怎样用爬取网页中的pdf的内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎样用爬取网页中的pdf的内容相关的知识,希望对你有一定的参考价值。
可以借助一些采集工具实现批量采集网页中的文档链接,再利用工具下载文档后转格式复制粘贴 参考技术A 文字的话,先截屏保存,再用ocr软件识别。python怎样抓取网页中的文字和数字数据
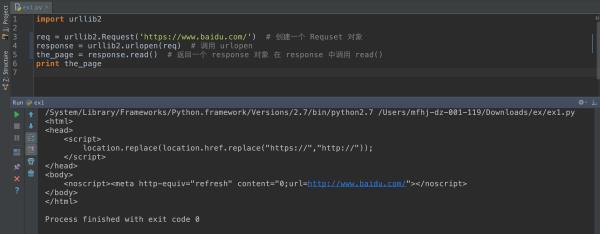
以下代码在 py2 下运行通过:
import urllib2req = urllib2.Request('https://www.baidu.com/') # 创建一个 Requset 对象
response = urllib2.urlopen(req) # 调用 urlopen
the_page = response.read() # 返回一个 response 对象 在 response 中调用 read()
print the_page
运行效果:
以上是关于怎样用爬取网页中的pdf的内容的主要内容,如果未能解决你的问题,请参考以下文章