XML解析方法分为两种:DOM方式和SAX方式
DOM:Document Object Model,文档对象模型。这种方式是W3C推荐处理XML的一种方式
SAX:Simple API for XML。该方式不是官方标准,属于开源社区XML-DEV
XML解析开发包
JAXP:SUN公司推出的解析标准实现
Dom4J:开源组织推出的解析开发包
JDOM:同上
JAXP:(Java API for XML Processing)开发包是JavaSE的一部分,它由以下几个包及其子包组成
org.w3c.dom:提供DOM方方式解析XML的标准接口
org.xml.sax:提供SAX方式解析XML的标准接口
javax.xml:提供了解析XML文档的类
javax.xml.parsers包中,定义了几个工厂类。我们可以通过调用这些工厂类,得到对XML文档进行解析的DOM和SAX解析器对象。
DocumentBuilderFactory
SAXParersFactory
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
利用JAXP继续DOM解析
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
javax.xml.parsers包中的DocumentBuilderFactory用于创建DOM模式的解析器对象,DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance()方法
,这个方法会根据本地默认安装的解析器自动创建一个工厂对象并返回
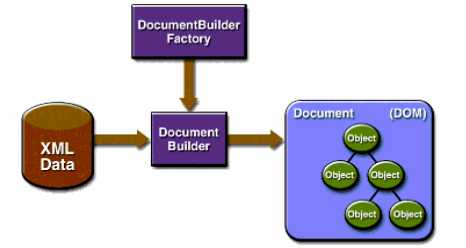
DOM方式解析会读取完整个XML文档,在内存中构建代表整个DOM树的Document对象,从而再对XML文档进行操作:增、删、改、查
如果文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。
获得JAXP中的DOM解析器
--->调用DocumentBuilderFactory.newInstance()方法得到创建DOM解析器的工厂
--->调用工厂对象的newDocumentBuilder()方法得到DOM解析器对象
--->调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象,进而可以利用DOM特性对整个XML文档继续操作。

1 /*固定写法*/
2 //得到解析工厂DocumentBuilderFactory
3 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
4
5 //得到解析器
6 DocumentBuilder builder = factory.newDocumentBuilder();
7
8 //解析指定的XML文档
9 Document document = builder.parse("src/book.xml");
DOM模型(document object model)
DOM解析器在解析XML文档时,会把文档中的所有元素,按照其出现的层次关系,解析成一个个Node对象节点
在dom中,节点之间的关系如下:
- 位于一个节点之上的节点是该节点的父节点(parent)
- 一个节点之下的节点是该节点的子节点(children)
- 在同一层次,具有相同父节点的节点是兄弟节点(sibling)
- 一个节点的下一个层次的节点集合是节点后代(descendant)
- 父、祖父节点以及所有位于节点的上面的,都是节点的祖先(ancestor)
节点的类型
Node对象提供了一系列常量来代表节点的类型,当开发人员获得某个Node类型之后,就可以把Node节点转换成相应的节点对象(Node的子类对象),以便调用其特有的方法
Node对象提供了相应的方法区获取它的父节点或子节点。编程人员通过这些方法可以读取整个XML文档的内容、或添加、修改、删除XML文档的内容
如何更新XML文档
- javax.xml.transform包中de Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出。例如把XML文件应用样式表后转成一个html文档。利用这个对象
- 把Document对象又重新写入到XML文件中
- Transformer通过transform方法完成转换的操作,该方法接收一个源和一个目的地
- javax.xml.transform.dom.DOMSource类来关联要转换的Document对象
- 用javax.xml.transform.strem.StreamResult对象来表示数据的目的地
- Transformer对象提供TransformerFactory获得
-
1 // 把内存中Documeng树写回XML文件中 2 TransformerFactory facotry = TransformerFactory.newInstance(); 3 //创建factory实例 4 Transformer ts = facotry.newTransformer(); 5 ts.transform(new DOMSource(document), new StreamResult("src/book.xml")); 6 //将源写入到目的中去
1 import javax.xml.parsers.DocumentBuilder;
2 import javax.xml.parsers.DocumentBuilderFactory;
3 import javax.xml.transform.Transformer;
4 import javax.xml.transform.TransformerFactory;
5 import javax.xml.transform.dom.DOMSource;
6 import javax.xml.transform.stream.StreamResult;
7
8 import org.w3c.dom.Document;
9 import org.w3c.dom.Element;
10 import org.w3c.dom.Node;
11 import org.w3c.dom.NodeList;
12
13 //利用Jaxp进行DOm方式解析
14 public class JaxpDomDemo {
15
16 public static void main(String[] args) throws Exception {
17 // 得到解析工厂DocumentBuilderFactory
18 //得到解析工厂DocumentBuilderFacetory
19 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
20 // 得到解析器DocumentBuilder
21 DocumentBuilder builder = factory.newDocumentBuilder();
22 // 解析指定的XML文档,得到代表内存DOM树的Document对象
23 Document document = builder.parse("src/book.xml");
24 test3(document);
25 }
26
27 // 1、得到某个具体的节点内容:打印第2本书的作者
