4.2tensorflow多层感知器MLP识别手写数字最易懂实例代码
Posted 一字千金
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4.2tensorflow多层感知器MLP识别手写数字最易懂实例代码相关的知识,希望对你有一定的参考价值。
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
1.1 多层感知器MLP(multilayer perception)
1.1.1 多层感知器的结构
除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构。,假设输入层用向量X表示,则隐藏层的输出就是 f (W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数。
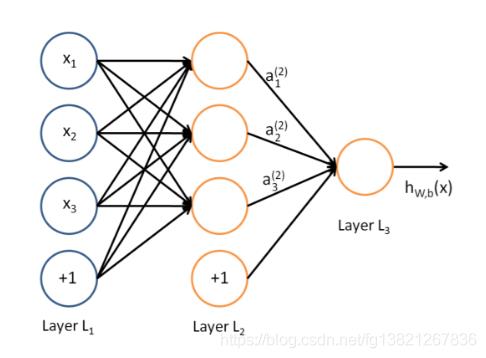
1.1.2 激活函数
能够给神经元引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以利用到更多的非线性模型中。
(1) 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参数。
(2)激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
(3)激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
sigmod激活函数取值范围是(0,1),
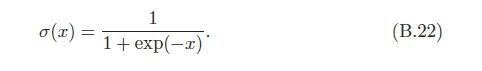
导数为
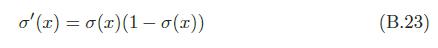
tanh激活函数取值范围是(-1,1)
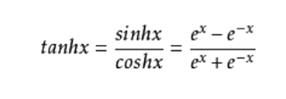
导数为
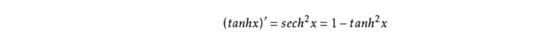
MLP所有的参数就是各个层之间的连接权重以及偏置,最简单的就是梯度下降法了(SGD):首先随机初始化所有参数,然后迭代地训练,不断地计算梯度和更新参数,直到满足某个条件为止(比如误差足够小、迭代次数足够多时)。这个过程涉及到代价函数、规则化(Regularization)、学习速率(learning rate)、梯度计算等,最后得出参数,就是模型训练的过程。
1.1.3 tensorflow建立多层感知器的步骤
(1)定义手写数字数据获取类,用于下载数据和随机获取小批量训练数据。
(2)定义多层感知器,继承继承keras.Model,init函数定义层,call函数中组织数据处理流程。
(3)定义训练参数和模型对象,数据集对象。
(4)通过梯度下降法对模型参数进行训练,优化模型。
(5)用测试数据集评估模型的准确性
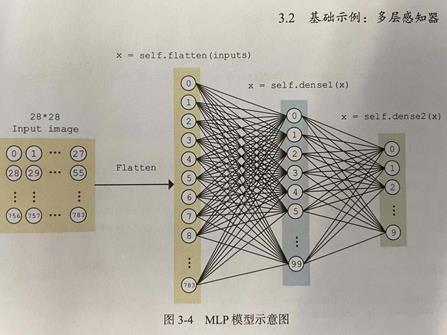
1.1.4 手写数字识别模型实例
下载60000个手写数字图片进行图像识别,识别出数字,用多层感知器去识别,用梯度下降法去训练模型参数。代码实例。
import tensorflow as tf import numpy as np import matplotlib.pyplot as plot #(1)定义手写数字数据获取类,用于下载数据和随机获取小批量训练数据 class MNISTLoader(): def __init__(self): minist = tf.keras.datasets.mnist #训练数据x_train, 正确值y_train,测试数据x_test,测试数据正确值self.y_test (self.x_train, self.y_train), (self.x_test, self.y_test) = minist.load_data() #[60000,28,28,1],60000个28*28像素的图片数据,每个像素点时0-255的整数,除以255.0是将每个像素值归一化为0-1间 #的浮点数,并通过np.expand_dims增加一维,作为颜色通道.默认值为1。 self.x_train = np.expand_dims(self.x_train.astype(np.float) / 255.0, axis=-1) print(self.x_train.shape) #[10000,28,28]->[10000,28,28,1] self.x_test = np.expand_dims(self.x_test.astype(np.float) / 255.0, axis=-1) #训练用的标签值 self.y_train = self.y_train.astype(np.int) #测试用的标签值 self.y_test = self.y_test.astype(np.int) self.num_train_data = self.x_train.shape[0] self.num_test_data = self.x_test.shape[0] #随机从数据集中获取大小为batch_size手写图片数据 def get_batch(self, batch_size): #shape[0]获取数据总数量,在0-总数量之间随机获取数据的索引值,相当于抽样。 