OpenCV实现车牌识别,OCR分割,ANN神经网络
Posted 晴堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV实现车牌识别,OCR分割,ANN神经网络相关的知识,希望对你有一定的参考价值。
主要步骤:准备车牌单个字符图像作为神经网络分类器的训练数据,越多越好。当然需要对每幅图像提取特征,这里使用的是水平和垂直累计直方图和缩小后的图像信息。
获取车牌图像,这里的车牌图像已经完成抠图,并且是灰度图像。
将车牌图像中每个字符分割成单一图像(OCR类实现)。
提取分割出的字符图像特征信息,并使用分类识别字符(OCR类实现)。
程序运行过程:

原始带有车牌的图片

抠图并输入的车牌图片
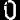


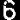

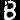
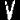
二值化并分割成单个字符图片

程序运行结果
代码:
#ifndef Plate_h
#define Plate_h
#include <string.h>
#include <vector>
#include <cv.h>
#include <highgui.h>
#include <cvaux.h>
using namespace std;
using namespace cv;
//车牌类
class Plate
public:
Plate();
Plate(Mat img, Rect pos);
string str();
Rect position;//当前车牌在大图的位置,为了把识别出的车牌号显示到原图的车牌位置处
Mat plateImg;//车牌图像,必须是灰度图像
vector<char> chars;
vector<Rect> charsPos;
;
#endif
#include "stdafx.h"
#include "Plate.h"
Plate::Plate()
Plate::Plate(Mat img, Rect pos)
plateImg=img;
position=pos;
//将车牌号码按照间隔长短拼接成字符串
string Plate::str()
string result="";
//Order numbers
vector<int> orderIndex;
vector<int> xpositions;
for(int i=0; i< charsPos.size(); i++)
orderIndex.push_back(i);
xpositions.push_back(charsPos[i].x);
float min=xpositions[0];
int minIdx=0;
for(int i=0; i< xpositions.size(); i++)
min=xpositions[i];
minIdx=i;
for(int j=i; j<xpositions.size(); j++)
if(xpositions[j]<min)
min=xpositions[j];
minIdx=j;
int aux_i=orderIndex[i];
int aux_min=orderIndex[minIdx];
orderIndex[i]=aux_min;
orderIndex[minIdx]=aux_i;
float aux_xi=xpositions[i];
float aux_xmin=xpositions[minIdx];
xpositions[i]=aux_xmin;
xpositions[minIdx]=aux_xi;
for(int i=0; i<orderIndex.size(); i++)
result=result+chars[orderIndex[i]];
return result;
#ifndef OCR_h
#define OCR_h
#include <string.h>
#include <vector>
#include "Plate.h"
#include <cv.h>
#include <highgui.h>
#include <cvaux.h>
#include <ml.h>
using namespace std;
using namespace cv;
#define HORIZONTAL 1
#define VERTICAL 0
class CharSegment
public:
CharSegment();
CharSegment(Mat i, Rect p);
Mat img;
Rect pos;
;
class OCR
public:
bool DEBUG;
bool saveSegments;
string filename;
static const int numCharacters;//字符个数
static const char strCharacters[];//字符数组
OCR(string trainFile);
OCR();
string run(Plate *input);//识别车牌
int charSize;
Mat preprocessChar(Mat in);//将字符图片调整为正方形
int classify(Mat f);//根据特征识别出每个字符图片的字符
void train(Mat trainData, Mat trainClasses, int nlayers);//训练分类器
int classifyKnn(Mat f);//扩展的Knn分类器
void trainKnn(Mat trainSamples, Mat trainClasses, int k);
Mat features(Mat input, int size);//提取每幅字符图片的特征
private:
bool trained;
vector<CharSegment> segment(Plate input);//分割车片图片
Mat Preprocess(Mat in, int newSize);//缩放为正方形
Mat getVisualHistogram(Mat *hist, int type);//生成视觉直方图
void drawVisualFeatures(Mat character, Mat hhist, Mat vhist, Mat lowData);//绘制视觉直方图
Mat ProjectedHistogram(Mat img, int t);//计算累计直方图
bool verifySizes(Mat r);//判断字符图像大小是否合适
CvANN_MLP ann;//神经网络分类器
CvKNearest knnClassifier;//扩展的k邻域分类器
int K;
;
#endif
#include "stdafx.h"
#include "OCR.h"
const char OCR::strCharacters[] = '0','1','2','3','4','5','6','7','8','9','B', 'C', 'D', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'R', 'S', 'T', 'V', 'W', 'X', 'Y', 'Z';
const int OCR::numCharacters=30;
CharSegment::CharSegment()
CharSegment::CharSegment(Mat i, Rect p)
img=i;
pos=p;
OCR::OCR()
DEBUG=false;
trained=false;
saveSegments=false;
charSize=20;
OCR::OCR(string trainFile)
DEBUG=false;
trained=false;
saveSegments=false;
charSize=20;
//Read file storage.
