《TensorFlow实例》
Posted welcome-xwell
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《TensorFlow实例》相关的知识,希望对你有一定的参考价值。
Ubuntu python3 TensorFlow实例:使用RNN算法实现对MINST-data数字集识别,最终识别准确率达96.875%
PS:小白一个,初级阶段,从调试到实现,step by step.
由于没能及时保留原著作者文章来源,对此深表歉意!!!
附录作者GitHub链接,以示尊重。
aymericdamien/TensorFlow-Examples: TensorFlow Tutorial and Examples for Beginners with Latest APIs https://github.com/aymericdamien/TensorFlow-Examples
python文件列表:
2:RNN.py
3:tensorboard.py
数据集:MNIST_data
实现过程:
RNN.py
""" This code is a modified version of the code from this link: https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/recurrent_network.py His code is a very good one for RNN beginners. Feel free to check it out. """ import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # set random seed for comparing the two result calculations tf.set_random_seed(1) # this is data mnist = input_data.read_data_sets(‘MNIST_data‘, one_hot=True) # hyperparameters lr = 0.001 #learning rate training_iters = 100000 batch_size = 128 n_inputs = 28 # MNIST data input (img shape: 28*28) n_steps = 28 # time steps n_hidden_units = 128 # neurons in hidden layer n_classes = 10 # MNIST classes (0-9 digits) # tf Graph input x = tf.placeholder(tf.float32, [None, n_steps, n_inputs]) y = tf.placeholder(tf.float32, [None, n_classes]) # Define weights weights = { # (28, 128) ‘in‘: tf.Variable(tf.random_normal([n_inputs, n_hidden_units])), # (128, 10) ‘out‘: tf.Variable(tf.random_normal([n_hidden_units, n_classes])) } biases = { # (128, ) ‘in‘: tf.Variable(tf.constant(0.1, shape=[n_hidden_units, ])), # (10, ) ‘out‘: tf.Variable(tf.constant(0.1, shape=[n_classes, ])) } def RNN(X, weights, biases): # hidden layer for input to cell ######################################## # transpose the inputs shape from # X ==> (128 batch * 28 steps, 28 inputs) X = tf.reshape(X, [-1, n_inputs]) # into hidden # X_in = (128 batch * 28 steps, 128 hidden) X_in = tf.matmul(X, weights[‘in‘]) + biases[‘in‘] # X_in ==> (128 batch, 28 steps, 128 hidden) X_in = tf.reshape(X_in, [-1, n_steps, n_hidden_units]) # cell ########################################## # basic LSTM Cell. if int((tf.__version__).split(‘.‘)[1]) < 12 and int((tf.__version__).split(‘.