数据挖掘方法系列数据探索
Posted xiaotangqiu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘方法系列数据探索相关的知识,希望对你有一定的参考价值。
为什么要做数据探索?
了解数据的类型和人与人沟通过程中了解对方的性别一样重要,人与人沟通知道对方的性别才能用不同的方式与其沟通,不同的数据类型能做的操作也不一样。
探索数据探索哪些?数据的类型和数据的质量。
数据类型分为定性和定量的。
定性也可以说是分类的,包括标称和序数。标称很好理解,用户ID、用户的名称也属于标称,虽然也可以重复,但大致还是能代表一个个体;序数有类型{好,非常好,超级好},可以比较大小的,比如“超级好好”比“好”在好的程度要高,{高,较高,非常高}也属于序数。
定量可以说是连续的,包括区间和比率。区间是可以做差操作的。比如日期,可以求日期之间的区间,今年和去年相差一年;比率既可以求区间,又可以求比率。比如年龄是比率,20岁比30岁年轻10岁,还可以求年龄的均值,。
数据类型除了这种分类还有别的分类,但这样的分类是基础分类,掌握了就可以以不变应万变了。
数据的质量主要有:属性值缺失、对象重复、离群点、数据不一致以及数据错误。造成这些数据质量问题的原因有很多,比如操作员手工录入时发生错误、用户填写时造成的笔误和精准偏差(对一个问题的理解不到位或问卷设计不合理)、再比如传感器收集时失灵等问题。目前,很少有企业一开始收集大量的数据是为做挖掘,基本都是数据积累到一定量然后有了做挖掘的需求,不管是从数据还是从业务驱动上来说都是这样的,这样数据可能分散在各个业务系统中,缺失、不一致问题必然存在,需要通过各种预处理手段,将数据的质量提升到一定高度。
那么问题来了,如何做数据探索呢?
前面说了,需要探索数据类型和数据质量,接下来就讲运用两种工具来探索数据,商用数据挖掘软件IBM SPSS Modeler以及python语言。
IBM SPSS Modeler现在是IBM公司的一款数据挖掘工具,它能用拖拉拽的方式实现数据挖掘建模。使用方法在这里不介绍,只介绍探索的结果。