FileStorage fs;
fs.open("OCR.xml", FileStorage::READ);
Mat TrainingData;
Mat Classes;
fs["TrainingDataF15"] >> TrainingData;
fs["classes"] >> Classes;
train(TrainingData, Classes, 10);
//将单个字符图像变成正方形
Mat OCR::preprocessChar(Mat in)
int h=in.rows;
int w=in.cols;
Mat transformMat=Mat::eye(2,3,CV_32F);//缩放矩阵
int m=max(w,h);
transformMat.at<float>(0,2)=m/2 - w/2;
transformMat.at<float>(1,2)=m/2 - h/2;
Mat warpImage(m,m, in.type());
warpAffine(in, warpImage, transformMat, warpImage.size(), INTER_LINEAR, BORDER_CONSTANT, Scalar(0) );
Mat out;
resize(warpImage, out, Size(charSize, charSize) );
return out;
//判断字符图像长宽是否符合要求
bool OCR::verifySizes(Mat r)
//Char sizes 45x77
float aspect=45.0f/77.0f;
float charAspect= (float)r.cols/(float)r.rows;
float error=0.35;
float minHeight=15;
float maxHeight=28;
//We have a different aspect ratio for number 1, and it can be ~0.2
float minAspect=0.2;
float maxAspect=aspect+aspect*error;
//area of pixels
float area=countNonZero(r);
//bb area
float bbArea=r.cols*r.rows;
//% of pixel in area
float percPixels=area/bbArea;
if(DEBUG)
cout << "Aspect: "<< aspect << " ["<< minAspect << "," << maxAspect << "] " << "Area "<< percPixels <<" Char aspect " << charAspect << " Height char "<< r.rows << "\\n";
if(percPixels < 0.8 && charAspect > minAspect && charAspect < maxAspect && r.rows >= minHeight && r.rows < maxHeight)
return true;
else
return false;
//将车牌图像进一步分割成单个字符图片
vector<CharSegment> OCR::segment(Plate plate)
Mat input=plate.plateImg;
vector<CharSegment> output;
//将输入图像二值化
Mat img_threshold;
threshold(input, img_threshold, 60, 255, CV_THRESH_BINARY_INV);
if(DEBUG)
imshow("Threshold plate", img_threshold);
Mat img_contours;
img_threshold.copyTo(img_contours);
//查找字符轮廓
vector< vector< Point> > contours;
findContours(img_contours,
contours, // 轮廓
CV_RETR_EXTERNAL, //去除内环
CV_CHAIN_APPROX_NONE); // 轮廓所有像素
//将轮廓绘制到车牌图
cv::Mat result;
img_threshold.copyTo(result);
cvtColor(result, result, CV_GRAY2RGB);
cv::drawContours(result,contours,-1,cv::Scalar(255,0,0),1);
vector<vector<Point> >::iterator itc= contours.begin();
//筛选符合条件的闭环
while (itc!=contours.end())
//创建一个包围矩形
Rect mr= boundingRect(Mat(*itc));
rectangle(result, mr, Scalar(0,255,0));
Mat auxRoi(img_threshold, mr);
if(verifySizes(auxRoi))//判断长宽是否满足
auxRoi=preprocessChar(auxRoi);//缩放成正方形
output.push_back(CharSegment(auxRoi, mr));//保存字符图像及位置
rectangle(result, mr, Scalar(0,125,255));
++itc;
if(DEBUG)
cout << "Num chars: " << output.size() << "\\n";
if(DEBUG)
imshow("SEgmented Chars", result);
return output;
//计算累计直方图,统计每列或行的非0像素个数
Mat OCR::ProjectedHistogram(Mat img,int t)
int sz=(t)?img.rows:img.cols;
Mat mhist=Mat::zeros(1,sz,CV_32F);
for(int j=0; j<sz; j++)
Mat data=(t)?img.row(j):img.col(j);
mhist.at<float>(j)=countNonZero(data);//
//直方图归1化
double min, max;
minMaxLoc(mhist, &min, &max);
if(max>0)
mhist.convertTo(mhist,-1 , 1.0f/max, 0);
return mhist;
//得到直方图图像
Mat OCR::getVisualHistogram(Mat *hist, int type)
int size=100;
Mat imHist;
if(type==HORIZONTAL)
imHist.create(Size(size,hist->cols), CV_8UC3);
else
