跟我学Elasticsearch(7) es的嵌套聚合,下钻分析,聚合分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跟我学Elasticsearch(7) es的嵌套聚合,下钻分析,聚合分析相关的知识,希望对你有一定的参考价值。
参考技术A [Toc]演示前先往es写入三条商品数据用来演示查询
对all_tags字段做聚合/排序/脚本访问我们需要先把all_tags字段默认关闭的fielddata开启
开始演示
aggregations.terms_all_tags.buckets.key:标签
aggregations.terms_all_tags.buckets.doc_count:该标签对应的商品数量
ElasticSearch_05_ES的嵌套聚合,下钻分析,聚合分析
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、两个核心概念:bucket和metric
- 二、按搜索结果聚合
- 三、collect_mode
- 四、histogram 和 date histogram 间隔范围分组
- 五、global全局桶
- 总结
前言
本文所有的es操作语句:https://www.syjshare.com/res/PJ9F6DSN
一、两个核心概念:bucket和metric
按照某个字段进行bucket划分,那个字段的值相同的那些数据,就会被划分到一个bucket中
有一些mysql的sql知识的话,聚合,首先第一步就是分组,对每个组内的数据进行聚合分析,分组,就是我们的bucket
metric:对一个数据分组执行的统计
当我们有了一堆bucket之后,就可以对每个bucket中的数据进行聚合分词了,比如说计算一个bucket内所有数据的数量,或者计算一个bucket内所有数据的平均值,最大值,最小值
bucket:group by user_id --> 那些user_id相同的数据,就会被划分到一个bucket中
metric,就是对一个bucket执行的某种聚合分析的操作,比如说求平均值,求最大值,求最小值
开始,计算一个数量计算每个tag下的商品数量。
1.1 数据预制
DELETE /ecommerce
PUT /ecommerce/product/1
