CentOS7.4到Elasticsearch一路坑
Posted christiankula
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CentOS7.4到Elasticsearch一路坑相关的知识,希望对你有一定的参考价值。
终于开始hadoop
上来就手欠了一下,cp 了 *
现在我有一个问题:cp可不可以有进度反馈。。。
好了反正手欠也手欠了,还是在copy,好在我虚拟机配置的硬件参数够硬,沏杯茶的功夫也就完了,tar 解压hadoop
编辑hadoop-env.sh,把jdk路径写进去(我现在是偷懒,放在了根目录,另外还是要习惯一下,linux终端的复制是ctrl+shif+c,但是进入了gedit,还是ctrl+c)
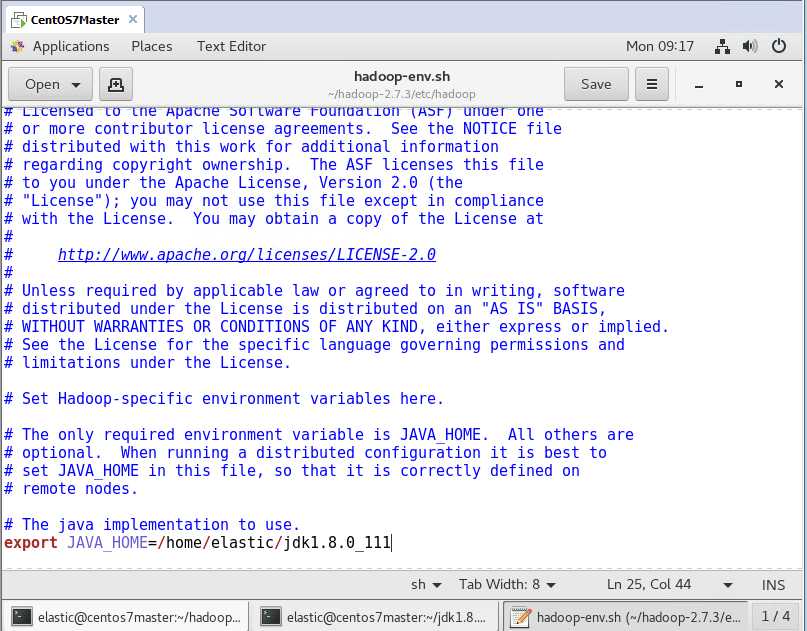
编辑yarn-env.sh
编辑core-site.xml。。。行了我受够了vi和gedit了,上notepad++!