imHist.create(Size(hist->cols, size), CV_8UC3);
imHist=Scalar(55,55,55);
for(int i=0;i<hist->cols;i++)
float value=hist->at<float>(i);
int maxval=(int)(value*size);
Point pt1;
Point pt2, pt3, pt4;
if(type==HORIZONTAL)
pt1.x=pt3.x=0;
pt2.x=pt4.x=maxval;
pt1.y=pt2.y=i;
pt3.y=pt4.y=i+1;
line(imHist, pt1, pt2, CV_RGB(220,220,220),1,8,0);
line(imHist, pt3, pt4, CV_RGB(34,34,34),1,8,0);
pt3.y=pt4.y=i+2;
line(imHist, pt3, pt4, CV_RGB(44,44,44),1,8,0);
pt3.y=pt4.y=i+3;
line(imHist, pt3, pt4, CV_RGB(50,50,50),1,8,0);
else
pt1.x=pt2.x=i;
pt3.x=pt4.x=i+1;
pt1.y=pt3.y=100;
pt2.y=pt4.y=100-maxval;
line(imHist, pt1, pt2, CV_RGB(220,220,220),1,8,0);
line(imHist, pt3, pt4, CV_RGB(34,34,34),1,8,0);
pt3.x=pt4.x=i+2;
line(imHist, pt3, pt4, CV_RGB(44,44,44),1,8,0);
pt3.x=pt4.x=i+3;
line(imHist, pt3, pt4, CV_RGB(50,50,50),1,8,0);
return imHist ;
void OCR::drawVisualFeatures(Mat character, Mat hhist, Mat vhist, Mat lowData)
Mat img(121, 121, CV_8UC3, Scalar(0,0,0));
Mat ch;
Mat ld;
cvtColor(character, ch, CV_GRAY2RGB);
resize(lowData, ld, Size(100, 100), 0, 0, INTER_NEAREST );
cvtColor(ld,ld,CV_GRAY2RGB);
Mat hh=getVisualHistogram(&hhist, HORIZONTAL);
Mat hv=getVisualHistogram(&vhist, VERTICAL);
Mat subImg=img(Rect(0,101,20,20));
ch.copyTo(subImg);
subImg=img(Rect(21,101,100,20));
hh.copyTo(subImg);
subImg=img(Rect(0,0,20,100));
hv.copyTo(subImg);
subImg=img(Rect(21,0,100,100));
ld.copyTo(subImg);
line(img, Point(0,100), Point(121,100), Scalar(0,0,255));
line(img, Point(20,0), Point(20,121), Scalar(0,0,255));
imshow("Visual Features", img);
cvWaitKey(0);
Mat OCR::features(Mat in, int sizeData)
//分别获取垂直和水平直方图信息
Mat vhist=ProjectedHistogram(in,VERTICAL);
Mat hhist=ProjectedHistogram(in,HORIZONTAL);
//低分辨率图像
Mat lowData;
resize(in, lowData, Size(sizeData, sizeData) );//15x15
if(DEBUG)
drawVisualFeatures(in, hhist, vhist, lowData);
//整合低分辨路图像信息和直方图统计信息,
int numCols=vhist.cols+hhist.cols+lowData.cols*lowData.cols;
Mat out=Mat::zeros(1,numCols,CV_32F);
//保存特征信息
int j=0;
for(int i=0; i<vhist.cols; i++)
out.at<float>(j)=vhist.at<float>(i);
j++;
for(int i=0; i<hhist.cols; i++)
out.at<float>(j)=hhist.at<float>(i);
j++;
for(int x=0; x<lowData.cols; x++)
for(int y=0; y<lowData.rows; y++)
out.at<float>(j)=(float)lowData.at<unsigned char>(x,y);
j++;
if(DEBUG)
cout << out << "\\n===========================================\\n";
return out;
//训练 //训练样本数据//每条数据对应的字母下标//深度
void OCR::train(Mat TrainData, Mat classes, int nlayers)
Mat layers(1,3,CV_32SC1);
layers.at<int>(0)= TrainData.cols;//每个样本宽度
layers.at<int>(1)= nlayers;//深度
layers.at<int>(2)= numCharacters;//结果个数
ann.create(layers, CvANN_MLP::SIGMOID_SYM, 1, 1);
Mat trainClasses;
trainClasses.create( TrainData.rows, numCharacters, CV_32FC1 );//每一条样本都对应着numCharacters个可能结果,但是只有一个结果是正确的,
for( int i = 0; i < trainClasses.rows; i++ )
for( int k = 0; k < trainClasses.cols; k++ )
//将该条训练数据对应的字符下标位置赋值为1,其他赋值为0
if( k == classes.at<int>(i) )
trainClasses.at<float>(i,k) = 1;
else
trainClasses.at<float>(i,k) = 0;
Mat weights( 1, TrainData.rows, CV_32FC1, Scalar::all(1) );
//开始训练学习