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
PUT /ecommerce/product/2
"name" : "jiajieshi yagao",
"desc" : "youxiao fangzhu",
"price" : 25,
"producer" : "jiajieshi producer",
"tags": [ "fangzhu" ]
PUT /ecommerce/product/3
"name" : "zhonghua yagao",
"desc" : "caoben zhiwu",
"price" : 40,
"producer" : "zhonghua producer",
"tags": [ "qingxin" ]
GET _search
数据准备,开始新的一篇

1.2 按照tags字段分组
PUT /ecommerce/_mapping/product
"properties":
"tags":
"type": "text",
"fielddata": true
GET /ecommerce/product/_search
"size" : 0,
"aggs":
"group_by_tags":
"terms": "field": "tags"

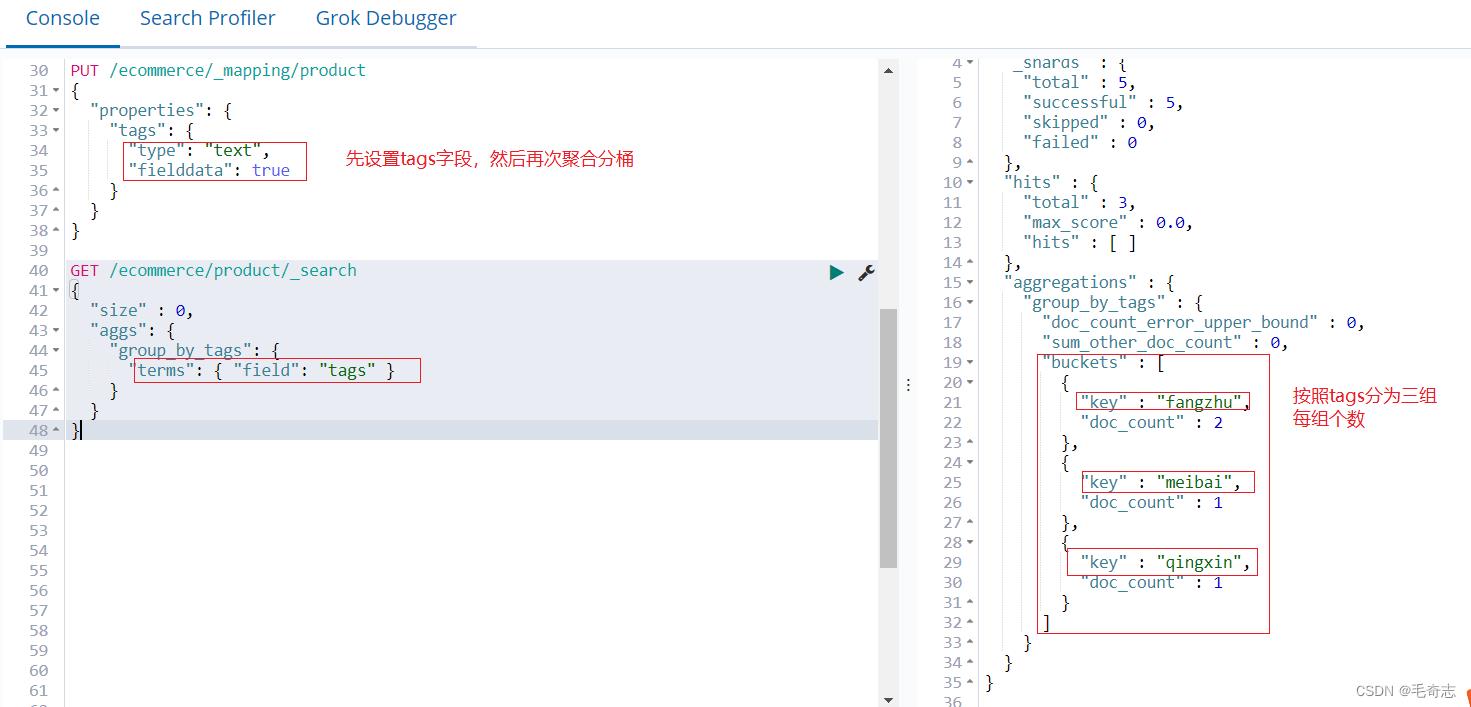
请求体中各个字段的含义
size:只获取聚合结果,而不要执行聚合的原始数据
aggs:固定语法,要对一份数据执行分组聚合操作
gourp_by_tags:就是对每个aggs,都要起一个名字,这个名字是随机的,你随便取什么都ok
terms:根据字段的值进行分组
field:根据指定的字段的值进行分组将文本
返回体中各个字段的含义
hits.hits:我们指定了size是0,所以hits.hits就是空的,否则会把执行聚合的那些原始数据给你返回回来
aggregations:聚合结果
gourp_by_tags:我们指定的某个聚合的名称
buckets:根据我们指定的field划分出的buckets
key:每个bucket对应的那个值
doc_count:这个bucket分组内,有多少个数据
每种tag对应的bucket中的数据的
默认的排序规则:按照doc_count降序排序