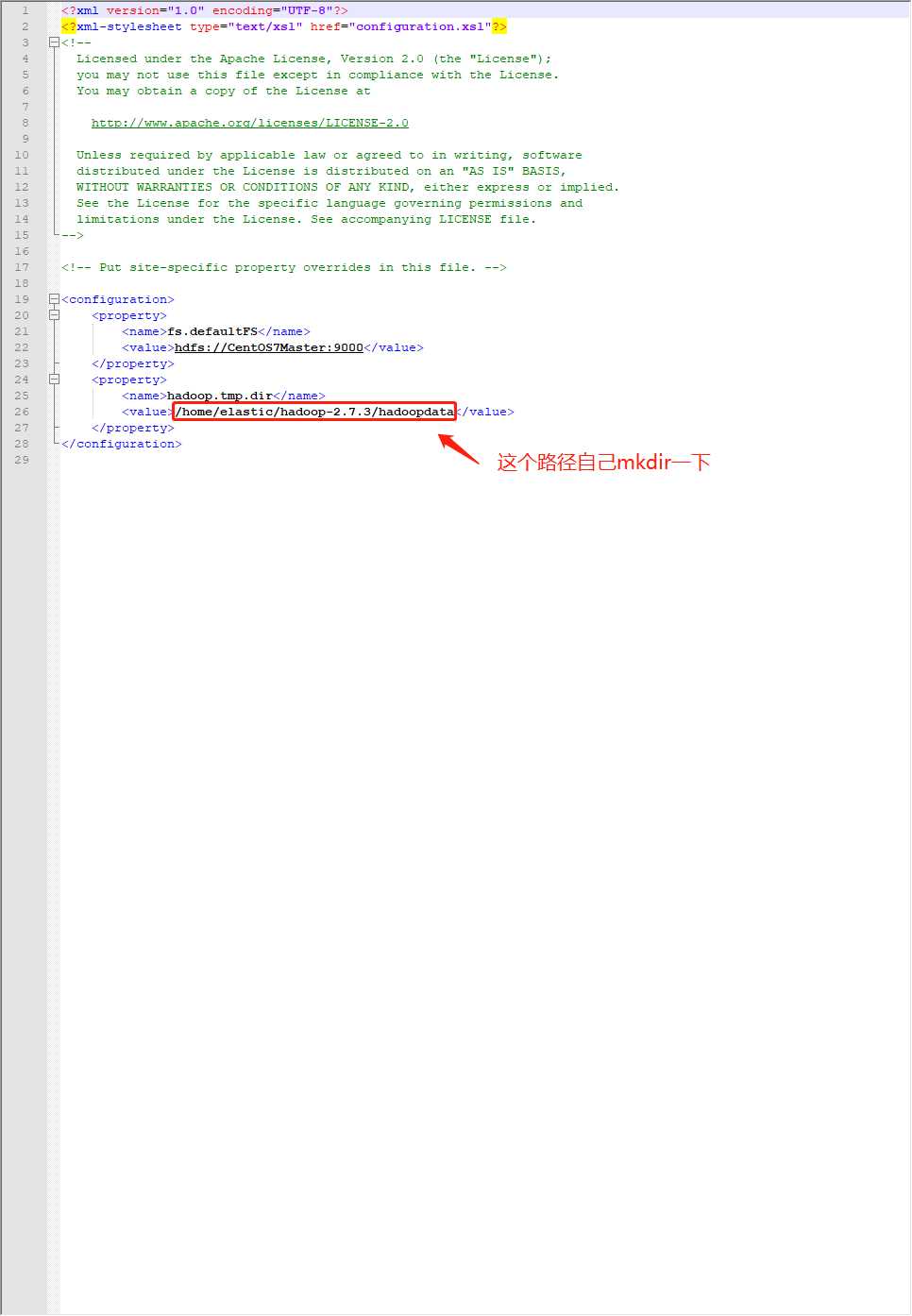
notepad++里ctrl+shift+alt+B,可以format一下xml,看起来就舒服多了,我不是处女座,没那么强烈的强迫症,但是不对齐就是看着没那么舒坦
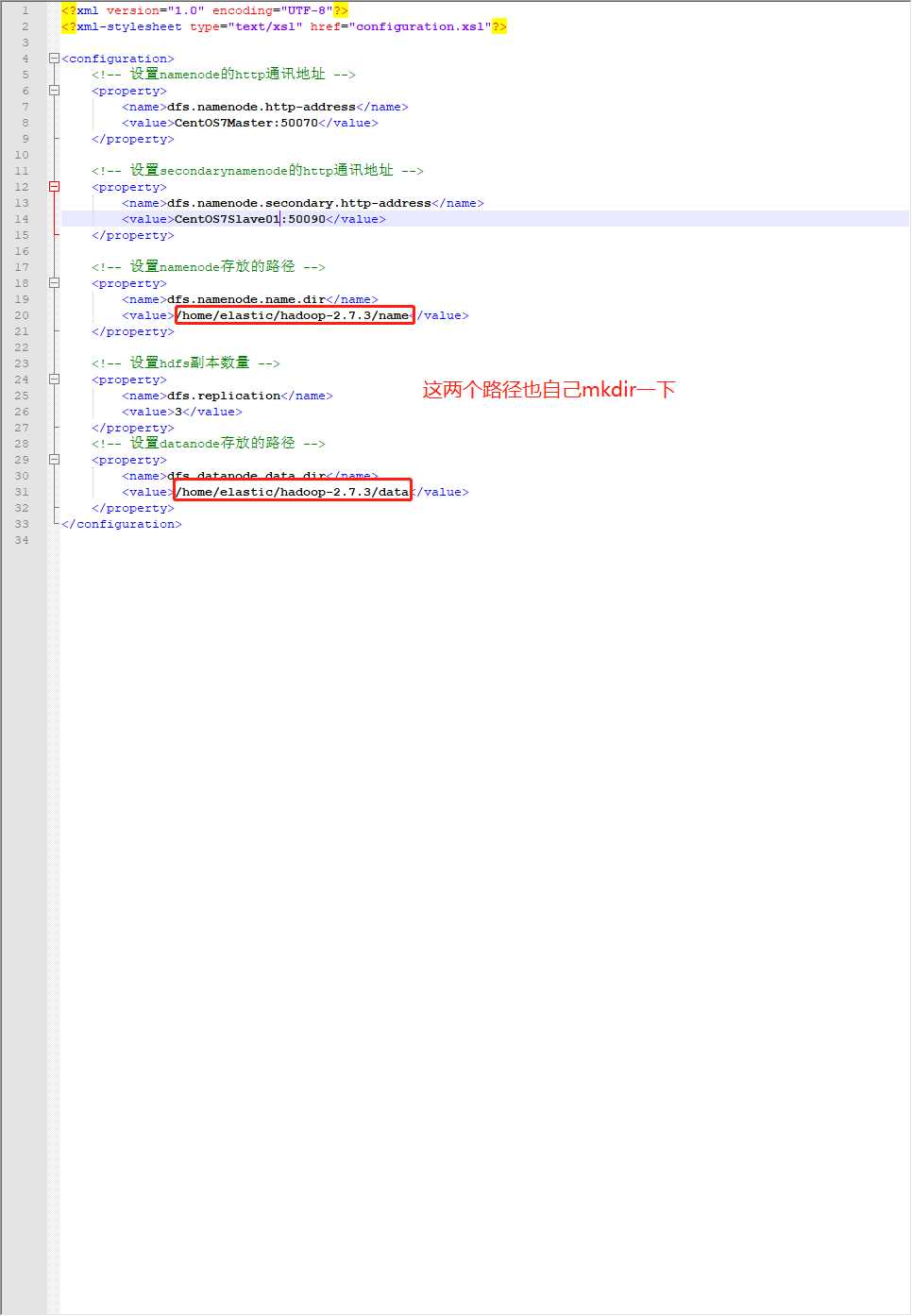
好了舒坦了,继续hdfs-site.xml
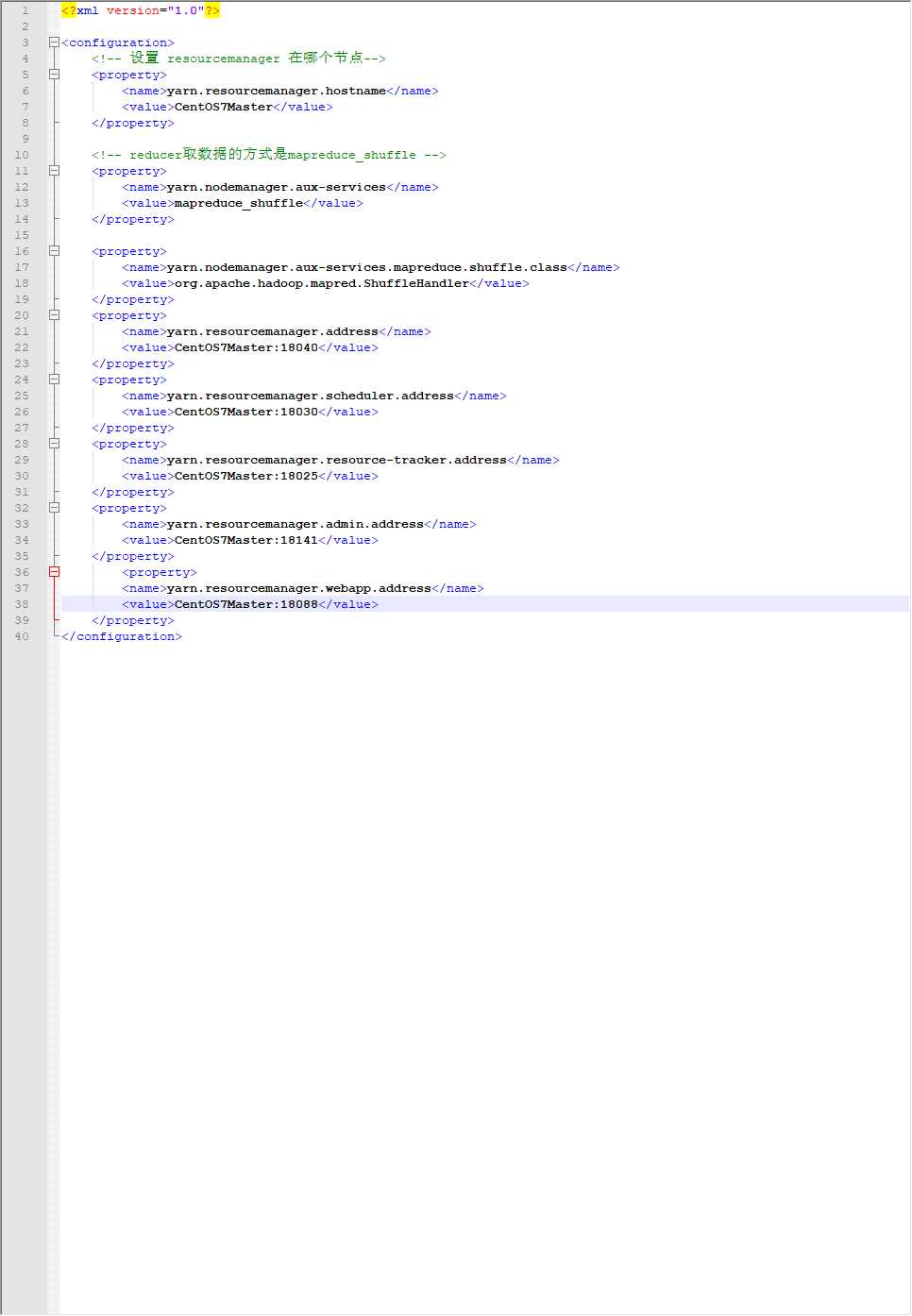
