ES的indexstore_source和all的区别
Posted wangzhuxing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES的indexstore_source和all的区别相关的知识,希望对你有一定的参考价值。
1.基本概念
1.1._source
存储的原始数据。_source中的内容就是搜索api返回的内容,如:
{ "query":{ "term": { "name":"国" } } }
结果:

默认情况下,Elasticsearch里面有2份内容,一份是原始文档,也就是_source字段里的内容,我们在Elasticsearch中搜索文档,查看的文档内容就是_source中的内容。另一份是倒排索引,倒排索引中的数据结构是倒排记录表,记录了词项和文档之间的对应关系。
1.2.index:索引
index使用倒排索引存储的是,分析器分析完的词和文档的对应关系。如图:
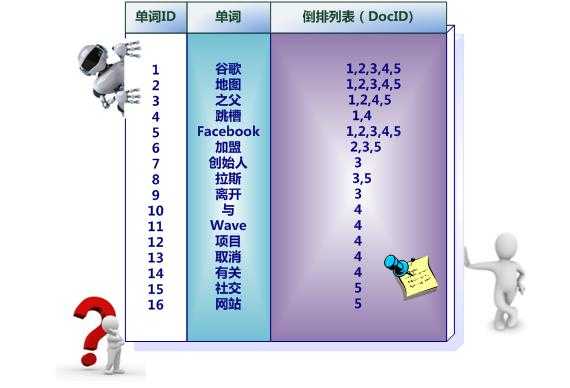
在搜索排序的时候,查询倒排索引要比快。
那么文档索引到Elasticsearch的时候,默认情况下是对所有字段创建倒排索引的(动态mapping解析出来为数字类型、布尔类型的字段除外),某个字段是否生成倒排索引是由字段的index属性控制的,在Elasticsearch 5之前,index属性的取值有三个:
- analyzed:字段被索引,会做分词,可搜索。反过来,如果需要根据某个字段进搜索,index属性就应该设置为analyzed。
- not_analyzed:字段值不分词,会被原样写入索引。反过来,如果某些字段需要完全匹配,比如人名、地名,index属性设置为not_analyzed为佳。
- no:字段不写入索引,当然也就不能搜索。反过来,有些业务要求某些字段不能被搜索,那么index属性设置为no即可。
1.3.store
默认为no,被store标记的fields被存储在和index不同的fragment中,以便于快速检索。虽然store占用磁盘空间,但是减少了计算。store的值可以取yes/no或者true/false,默认值是no或者false。
如果在{"store":yes}的情况下,ES会对该字段单独存储倒排索引,每次根据ID检索的时候,会多走一次IO来从倒排索引取数据。
而如果_source enabled 情况下,ES可以直接根据Client类来解析_source JSON,只需一次IO就将所有字段都检索出来了。
如果需要高亮处理,这里就要说到store属性,store属性用于指定是否将原始字段写入索引,默认取值为no。如果在Lucene中,高亮功能和store属性是否存储息息相关,因为需要根据偏移位置到原始文档中找到关键字才能加上高亮的片段。在Elasticsearch,因为_source中已经存储了一份原始文档,可以根据_source中的原始文档实现高亮,在索引中再存储原始文档就多余了,所以Elasticsearch默认是把store属性设置为no。
注意:如果想要对某个字段实现高亮功能,_source和store至少保留一个。
1.4._all
再说_all字段,顾名思义,_all字段里面包含了一个文档里面的所有信息,是一个超级字段。以图中的文档为例,如果开启_all字段,那么title+content会组成一个超级字段,这个字段包含了其他字段的所有内容,空格隔开。当然也可以设置只存储某几个字段到_all属性里面或者排除某些字段。适合一次搜索整个文档。
2.配置
2.1._source配置
_source字段默认是存储的, 什么情况下不用保留_source字段?如果某个字段内容非常多,业务里面只需要能对该字段进行搜索,最后返回文档id,查看文档内容会再次到mysql或者hbase中取数据,把大字段的内容存在Elasticsearch中只会增大索引,这一点文档数量越大结果越明显,如果一条文档节省几KB,放大到亿万级的量结果也是非常可观的。
如果想要关闭_source字段,在mapping中的设置如下:
{ "yourtype":{ "_source":{ "enabled":false }, "properties": { ... } } }
如果只想存储某几个字段的原始值到Elasticsearch,可以通过incudes参数来设置,在mapping中的设置如下:
{ "yourtype":{ "_source":{ "includes":["field1","field2"] }, "properties": { ... } } }
同样,可以通过excludes参数排除某些字段:
{ "yourtype":{ "_source":{ "excludes":["field1","field2"] }, "properties": { ... } } }
测试,首先创建一个索引:
PUT book2
设置mapping,禁用_source:
POST book2/english/_mapping
{ "book2": { "_source": { "enabled": false } } }
插入数据:
POST /book2/english/ { "title":"test!", "content":"test good Hellow" }
搜索"test"
POST book2/_search { "query":{ "term":{ "title":"test" } } }
结果,只返回了id,没有_suorce,任然可以搜索到。
{ "took": 5, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 0.2876821, "hits": [ { "_index": "book2", "_type": "english", "_id": "zns1Z2UBYLvVFwGW4Hea", "_score": 0.2876821 } ] } }
当_source=false,store和index必须有一个为true,原始数据不保存,倒排索引必须要存储,否则去哪里查询呢,验证下:
POST book3/english/_mapping { "english":{ "_source": { "enabled": false }, "properties": { "content":{ "type":"text", "store":"false", "index":"no" }, "title":{ "type":"text", "store":"false", "index":"no" } } } }
报错:
{ "error": { "root_cause": [ { "type": "illegal_argument_exception", "reason": "Could not convert [content.index] to boolean" } ], "type": "illegal_argument_exception", "reason": "Could not convert [content.index] to boolean", "caused_by": { "type": "illegal_argument_exception", "reason": "Failed to parse value [no] as only [true] or [false] are allowed." } }, "status": 400 }
2.2._all配置
_all字段默认是关闭的,如果要开启_all字段,索引增大是不言而喻的。_all字段开启适用于不指定搜索某一个字段,根据关键词,搜索整个文档内容。
开启_all字段的方法和_source类似,mapping中的配置如下:
{ "yourtype": { "_all": { "enabled": true }, "properties": { ... } } }
也可以通过在字段中指定某个字段是否包含在_all中:
以上是关于ES的indexstore_source和all的区别的主要内容,如果未能解决你的问题,请参考以下文章
使用 ES6 的 Promise.all() 时限制并发的最佳方法是啥?