二、按搜索结果聚合
2.1 对名称中包含yagao的商品,计算每个tag下的商品数量
需求:对名称中包含yagao的商品,计算每个tag下的商品数量
GET /ecommerce/product/_search
"size": 0,
"query":
"match":
"name": "yagao"
,
"aggs":
"all_tags":
"terms":
"field": "tags"

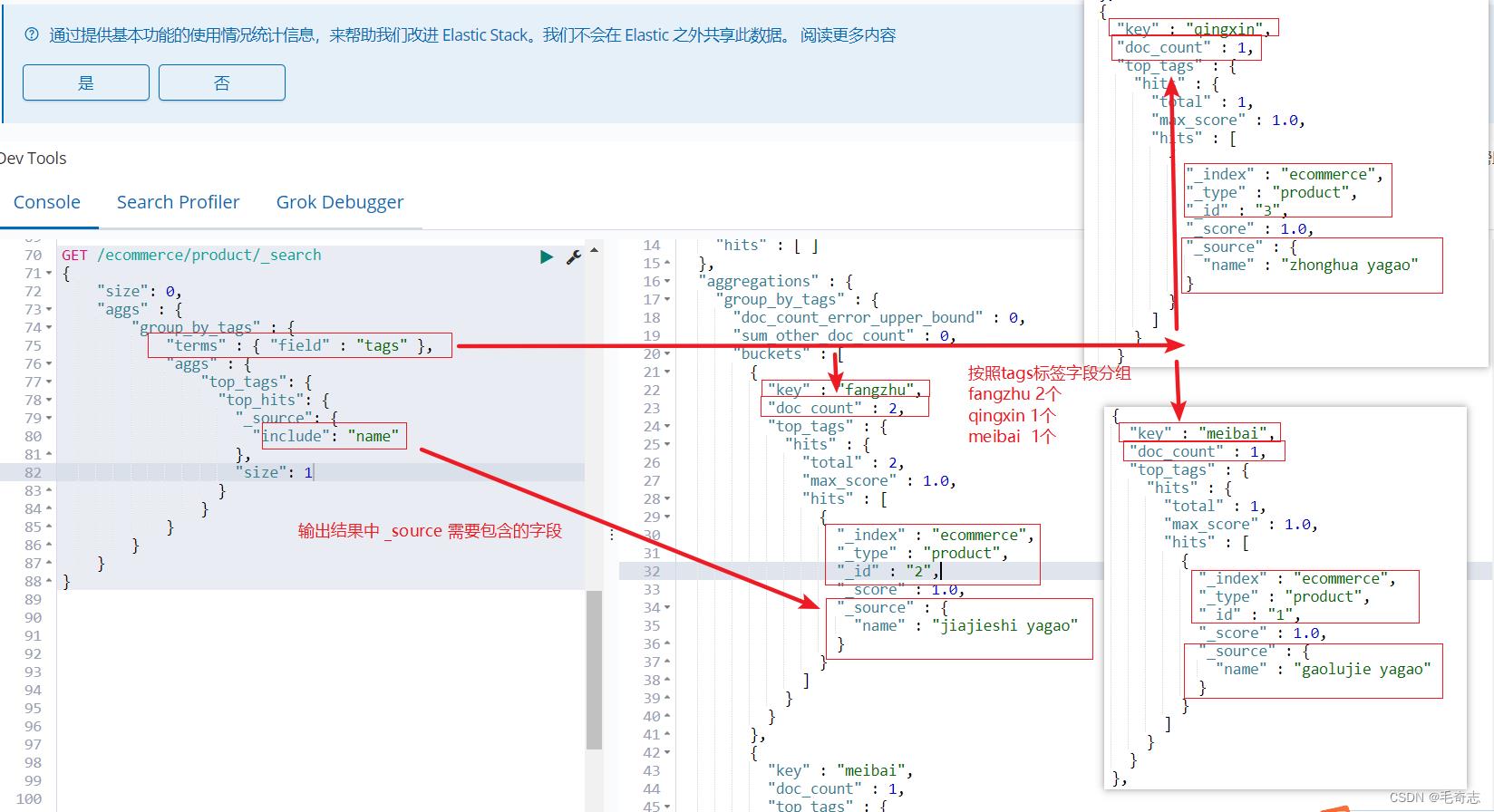
2.2 对名称中包含yagao的商品,计算每个tag下的商品数量,返回需要的字段
GET /ecommerce/product/_search
"size": 0,
"aggs" :
"group_by_tags" :
"terms" : "field" : "tags" ,
"aggs" :
"top_tags":
"top_hits":
"_source":
"include": "name"
,
"size": 1
2.3 计算每个tag下的商品的平均价格/最小价格/最大价格/总价
计算每个tag下的商品的平均价格/最小价格/最大价格/总价
count:bucket,terms,自动就会有一个doc_count,就相当于是count
avg:avg aggs,求平均值
max:求一个bucket内,指定field值最大的那个数据
min:求一个bucket内,指定field值最小的那个数据
sum:求一个bucket内,指定field值的总和先分组,再算每组的平均值
GET /ecommerce/product/_search
"size": 0,
"aggs" :
"group_by_tags" :
"terms" : "field" : "tags" ,
"aggs" :
"avg_price": "avg": "field": "price" ,
"min_price" : "min": "field": "price" ,
"max_price" : "max": "field": "price" ,
"sum_price" : "sum": "field": "price"

三、collect_mode
对于子聚合的计算,有两种方式:
方式1:depth_first 直接进行子聚合的计算 【深度优先】