28 public static void test1(Document document) {
29 // 根据标签的名称获取所有的作者元素
30 NodeList nl = document.getElementsByTagName("作者");
//Nodelist getElementByTagName(Stirng tagname按文档顺序返回包含文档中且具有给定标记名称的所有Element的NodeList
31
// 按照索引取第2个作者元素 NodeList 有两个主要的方法Node item(int index) 返回集合中的第index个项,如果index大于或等于此列表的索引则返回null
//int getLength()返回列表的节点数。有效子节点索引的范围是0到length-1
32 Node node = nl.item(1);
33 // 打印该元素的文本
34 String text = node.getTextContent(); //node有许多操作方法 getTextContent()方法返回此节点及其后代的文本相关内容
35 System.out.println(text);
36 }
37
38 // 2、遍历所有元素节点:打印元素的名称
39 public static void test2(Node node) {
40 // 判断当前节点是不是一个元素节点
41 if (node.getNodeType() == Node.ELEMENT_NODE) {
42 // 如果是:打印他的名称
43 System.out.println(node.getNodeName());
44 }
45 // 如果不是:找到他的孩子们
46 NodeList nl = node.getChildNodes(); //NodeList getChildNodes()包含此节点的NodeList。如果不存在,这是不包含节点的NodeList
47 int len = nl.getLength();
48 for (int i = 0; i < len; i++) {
49 // 遍历孩子们:递归
50 Node n = nl.item(i);
51 test2(n);
52 }
53 }
54
55 // 3、修改某个元素节点的主体内容:把第一本书的售价改为38.00元
56 public static void test3(Document document) throws Exception {
57 // 找到第一本书的售价
58 NodeList nl = document.getElementsByTagName("售价");
59 // 设置其主体内容
60 Node node = nl.item(0);
61 node.setTextContent("39.00元");
62 // 把内存中Documeng树写回XML文件中
63 TransformerFactory facotry = TransformerFactory.newInstance();
64 //创建factory实例
65 Transformer ts = facotry.newTransformer();
66 ts.transform(new DOMSource(document), new StreamResult("src/book.xml"));
67 //将源写入到目的中去
68
69 }
70
71 // 4、向指定元素节点中增加子元素节点:第一本中增加子元素<内部价>99.00</内部价>
72 public static void test4(Document document) throws Exception {
73 // 创建一个新的元素并设置其主体内容
74 Element e = document.createElement("内部价");
75 e.setTextContent("99.00元");
76 // 找到第一本书元素
77 Node firstBookNode = document.getElementsByTagName("书").item(0);
78 // 把新节点挂接到第一本书上
79 firstBookNode.appendChild(e);
80 // 把内存中Documeng树写回XML文件中
81 TransformerFactory facotry = TransformerFactory.newInstance();
82 Transformer ts = facotry.newTransformer();
83 ts.transform(new DOMSource(document), new StreamResult("src/book.xml"));
84 }
85
86 // 5、向指定元素节点上增加同级元素节点:在第一本书的售价前面增加批发价
87 public static void test5(Document document) throws Exception {
88 // 创建一个新的元素并设置其中的主体内容
89 Element e = document.createElement("批发价");
90 e.setTextContent("58.00元");
91 // 找到第一本书的售价
92 Node firstPrice = document.getElementsByTagName("售价").item(0);
93 // 在售价的前面加入新建的元素:增加子元素一定要使用父元素来做
94 firstPrice.getParentNode().insertBefore(e, firstPrice); //增加子元素一定要使用父元素来做
95 // 把内存中Documeng树写回XML文件中
96 TransformerFactory facotry = TransformerFactory.newInstance();
97 Transformer ts = facotry.newTransformer();
98 ts.transform(new DOMSource(document), new StreamResult("src/book.xml"));
99 }
100
101 // 6、删除指定元素节点:删除内部价
102 public static void test6(Document document) throws Exception {
103 // 找到内部价节点,用爸爸删除 删除的时候要有父节点删除子节点
104 Node n = document.getElementsByTagName("内部价").item(0);
105 n.getParentNode().removeChild(n);
106 // 把内存中Documeng树写回XML文件中
107 TransformerFactory facotry = TransformerFactory.newInstance();
108 Transformer ts = facotry.newTransformer();
109 ts.transform(new DOMSource(document), new StreamResult("src/book.xml"));
110 }
111
112 // 7、操作XML文件属性:打印第一本书的出版社