‘)[0]) < 1: cell = tf.nn.rnn_cell.BasicLSTMCell(n_hidden_units, forget_bias=1.0, state_is_tuple=True) else: cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_units) # lstm cell is divided into two parts (c_state, h_state) init_state = cell.zero_state(batch_size, dtype=tf.float32) # You have 2 options for following step. # 1: tf.nn.rnn(cell, inputs); # 2: tf.nn.dynamic_rnn(cell, inputs). # If use option 1, you have to modified the shape of X_in, go and check out this: # https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/recurrent_network.py # In here, we go for option 2. # dynamic_rnn receive Tensor (batch, steps, inputs) or (steps, batch, inputs) as X_in. # Make sure the time_major is changed accordingly. outputs, final_state = tf.nn.dynamic_rnn(cell, X_in, initial_state=init_state, time_major=False) # hidden layer for output as the final results ############################################# # results = tf.matmul(final_state[1], weights[‘out‘]) + biases[‘out‘] # # or # unpack to list [(batch, outputs)..] * steps if int((tf.__version__).split(‘.‘)[1]) < 12 and int((tf.__version__).split(‘.‘)[0]) < 1: outputs = tf.unpack(tf.transpose(outputs, [1, 0, 2])) # states is the last outputs else: outputs = tf.unstack(tf.transpose(outputs, [1,0,2])) results = tf.matmul(outputs[-1], weights[‘out‘]) + biases[‘out‘] # shape = (128, 10) return results pred = RNN(x, weights, biases) cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y)) train_op = tf.train.AdamOptimizer(lr).minimize(cost) correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) with tf.Session() as sess: # tf.initialize_all_variables() no long valid from # 2017-03-02 if using tensorflow >= 0.12 if int((tf.__version__).split(‘.‘)[1]) < 12 and int((tf.__version__).split(‘.‘)[0]) < 1: init = tf.initialize_all_variables() else: init = tf.global_variables_initializer() sess.run(init) step = 0 while step * batch_size < training_iters: batch_xs, batch_ys = mnist.train.next_batch(batch_size) batch_xs = batch_xs.reshape([batch_size, n_steps, n_inputs]) sess.run([train_op], feed_dict={ x: batch_xs, y: batch_ys, }) if step % 20 == 0: print(sess.run(accuracy, feed_dict={ x: batch_xs, y: batch_ys, })) step += 1
tensorboard.py
