NLP_Stanford课堂语言模型
Posted a-present
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP_Stanford课堂语言模型相关的知识,希望对你有一定的参考价值。
一、语言模型
旨在:给一个句子或一组词计算一个联合概率![]()
作用:
- 机器翻译:用以区分翻译结果的好坏
- 拼写校正:某一个拼错的单词是这个单词的概率更大,所以校正
- 语音识别:语音识别出来是这个句子的概率更大
- 总结或问答系统
相关任务:在原句子的基础上,计算一个新词的条件概率![]() ,该概率与P(w1w2w3w4w5)息息相关。
,该概率与P(w1w2w3w4w5)息息相关。
任何一个模型计算以上两个概率的,我们都称之为语言模型LM。
二、如何计算概率
方法:依赖概率的链式规则![]()
从而有:
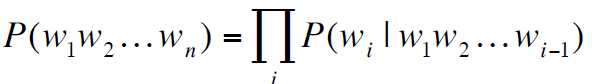
问题:如何预估这些概率
方法一:计数和细分

但是不可能做到!
原因:句子数量过于庞大;永远不可能有足够的数据来预估这些(语料库永远不可能是完备的)
方法二:马尔可夫假设
![]()
或者:
![]()
即:
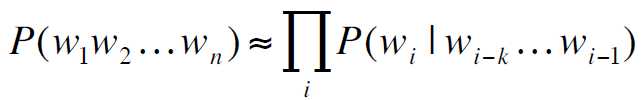
所以:
![]()
三、马尔可夫模型
1. Unigram model
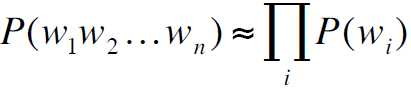
其假设词是相互独立的
2. Bigram model
![]()
3. N-gram models
但是并不有效,因为语言本身存在长距离依存关系
比如"The computer which ......crashed" 单词crash本身其实是依赖于主语computer的,但是中间隔了一个很长的从句,在马尔可夫模型中就很难找到这样的依存关系
但是在实际应用中,发现N-gram可以一定程度上解决这个问题
以上是关于NLP_Stanford课堂语言模型的主要内容,如果未能解决你的问题,请参考以下文章
网易云课堂_C语言程序设计进阶_第六周:程序结构:内存模型(全局变量和局部变量)头文件宏定义函数指针和回调函数,ACL图形库的消息机制