index = np.random.randint(0, self.x_train.shape[0], batch_size) #通过索引值去数据集中获取训练数据集。 return self.x_train[index, :], self.y_train[index] #(2)定义多层感知器,继承继承keras.Model,init函数定义层,call函数中组织数据处理流程 class MLP(tf.keras.Model): def __init__(self): super(MLP, self).__init__() #扁平化,将28*28的二维数组,变成1维数组,0-783. self.flatten = tf.keras.layers.Flatten() #全连接层,将784个像素点转化为100个 self.dence1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu) #全连接层,将100个单元转化为10个点 self.dence2 = tf.keras.layers.Dense(units=10) def call(self, inputs, training=None, mask=None): #编写数据流的处理过程, x = self.flatten(inputs)#28*28的二维矩阵扁平化为784个1维数组 x = self.dence1(x)#784个映射到100个 x = self.dence2(x)#100个映射到10个,分别表示对应0,1..9数字的概率 output = tf.nn.softmax(x)#输出0,1..9概率最大的值。 return output #(3)定义训练参数和模型对象,数据集对象 num_epochs = 5 batch_size = 500#一批数据的数量 learning_rate = 0.001#学习率 model = MLP()#创建模型 data_loader = MNISTLoader()#创建数据源对象 optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)#创建优化器,用于参数学习优化 #开始训练参数 num_batches=int(data_loader.num_train_data//batch_size*num_epochs)#计算训练数据的总组数 arryindex=np.arange(num_batches) arryloss=np.zeros(num_batches) #(4)通过梯度下降法对模型参数进行训练,优化模型 for batch_index in range(num_batches): X,ylabel=data_loader.get_batch(batch_size)#随机获取训练数据 with tf.GradientTape() as tape: ypred=model(X)#模型计算预测值 #计算损失函数 loss=tf.keras.losses.sparse_categorical_crossentropy(y_true=ylabel,y_pred=ypred) #计算损失函数的均方根值,表示误差大小 loss=tf.reduce_mean(loss) print("第%d次训练后:误差%f" % (batch_index,loss.numpy())) #保存误差值,用于画图 arryloss[batch_index]=loss #根据误差计算梯度值 grads=tape.gradient(loss,model.variables) #将梯度值调整模型参数 optimizer.apply_gradients(grads_and_vars=zip(grads,model.variables)) #画出训练误差随训练次数的图片图 plot.plot(arryindex,arryloss,c=\'r\') plot.show() #(5)评估模型的准确性 #建立评估器对象 sparse_categorical_accuracy=tf.keras.metrics.SparseCategoricalAccuracy() #用测试数据集计算预测值 ytestpred=model.predict(data_loader.x_test) #向评估器输入预测值和真实值,计算准确率 sparse_categorical_accuracy.update_state(y_true=data_loader.y_test,y_pred=ytestpred) print("test accuracy is %f" % sparse_categorical_accuracy.result())
训练误差收敛情况
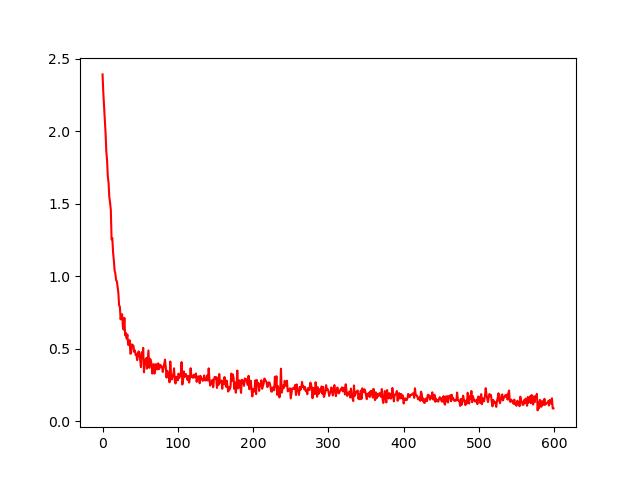