113 public static void test7(Document document) throws Exception {
114 // 得到第一本书
115 //document.getElementByTagName("书") 获取书说有元素
116 Node n = document.getElementsByTagName("书").item(0); //item(0)获取第一个元素
117 // 打印指定属性的取值
118 Element e = (Element) n; //打印指定的属性值
119 System.out.println(e.getAttribute("出版社")); //getAttribute()
120 }
121
122 // 8、添加一个出版社属性给第二本书
123 public static void test8(Document document) throws Exception {
124 // 得到第二本书
125 Node n = document.getElementsByTagName("书").item(1);
126 // 打印指定属性的取值
127 Element e = (Element) n;
128 e.setAttribute("出版社", "上海传智"); //设置该值
129 // 把内存中Documeng树写回XML文件中
130 //把内存中的Document树写回到XML文件中
131 TransformerFactory facotry = TransformerFactory.newInstance();
132 Transformer ts = facotry.newTransformer();
133 ts.transform(new DOMSource(document), new StreamResult("src/book.xml"));
134 }
135 }
测试
1 <?xml version="1.0" encoding="UTF-8" standalone="no"?> 2 <exam> 3 <student examid="222" idcard="111"> 4 <name>张三</name> 5 <location>沈阳</location> 6 <grade>89</grade> 7 </student> 8 <student examid="444" idcard="333"> 9 <name>李四</name> 10 <location>大连</location> 11 <grade>97</grade> 12 </student> 13 <student examid="666" idcard="555"> 14 <name>李宗瑞</name> 15 <location>台北</location> 16 <grade>100.0</grade> 17 </student> 18 </exam>
建立一个学生类
1 public class Student {
2 private String idcard;
3 private String examid;
4 private String name;
5 private String location;
6 private float grade;
7 public String getIdcard() {
8 return idcard;
9 }
10 public void setIdcard(String idcard) {
11 this.idcard = idcard;
12 }
13 public String getExamid() {
14 return examid;
15 }
16 public void setExamid(String examid) {
17 this.examid = examid;
18 }
19 public String getName() {
20 return name;
21 }
22 public void setName(String name) {
23 this.name = name;
24 }
25 public String getLocation() {
26 return location;
27 }
28 public void setLocation(String location) {
29 this.location = location;
30 }
31 public float getGrade() {
32 return grade;
33 }
34 public void setGrade(float grade) {
35 this.grade = grade;
36 }
37 @Override
38 public String toString() {
39 return "Student [examid=" + examid + ", grade=" + grade + ", idcard="
40 + idcard + ", location=" + location + ", name=" + name + "]";
41 }
42
43 }
创建一个接口:该接口有以以下的功能
- 添加学生信息到XML中
- 根据准考证号查询学生信息 如何学生不在,则返回null
- 根据学生姓名删除学生
package com.meijunjie.dao;
import com.meijunjie.domain.Student;
public interface IStudentDao {
/**
* 添加学生信息到XML中
* @param s
* @return
*/
boolean createStudent(Student s);
/**
* 根据准考证号查询学生信息
* @param examid
* @return 如果学生不存在,返回null
*/
Student findStudent(String examid);
/**
* 根据学生姓名删除学生
* @param name
* @return 如果人不存在也返回false
*/
boolean deleteStudent(String name);
}
创建工具类采用DOM方式解析XML文档 ,更新XML文档
1 package cn.meijunjie.util;
2
3 import javax.xml.parsers.DocumentBuilder;
4 import javax.xml.parsers.DocumentBuilderFactory;
5 import javax.xml.transform.Transformer;
6 import javax.xml.transform.TransformerFactory;
7 import javax.xml.transform.dom.DOMSource;
8 import javax.xml.transform.stream.StreamResult;
9
10 import org.w3c.dom.Document;
11 //操作XML的工具类
12 //工具类中的异常可以抛也可以处理
13 public class DocumentUtil {
14 public static Document getDocument() throws Exception{
//读取XML文档