方式2:breadth_first 先计算出当前聚合的结果,针对这个结果在对子聚合进行计算。【广度优先】
3.1 子聚合的计算两种方式
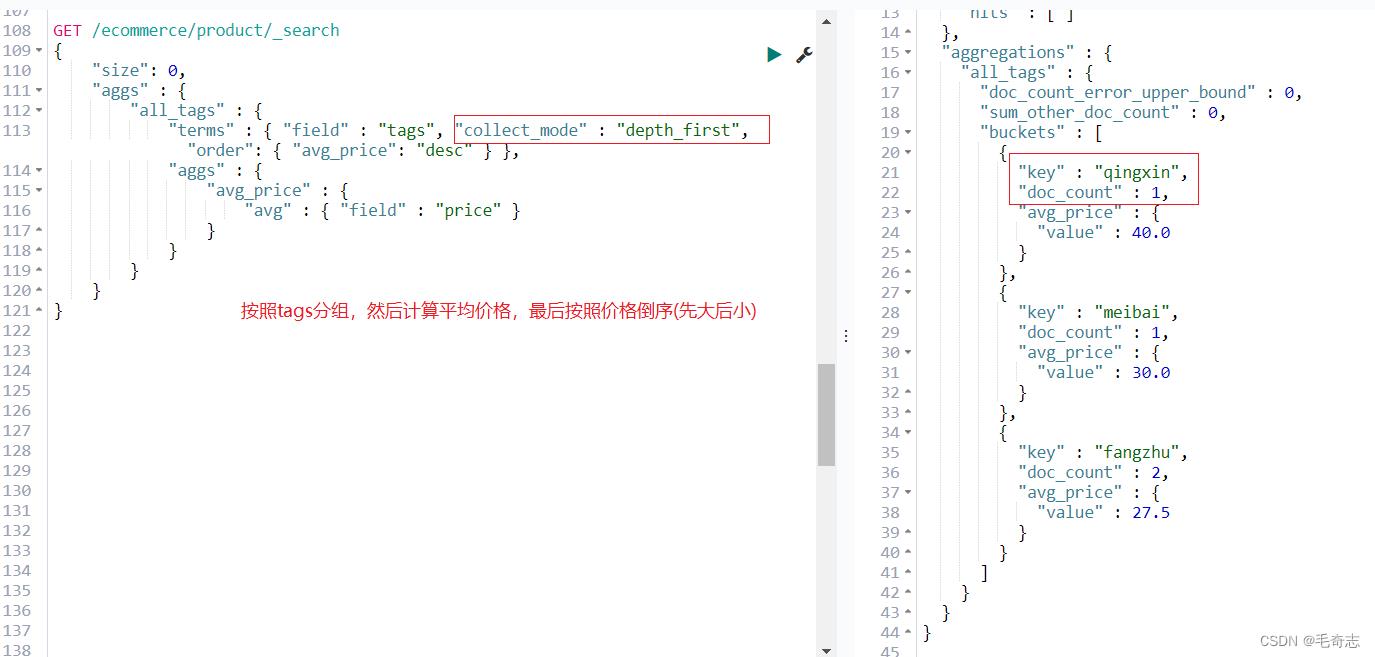
例子:计算每个tag下的商品的平均价格,并且按照平均价格降序排序
“order”: “avg_price”: “desc”
1、depth_first 直接进行子聚合的计算
GET /ecommerce/product/_search
"size": 0,
"aggs" :
"all_tags" :
"terms" : "field" : "tags", "collect_mode" : "depth_first", "order": "avg_price": "desc" ,
"aggs" :
"avg_price" :
"avg" : "field" : "price"
2、breadth_first 先计算出当前聚合的结果,针对这个结果在对子聚合进行计算
GET /ecommerce/product/_search
"size": 0,
"aggs" :
"all_tags" :
"terms" : "field" : "tags", "collect_mode" : "breadth_first", "order": "avg_price": "desc" ,
"aggs" :
"avg_price" :
"avg" : "field" : "price"

3.2 tags分组前面先范围分组
GET /ecommerce/product/_search
"size": 0,
"aggs":
"group_by_price":
"range":
"field": "price",
"ranges": [
"from": 0,
"to": 20
,
"from": 20,
"to": 40
,
"from": 40,
"to": 50
]
,
"aggs":
"group_by_tags":
"terms":
"field": "tags"
,
"aggs":
"average_price":
"avg":
"field": "price"

四、histogram 和 date histogram 间隔范围分组
4.1 histogram 范围分组