yarn-ste.xml继续
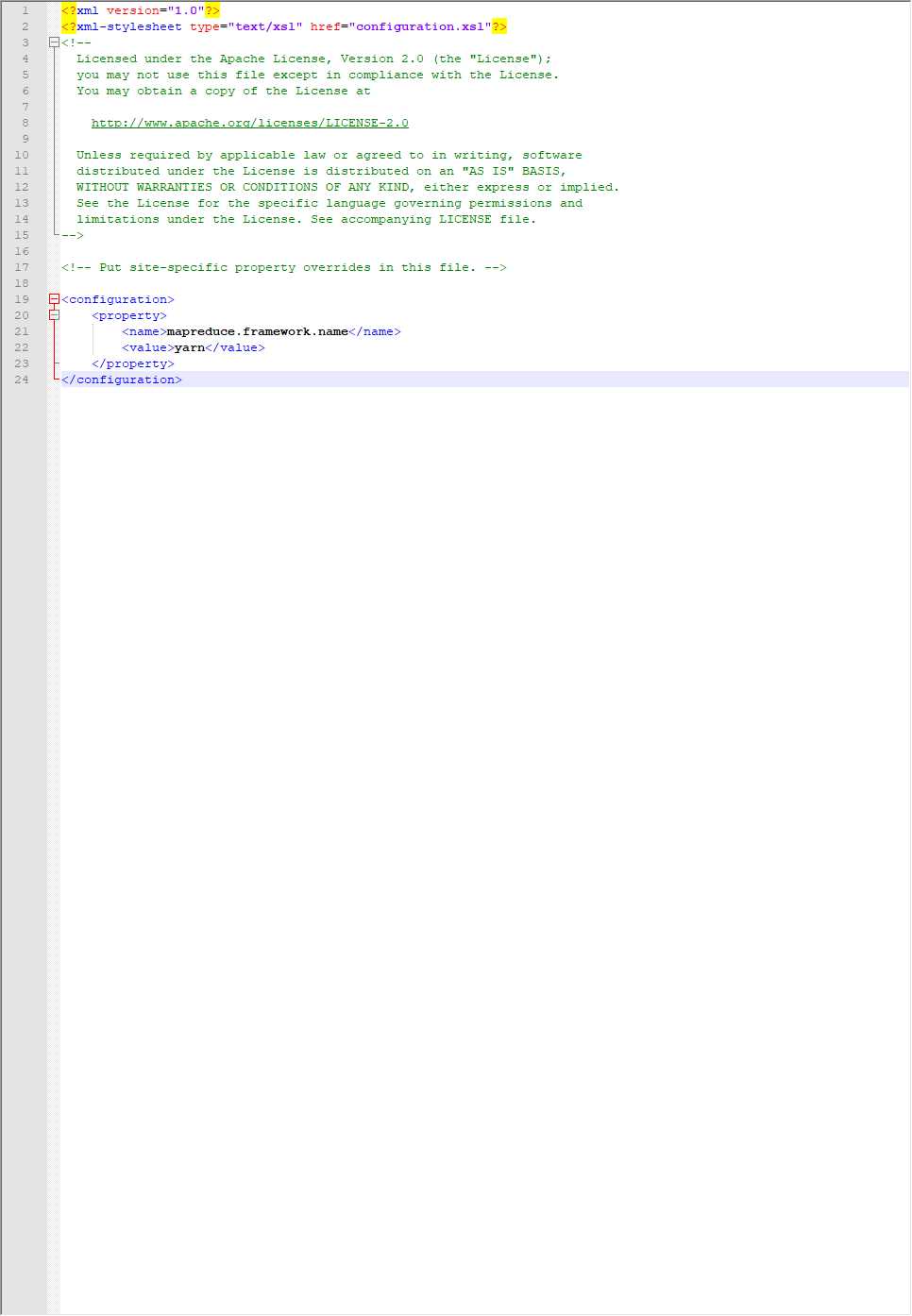
计算框架mapred-site.xml只是一个模板,要copy一份
cp mapred-site.xml.template mapred-site.xml
最后一个,slaves,不截图了,就两个主机名
CentOS7Slave01
CentOS7Slave02
然后省事的部分来了,开始向slaves同步。。。
