爬取网页
Posted henuliulei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取网页相关的知识,希望对你有一定的参考价值。
下面以爬取360浏览器网页为例,代码具有通用性,改变网页路径即可
代码如下
package 爬取网页;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.MalformedURLException;
import java.net.URL;
public class Main {
public static void main(String[] args) throws Exception {
URL url=new URL("https://hao.360.cn/?h_lnk");//获取网址
BufferedReader bufferedReader=new BufferedReader(new InputStreamReader(url.openStream(),"utf-8"));//根据网页编码方式
String msg=null;
BufferedWriter bufferedWriter=new BufferedWriter(new OutputStreamWriter(new FileOutputStream("C:/a/360.html"),"utf-8"));
while((msg=bufferedReader.readLine())!=null) {
//System.out.println(msg);
bufferedWriter.append(msg);
bufferedWriter.newLine();
}
bufferedWriter.flush();
bufferedReader.close();
bufferedWriter.close();
}
}
运行代码后在C盘的a文件夹里面会有360.html文件,点击进入360网页
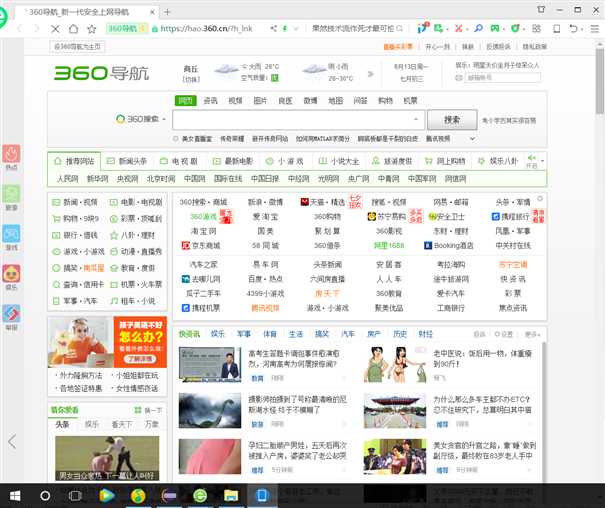
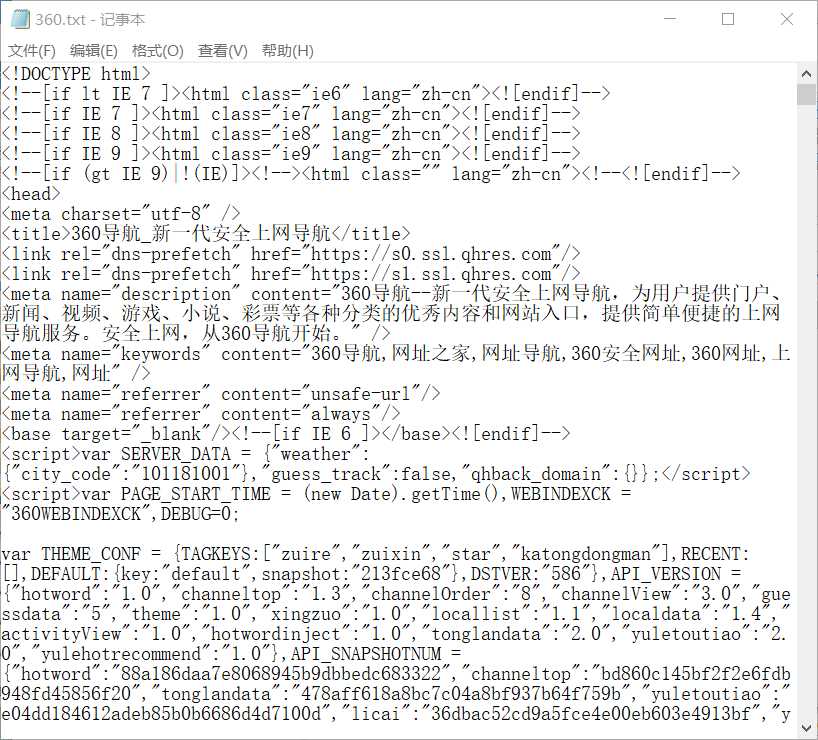
改变文件格式为txt可以查看网页源代码
以上是关于爬取网页的主要内容,如果未能解决你的问题,请参考以下文章