。
或者说提前在客户端静态保存了所有分布式服务节点的信息,由于每个客户端都必须有一份相关信息,但是由于是静态的,服务节点有相关更改后,客户端压根不知道,此时需要手动更改配置文件,很不方便!
此时就可以有一个分布式协调服务,扮演着一个协调的角色,记录服务节点的url,帮助rpc节点调用某个rpc服务时,只需要拿rpc服务的名字去协调服务查询即可;当rpc服务节点有相关改变时,协调服务中心会进行相关的调整;
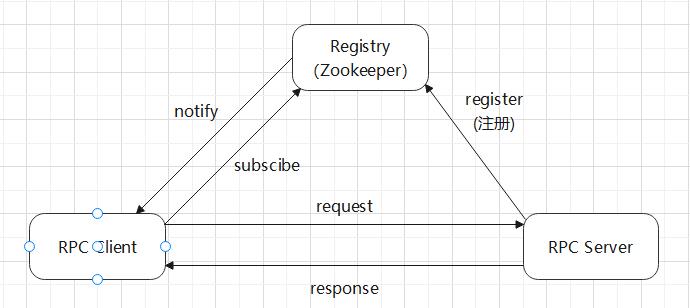
RPC server提供RPC服务,通过向Zookeeper中注册服务。zookeeper管理分布式服务,负责服务节点选取、Master节点选择、分布式一致性、注册功能。RPC client 作为消费者订阅RPC server服务,请求服务,zookeeper选取合适的节点响应client的请求。
其中zk默认的工作端口是2181
zookeeper提供了什么
特殊的文件系统
zookeeper维护了一个特殊的类似于文件系统的数据结构
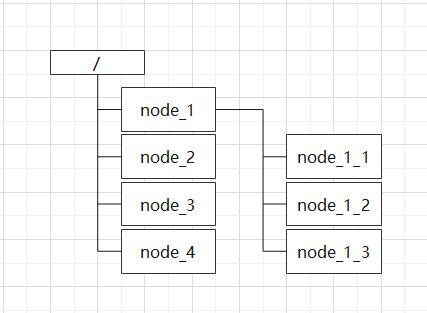
此时 node_1的path:/node_1
node_1_1的path:/node_1/node_1_1
每个子目录都叫一个znode节点,和文件系统一样,我们能够自由的增加、删除znode,和文件系统不同的是,znode本身是可以存储数据的;
数据都存储在磁盘中,对应的路径可以在zk的conf/zoo.cfg的配置文件里边更改
而节点又分:
临时节点:在zk发现(通过心跳机制,后面会提到)对应的节点宕机后,断开连接后会删除其url对应的znode节点;
持久化节点:在zk发现某节点宕机后,断开连接后不会删除其对应的znode。
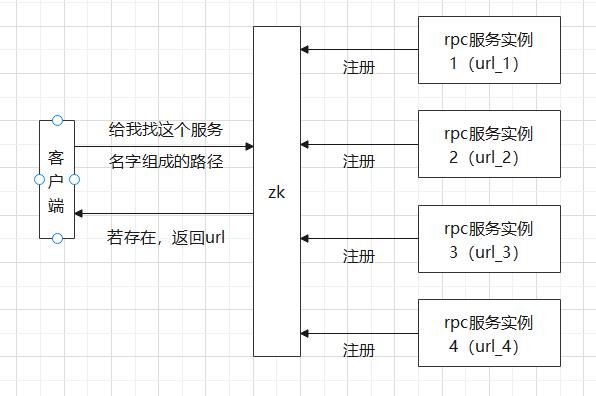
心跳机制
各个服务实例(rpc服务节点)都想zk注册节点,然后所有的服务实例都和zk建立session,要求服务实例定期发送心跳包,一旦特定时期收不到心跳,则认为实例已经挂掉,就会与其断开连接,此时不受close的四次挥手限制
综上,把用法简单的总结一下
当我们的客户端(一个rpc节点)去调用另一个rpc服务的时候,会拿这个rpc服务的名字加方法名构成一个节点路径,在zk上找这个节点路径是否存在,如果存在就获取节点值(节点数据存放的是ip地址加端口),就可以发起rpc通信了。
通知机制
客户端向zk注册监听它关心的目录节点,当目录节点以及其所有的子节点发生相应变化(节点增加、删除以及节点数据变化)时,zk会通知客户端。
这就是一个通知回调机制,此机制就是拿zk的watch实现的
可以通过zk的API向zk的一个节点添加一个watch观察器,如果父节点的任意一个子节点发生了如上相关变化,会由zk主动告知客户端有变化发生
这里记录一个不足:原生zk编程API三个不足
- 不主动发送心跳包
通过上面理论知识的讲述,心跳机制是非常重要的,因此这个问题是比较麻烦的。
- watch是一次性的
若观察的节点发生了变化,zk会主动告知客户端,此后,这个watch就失效了,在发生变化,zk不会主动告诉客户端了,因此得重新注册一个watch。
- znode节点只存储简单得byte字节数组,如果存储对象,需要自己转换对象生成字节数组
因此,各种版本的zk编程API也相继而出。
Zookeeper的工作机制
Zookeeper从设计模式的角度来理解的话,是一个基于观察者模式的分布式服务管理框架,它负责存储和管理重要的数据,然后接受观察者的注册,一旦这些被观察的数据状态发生变化,Zookeeper就负责通知已经在Zookeeper上注册的那些观察者让他们做出相应的反应。
Zookeeper集群
服务器的几种角色
Leader
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性
- 集群内部各服务的调度者
Follow
- 处理客户端的非事务请求,转发事务请求给Leader服务器
- 参与事务请求Proposal的投票
- 参与Leader选举投票
Observer
- 它是3.0版本以后才有的角色,是在不影响事务处理能力的情况下提升集群的非事务处理能力
- 不参与任何形似的投票
- 处理客户端的非事务请求,转发事务请求给Leader服务器
角色的工作状态
Looking
寻找Leader状态。服务器处于此状态时,会认为当前集群中没有Leader,因此需要进入Leader选举状态
Following
表明当前服务器是Follow
Leading
表明当前服务器是Leader
Observing
表明当前服务器角色是Observer