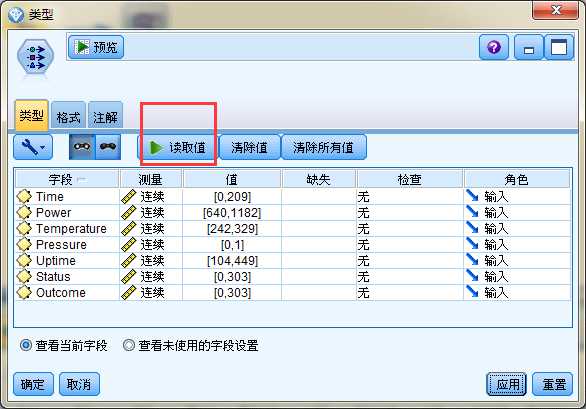
这是探索字段的数据类型,连续型,值范围,以及是否有缺失。
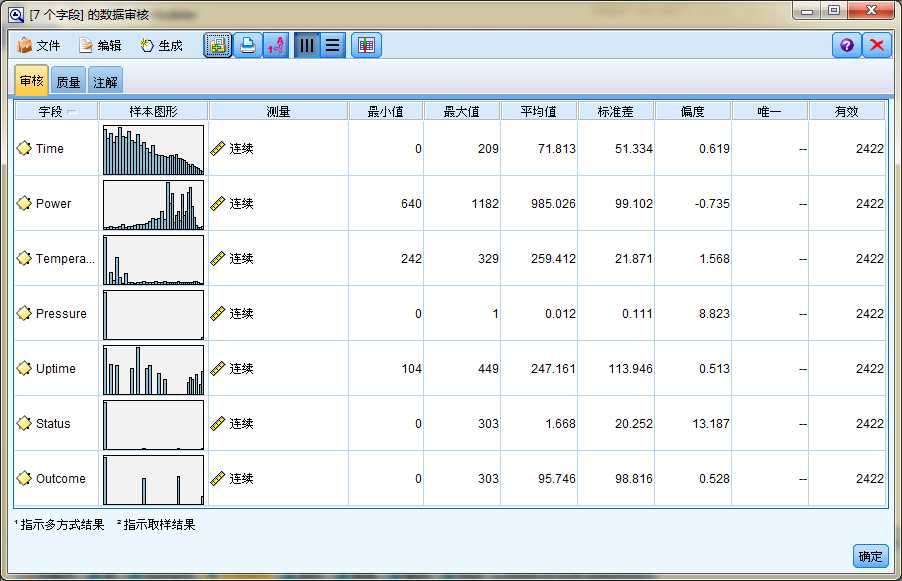
下面是探索数据质量,分为数据的描述统计信息和质量评估。
描述统计包括图形化/数据类型/最小值/最大值/平均值/标准差/偏度/是否唯一/有效值等等这些指标;
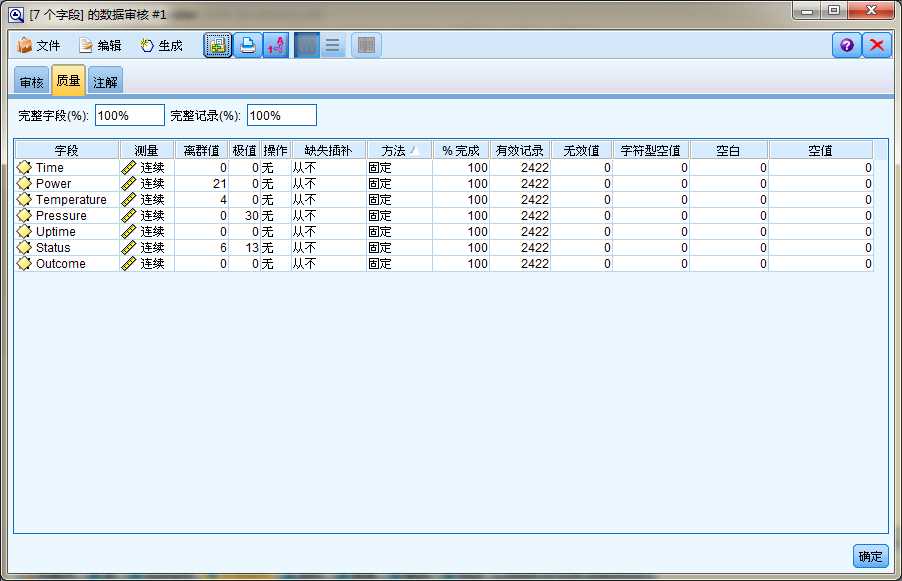
质量评估包括离群值/极值/完成率/有效记录数/无效值个数/字符型空值个数/空白个数/控制个数等
modeler是目前为止我用过的挖掘工具中最好的入门工具,尽管数据处理功能和支持挖掘算法不属于最多的,执行效率也不是最高的,但好在简单易懂;如果是公司内部使用有版权风险,或者是大数据量又穷那就还是用python吧。
Python语言是一门开源的编程语言,其中有很多大神贡献了很多模块,我们直接导入模块,就可以运用模块的功能,虽然是编程语言,但是学习成本真的很低,很多功能都是拿来就可以用。
#导入各个模块
from sklearn import datasets #导入机器学习库中的数据集
import pandas as pd #导入pandas模块,用来处理数据,
iris=datasets.load_iris()
iris_X=iris.data
iris_Y=iris.target
iris_X1=pd.DataFrame(iris_X)
iris_Y1=pd.Series(iris_Y) #因为下面用的数据探索的函数只有pandas中的DataFrame,Series
print(X1.describe(),X1.head(),X1.corr(),X1.corrwith(y1)) #引用数据探索的函数
工具永远都只是工具,只能帮助我们工作,不能替代我们思考,只有不断思考知道需要做什么,怎么做才能进步~
以上是关于数据挖掘方法系列数据探索的主要内容,如果未能解决你的问题,请参考以下文章