# View more python learning tutorial on my Youtube and Youku channel!!! """ Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly. """ from __future__ import print_function import tensorflow as tf import numpy as np def add_layer(inputs, in_size, out_size, n_layer, activation_function=None): # add one more layer and return the output of this layer layer_name = ‘layer%s‘ % n_layer with tf.name_scope(layer_name): with tf.name_scope(‘weights‘): Weights = tf.Variable(tf.random_normal([in_size, out_size]), name=‘W‘) tf.summary.histogram(layer_name + ‘/weights‘, Weights) with tf.name_scope(‘biases‘): biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name=‘b‘) tf.summary.histogram(layer_name + ‘/biases‘, biases) with tf.name_scope(‘Wx_plus_b‘): Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases) if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b, ) tf.summary.histogram(layer_name + ‘/outputs‘, outputs) return outputs # Make up some real data x_data = np.linspace(-1, 1, 300)[:, np.newaxis] noise = np.random.normal(0, 0.05, x_data.shape) y_data = np.square(x_data) - 0.5 + noise # define placeholder for inputs to network with tf.name_scope(‘inputs‘): xs = tf.placeholder(tf.float32, [None, 1], name=‘x_input‘) ys = tf.placeholder(tf.float32, [None, 1], name=‘y_input‘) # add hidden layer l1 = add_layer(xs, 1, 10, n_layer=1, activation_function=tf.nn.relu) # add output layer prediction = add_layer(l1, 10, 1, n_layer=2, activation_function=None) # the error between prediciton and real data with tf.name_scope(‘loss‘): loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1])) tf.summary.scalar(‘loss‘, loss) with tf.name_scope(‘train‘): train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) sess = tf.Session() merged = tf.summary.merge_all() writer = tf.summary.FileWriter("logs/", sess.graph) init = tf.global_variables_initializer() sess.run(init) for i in range(1000): sess.run(train_step, feed_dict={xs: x_data, ys: y_data}) if i % 50 == 0: result = sess.run(merged, feed_dict={xs: x_data, ys: y_data}) writer.add_summary(result, i) # direct to the local dir and run this in terminal: # $ tensorboard --logdir logs
相关介绍分析见文章来源:
tensorflow 学习笔记12 循环神经网络RNN LSTM结构实现MNIST手写识别 - CSDN博客 https://blog.csdn.net/Revendell/article/details/77451561
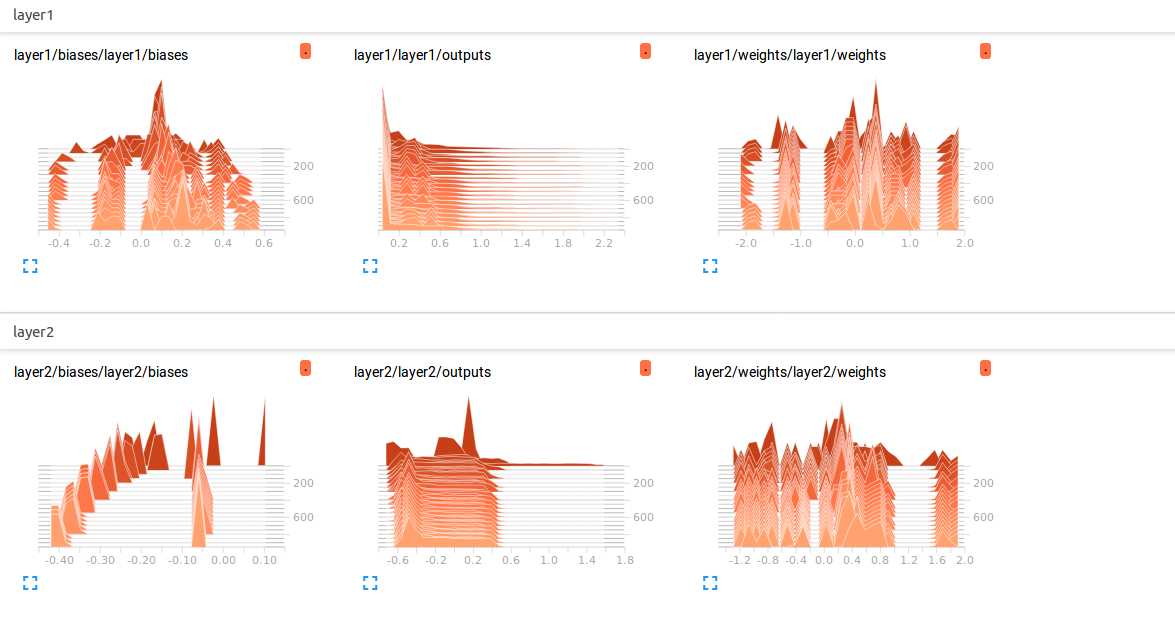
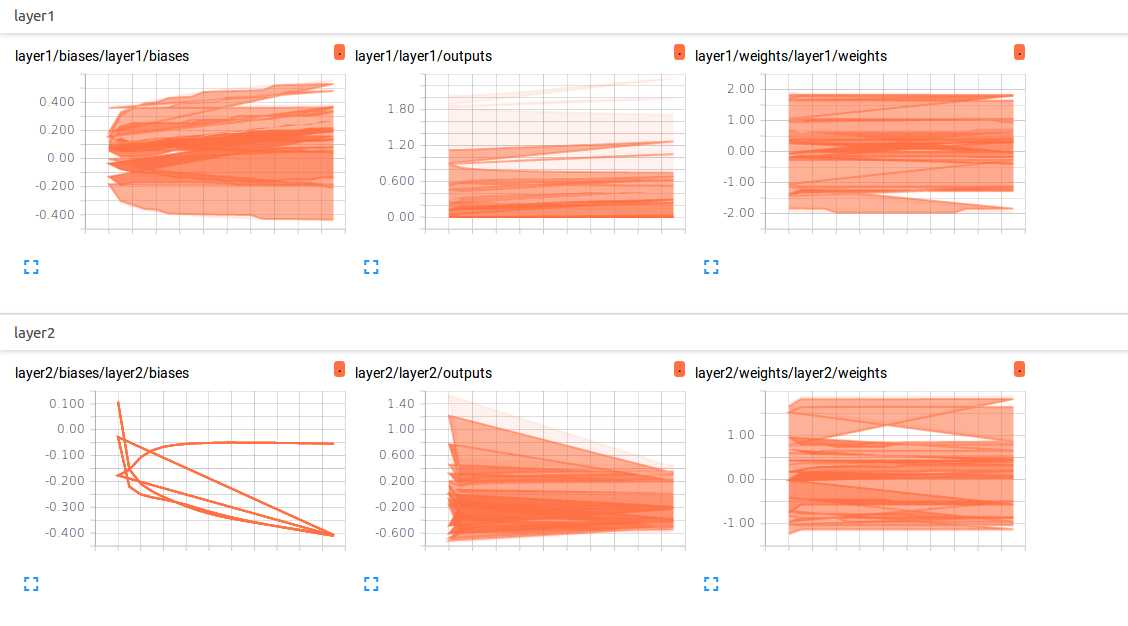
最终效果:
$ tensorboard --logdir logs
在tensorboard上查看RNN卷积递归过程
以上是关于《TensorFlow实例》的主要内容,如果未能解决你的问题,请参考以下文章