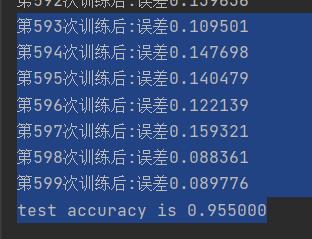
输出评估分析结果,训练时误差是0.089,用测试数据进行测试准确性是0.955。
1.1.5 mlp使用知识点
(1) expand_dims(a, axis) 给张量a,在位置axis处增加一个维度。
# \'t\' is a tensor of shape [2]
shape(expand_dims(t, 0)) ==> [1, 2]#在位置0处加
shape(expand_dims(t, 1)) ==> [2, 1]#在位置1处加
shape(expand_dims(t, -1)) ==> [2, 1]#默认在后面加
# \'t2\' is a tensor of shape [2, 3, 5]
shape(expand_dims(t2, 0)) ==> [1, 2, 3, 5]
shape(expand_dims(t2, 2)) ==> [2, 3, 1, 5]
shape(expand_dims(t2, 3)) ==> [2, 3, 5, 1]
(2) tf.keras.layers.Flatten()将多维的张量转化为1维数组
将输入层的数据压成一维的数据,一般用再卷积层和全连接层之间(因为全连接层只能接收一维数据,而卷积层可以处理二维数据,就是全连接层处理的是向量,而卷积层处理的是矩阵。
(3) x_train.shape[0],获取张量的维度,0表示第一个维度,也可以通过给shape赋值,改变张量的维度。
建立一个2*3*4的张量
>>> y = np.zeros((2, 3, 4))
>>> y.shape
(2, 3, 4)获取维度
>>> y.shape = (3, 8)#赋值维度
>>> y#输出y的值,变成3行8列的二维矩阵
array([[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.]])
(4) tf.keras.layers.Dense全连接层
def __init__(self,
units,
activation=None,
use_bias=True,
kernel_initializer=\'glorot_uniform\',
bias_initializer=\'zeros\',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs)
units: 正整数,输出空间维度。
activation: 激活函数 (详见 activations)。 若不指定,则不使用激活函数 (即,线性激活: a(x) = x)。
use_bias: 布尔值,该层是否使用偏置向量。
kernel_initializer: kernel 权值矩阵的初始化器 (详见 initializers)。
bias_initializer: 偏置向量的初始化器 (详见 initializers)。
kernel_regularizer: 运用到 kernel 权值矩阵的正则化函数 (详见 regularizer)。
bias_regularizer: 运用到偏置向量的的正则化函数 (详见 regularizer)。
activity_regularizer: 运用到层的输出的正则化函数 (它的 "activation")。 (详见 regularizer)。
kernel_constraint: 运用到 kernel 权值矩阵的约束函数 (详见 constraints)。
bias_constraint: 运用到偏置向量的约束函数 (详见 constraints)。
(5) tf.keras.optimizers.Adam参数优化器
keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, amsgrad=False)
Adam 优化器。
learning_rate: float >= 0. 学习率。
beta_1: float, 0 < beta < 1. 通常接近于 1。
beta_2: float, 0 < beta < 1. 通常接近于 1。
amsgrad: boolean. 是否应用此算法的 AMSGrad 变种,来自论文 "On the Convergence of Adam and Beyond"。
(6) tf.keras.losses.sparse_categorical_crossentropy交叉熵函数
将模型的预测值和标签值传入计算损失函数的值,当预测概率分布和真实的概率分布越接近,交叉熵值越小,误差越小。
(7) tf.keras.metrics.SparseCategoricalAccuracy()模型评估器
将测试数据输入模型得出预测值,通过调用update_state()方法向评估器输入y_pred和y_true两个参数,可以传入多次,最后调用result()函数输出总的预测的准确率。
以上是关于4.2tensorflow多层感知器MLP识别手写数字最易懂实例代码的主要内容,如果未能解决你的问题,请参考以下文章