类似于terms,也是进行bucket分组操作,接收一个field,按照这个field的值的各个范围区间,进行bucket分组操作
interval:10,划分范围,0 ~ 10,10 ~ 20,20 ~ 30
GET /ecommerce/product/_search
"size" : 0,
"aggs":
"price":
"histogram":
"field": "price",
"interval": 10
,
"aggs":
"revenue":
"sum":
"field" : "price"
这里的 revenue 仅仅是聚合名称,没有实际意义

4.2 date histogram
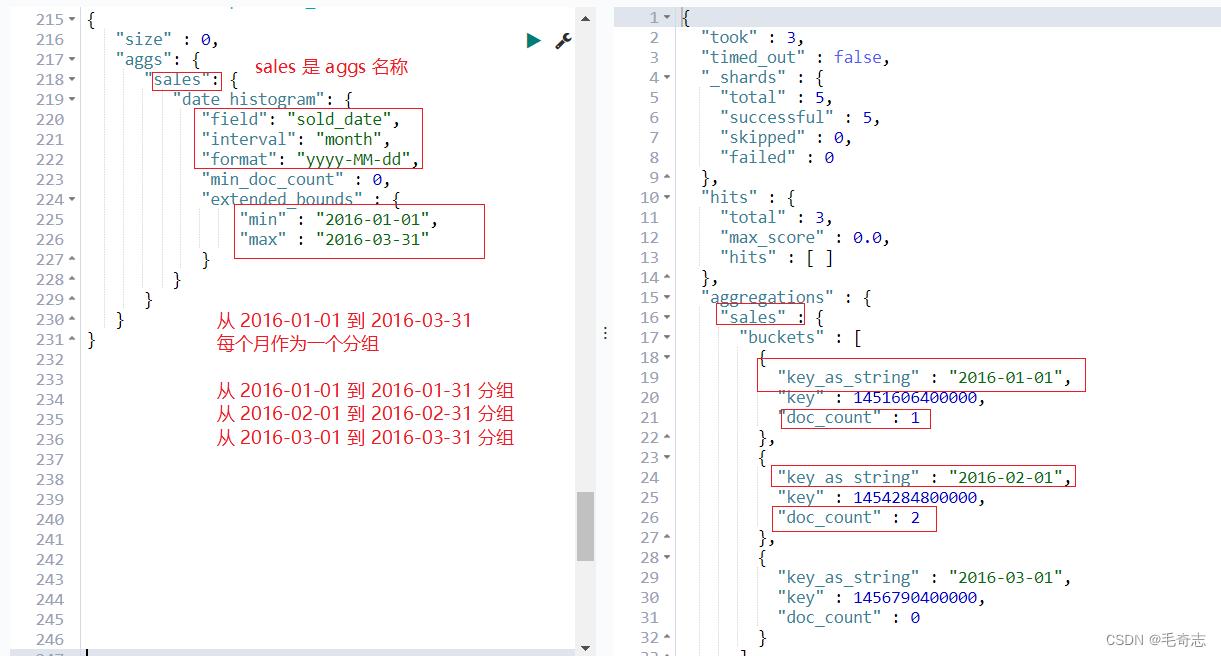
date histogram 日期分组,按照我们指定的某个date类型的日期field,以及日期interval,按照一定的日期间隔,去划分bucket
date interval = 1m,
2017-01-01~2017-01-31,就是一个bucket
2017-02-01~2017-02-28,就是一个bucket
然后会去扫描每个数据的date field,判断date落在哪个bucket中,就将其放入那个bucket
min_doc_count:即使某个日期interval,2017-01-01~2017-01-31中,一条数据都没有,那么这个区间也是要返回的,不然默认是会过滤掉这个区间的
extended_bounds,min,max:划分bucket的时候,会限定在这个起始日期,和截止日期内
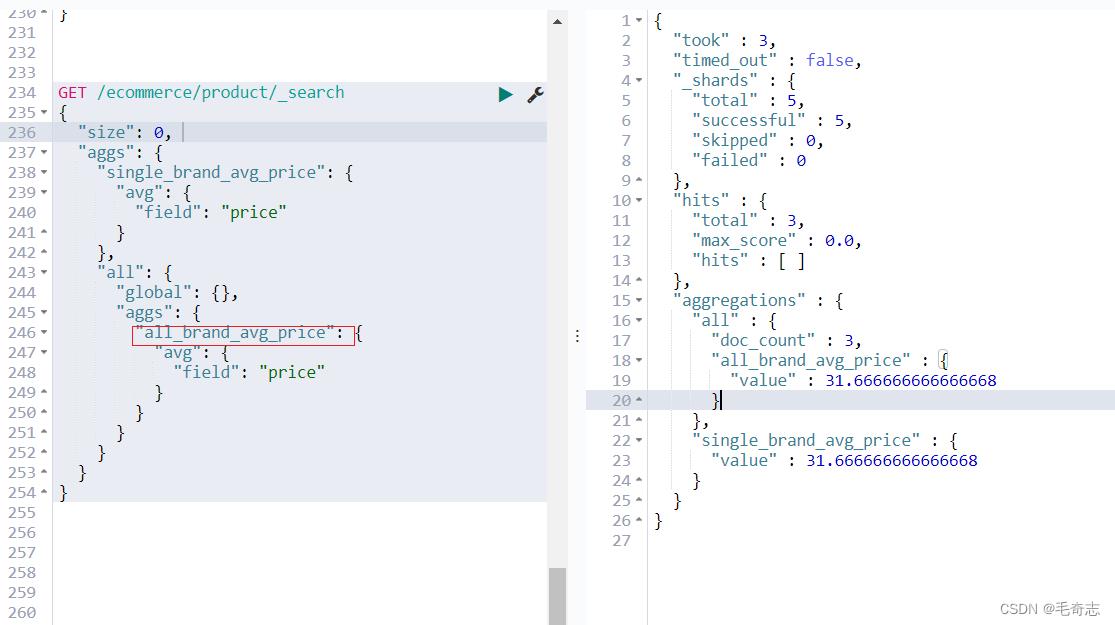
aggregation,scope,一个聚合操作,必须在query的搜索结果范围内执行出来两个结果,一个结果,是基于query搜索结果来聚合的; 一个结果,是对所有数据执行聚合的
修改三个document,如下:
PUT /ecommerce/product/1
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ],
"sold_date": "2016-01-15"
PUT /ecommerce/product/2
"name" : "jiajieshi yagao",