ann.train( TrainData, trainClasses, weights );
trained=true;
//识别字符
int OCR::classify(Mat f)
int result=-1;
Mat output(1, numCharacters, CV_32FC1);
ann.predict(f, output);
Point maxLoc;
double maxVal;
minMaxLoc(output, 0, &maxVal, 0, &maxLoc);//求最大值以及下标位置,这里没有打印出来最大值
return maxLoc.x;
int OCR::classifyKnn(Mat f)
int response = (int)knnClassifier.find_nearest( f, K );
return response;
void OCR::trainKnn(Mat trainSamples, Mat trainClasses, int k)
K=k;
// learn classifier
knnClassifier.train( trainSamples, trainClasses, Mat(), false, K );
string OCR::run(Plate *input)
//分割车牌中每个字符
vector<CharSegment> segments=segment(*input);
for(int i=0; i<segments.size(); i++)
//统一所有字符图像大小
Mat ch=preprocessChar(segments[i].img);
if(saveSegments)
stringstream ss(stringstream::in | stringstream::out);
ss << "tmpChars/" << filename << "_" << i << ".jpg";
imwrite(ss.str(),ch);
//提取每个字符图像特征
Mat f=features(ch,15);
//For each segment feature Classify
int character=classify(f);
input->chars.push_back(strCharacters[character]);
input->charsPos.push_back(segments[i].pos);
return "-";//input->str();
#include "stdafx.h"
#include <cv.h>
#include <highgui.h>
#include <cvaux.h>
#include <ml.h>
#include <iostream>
#include <vector>
#include "DetectRegions.h"
#include "OCR.h"
using namespace std;
using namespace cv;
string getFilename(string s)
char sep = '/';
char sepExt = '.';
#ifdef _WIN32
sep = '\\\\';
#endif
size_t i = s.rfind(sep, s.length());
if (i != string::npos)
string fn = (s.substr(i + 1, s.length() - i));
size_t j = fn.rfind(sepExt, fn.length());
if (i != string::npos)
return fn.substr(0, j);
else
return fn;
else
return "";
int main(int argc, char** argv)
char* filename;
Mat input_image;//必须为灰度图像
//有输入图片才继续
if (argc >= 2)
filename = argv[1];
input_image = imread(filename, 1);
else
printf("Use:\\n\\t%s image\\n", argv[0]);
return 0;
string filename_whithoutExt = getFilename(filename);//得到去除后缀部分
OCR ocr("OCR.xml");//参数为保存了自己训练数据的xml文件
ocr.saveSegments = true;
ocr.DEBUG = true;
ocr.filename = filename_whithoutExt;
Plate plate;
plate.plateImg = input_image;
plate.position = Rect(50, 100, input_image.cols, input_image.rows);//车牌是从大图中抠图出来的,这里说明车牌的位置和大小
imwrite("plateImg.jpg", plate.plateImg);
string plateNumber = ocr.run(&plate);
string licensePlate = plate.str();
cout << "================================================\\n";
cout << "License plate number: " << licensePlate << "\\n";
cout << "================================================\\n";
rectangle(input_image, plate.position, Scalar(0, 0, 200));
putText(input_image, licensePlate, Point(plate.position.x, plate.position.y), CV_FONT_HERSHEY_SIMPLEX, 1, Scalar(0, 0, 200), 2);
if (false)
imshow("Plate Detected seg", plate.plateImg);
cvWaitKey(0);
imshow("Plate Detected", input_image);
for (;;)
int c;
c = cvWaitKey(10);
if ((char)c == 27)
break;
return 0;
有关ANN神经网络分类器的原理及训练请参考我的另一篇文章:http://blog.csdn.net/xukaiwen_2016/article/details/53293465
最后:例子中没有实现对中文的识别,其实原理都是一样的,大家可以自己寻找中文车牌的图片进行分类器训练即可,代码几乎不用修改。
需要代码以及分类器训练数据xml文件的话,评论留下邮箱。
以上是关于OpenCV实现车牌识别,OCR分割,ANN神经网络的主要内容,如果未能解决你的问题,请参考以下文章