15 DocumentBuilder builder = DocumentBuilderFactory.newInstance().newDocumentBuilder();
16 return builder.parse("src/exam.xml");
17 }
//向XML文档中写入
18 public static void write2xml(Document document)throws Exception{
19 Transformer ts = TransformerFactory.newInstance().newTransformer();
20 ts.transform(new DOMSource(document), new StreamResult("src/exam.xml"));
21 }
22 }
实现该接口:
package cn.meijunjie.dao;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import cn.itcast.domain.Student;
import cn.itcast.util.DocumentUtil;
//异常:抛的话,上层能解决才行
//上一层如果处理不了,自己必须处理。
public class StudentDao implements IStudentDao {
/**
* 添加学生信息到XML中
* @param s
* @return
*/
public boolean createStudent(Student s){
System.out.println("JAXP");
//目标:在根元素exam中添加student子元素
boolean result = false;
try {
Document document = DocumentUtil.getDocument(); //读取文档内容
//创建name、location、grade元素并设置其主体内容
Element nameE = document.createElement("name");
nameE.setTextContent(s.getName());
Element locationE = document.createElement("location");
locationE.setTextContent(s.getLocation());
Element gradeE = document.createElement("grade");
gradeE.setTextContent(s.getGrade()+"");
//创建student元素,并设置其属性
Element studentE = document.createElement("student");
studentE.setAttribute("idcard", s.getIdcard());
studentE.setAttribute("examid", s.getExamid());//CTRL+ALT+ARROW
studentE.appendChild(nameE);
studentE.appendChild(locationE);
studentE.appendChild(gradeE);
//得到exam元素,把student挂接上去
Node node = document.getElementsByTagName("exam").item(0);
node.appendChild(studentE);
//写回XML文件中
DocumentUtil.write2xml(document);
result = true;
} catch (Exception e) {
throw new RuntimeException(e);//异常转义。异常链
}
return result;
}
/**
* 根据准考证号查询学生信息
* @param examid
* @return 如果学生不存在,返回null
*/
public Student findStudent(String examid){
Student s = null;
try{
//得到Document对象
Document document = DocumentUtil.getDocument();
//得到所有的student元素
NodeList nl = document.getElementsByTagName("student");
//遍历student元素,判断他的examid属性的取值是否与参数匹配
for(int i=0;i<nl.getLength();i++){
Node node = nl.item(i);
// if(node.getNodeType()==Node.ELEMENT_NODE){
// Element e = (Element)node;
if(node instanceof Element){
Element e = (Element)node;
if(e.getAttribute("examid").equals(examid)){
//如果匹配:说明找到了学生;创建学生对象
s = new Student();
//设置学生对象的各个属性取值
s.setExamid(examid);
s.setIdcard(e.getAttribute("idcard"));
s.setName(e.getElementsByTagName("name").item(0).getTextContent());
s.setLocation(e.getElementsByTagName("location").item(0).getTextContent());
s.setGrade(Float.parseFloat(e.getElementsByTagName("grade").item(0).getTextContent()));
}
}
}
}catch(Exception e){
throw new RuntimeException(e);
}
return s;
}
/**
* 根据学生姓名删除学生
* @param name
* @return 如果人不存在也返回false
*/
public boolean deleteStudent(String name){
boolean result = false;
try{
//得到Document对象
Document document = DocumentUtil.getDocument();
//得到所有的name元素
NodeList nl = document.getElementsByTagName("name");
//遍历name元素,判断其主体内容是否与参数一致
for(int i=0;i<nl.getLength();i++){
//如果一致:找到他的爸爸的爸爸,删除它的爸爸
Node n = nl.item(i);
if(n.getTextContent().equals(name)){
n.getParentNode().getParentNode().removeChild(n.getParentNode());
//写回XML文档
DocumentUtil.write2xml(document);
result = true;
break;
}
}
}catch(Exception e){
throw new RuntimeException(e);
}
return result;
}
}