各服务器不是恪守本职,就是在选举leader的路上
事务的顺序一致性的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9pY65D2Z-1621993817805)(C:\\Users\\86155\\AppData\\Roaming\\Typora\\typora-user-images\\1621991236765.png)]](https://image.cha138.com/20210620/75f8b3d1ad0f4f819bffeb93886a3c23.jpg)
zookeeper 采用了全局递增的事务 id 来标识,所有的proposal(因为需要投票,简记为提议吧)都加上了 zxid,zxid是一个 64 位的数字,高 32 位是 epoch,用来标识 leader 周期,如果有新的 leader 产生出来,epoch会自增,低 32 位用来递增计数。当新产生 proposal 的时候,会依据数据库的两阶段过程,首先会向其他的 server 发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行。
注:因为需要选举且需要超过半数,因此集群中需半数以上的服务器节点存活(只能大于一半,不含等于),所以在部署服务器节点数量时,要合适的部署,数量太多,选举过程费时,而且执行条件高(大于半数),部署服务器数量的时候最好是奇数,偶数还要多一个服务器节点的同意
Zookeeper的其他功能
集群管理
监控节点的存活状态、运行请求等;
Master选举
主节点宕机后可以从其他节点选取一个新的主节点,使用Zookeeper可以协助完成这个过程
分布式锁
Zookeeper 提供两种锁:独占锁、共享锁。独占锁即一次只能有一个线程使用资源,共享锁是读锁共享,读写互斥,即可以有多线线程同时读同一个资源,如果要使用写锁也只能有一个线程使用。Zookeeper 可以对分布式锁进行控制。
命名服务
在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。
数据同步
在具体实现数据同步时,zookeeper又提供四种同步方式
DIFF 同步
DIFF 同步即差异化同步的方式.
在 ZooKeeper 集群中,Leader 服务器探测到 Learnning 服务器的存在后,首先会向该 Learnning 服务器发送一个 DIFF 不同指令。
在收到该条指令后,Learnning 服务器会进行差异化方式的数据同步操作。
接收到来自 Leader 服务器的 commit 命令后执行数据持久化的操作。
TRUNC+DIFF 同步
TRUNC+DIFF 同步代表先回滚再执行差异化的同步,这种方式一般发生在 Learnning 服务器上存在一条事务性的操作日志,但在集群中的 Leader 服务器上并不存在的情况 。
发生这种情况的原因可能是 Leader 服务器已经将事务记录到本地事务日志中,但没有成功发起 Proposal 流程。
当这种问题产生的时候,ZooKeeper 集群会首先进行回滚操作,在 Learning 服务器上的数据回滚到与 Leader 服务器上的数据一致的状态后,再进行 DIFF 方式的数据同步操作。
TRUNC 同步
TRUNC 同步是指仅回滚操作,就是将 Learnning 服务器上的操作日志数据回滚到与 Leader 服务器上的操作日志数据一致的状态下。之后并不进行 DIFF 方式的数据同步操作。
SNAP 同步
SNAP 同步的意思是全量同步,是将 Leader 服务器内存中的数据全部同步给 Learnning 服务器。
在进行全量同步的过程中,Leader 服务器首先会向 ZooKeeper 集群中的 Learning 服务器发送一个 SNAP 命令,在接收到 SNAP 命令后, ZooKeeper 集群中的 Learning 服务器开始进行全量同步的操作。
随后,Leader 服务器会从内存数据库中获取到全量数据节点和会话超时时间记录器,将他们序列化后传输给 Learnning 服务器。Learnning 服务器接收到该全量数据后,会对其反序列化后载入到内存数据库中。
同步后的处理
数据同步的本质就是比对 Leader 服务器与 Learning 服务器,将 Leader 服务器上的数据增加到 Learnning 服务器,再将 Learnning 服务器上多余的事物日志回滚。
数据同步这块的原文链接:https://blog.csdn.net/yangshangwei/article/details/111601919
以上是关于Zookeeper浅入浅出的主要内容,如果未能解决你的问题,请参考以下文章