"desc" : "youxiao fangzhu",
"price" : 25,
"producer" : "jiajieshi producer",
"tags": [ "fangzhu" ],
"sold_date": "2016-02-15"
PUT /ecommerce/product/3
"name" : "zhonghua yagao",
"desc" : "caoben zhiwu",
"price" : 40,
"producer" : "zhonghua producer",
"tags": [ "qingxin" ],
"sold_date": "2016-02-20"
GET _search

GET /ecommerce/product/_search
"size" : 0,
"aggs":
"sales":
"date_histogram":
"field": "sold_date",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count" : 0,
"extended_bounds" :
"min" : "2016-01-01",
"max" : "2016-03-31"
五、global全局桶
就是global bucket,就是将所有数据纳入聚合的scope,而不管之前的query
GET /ecommerce/product/_search
"size": 0,
"aggs":
"single_brand_avg_price":
"avg":
"field": "price"
,
"all":
"global": ,
"aggs":
"all_brand_avg_price":
"avg":
"field": "price"
总结
本文所有的es操作语句:https://www.syjshare.com/res/PJ9F6DSN
以上是关于跟我学Elasticsearch(7) es的嵌套聚合,下钻分析,聚合分析的主要内容,如果未能解决你的问题,请参考以下文章
springboot 2.0集成elasticsearch 7.6.2(集群)
Elasticsearch es nested 嵌套类型 详解
[ElasticSearch]ES操作之嵌套查询(nested)与退出嵌套(reverse_nested)操作