scp -r hadoop-2.7.3 CentOS7Slave01:~/
scp -r hadoop-2.7.3 CentOS7Slave02:~/
最后编辑一下环境变量(master和slaves都要编辑)
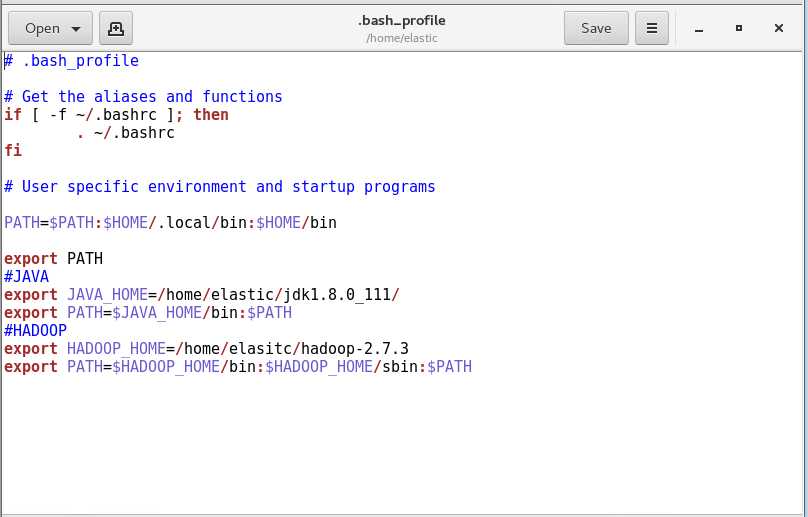
编辑完记得source一下
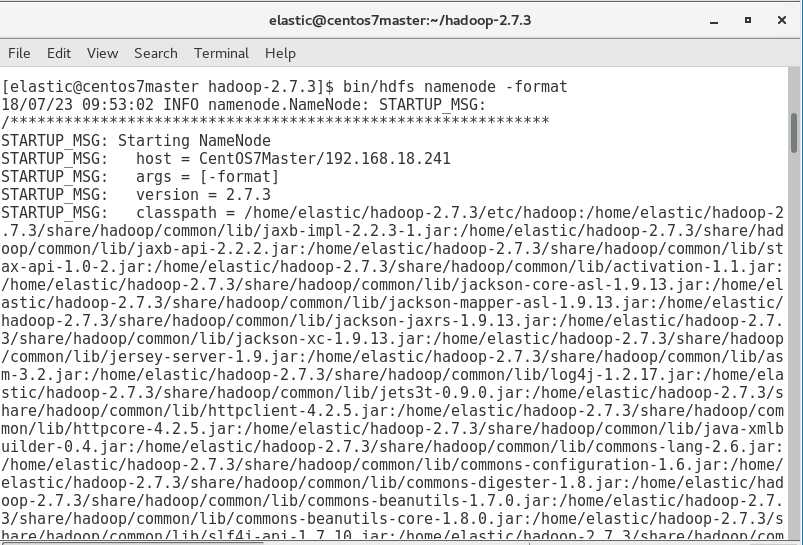
第一次启动,format一下namenode
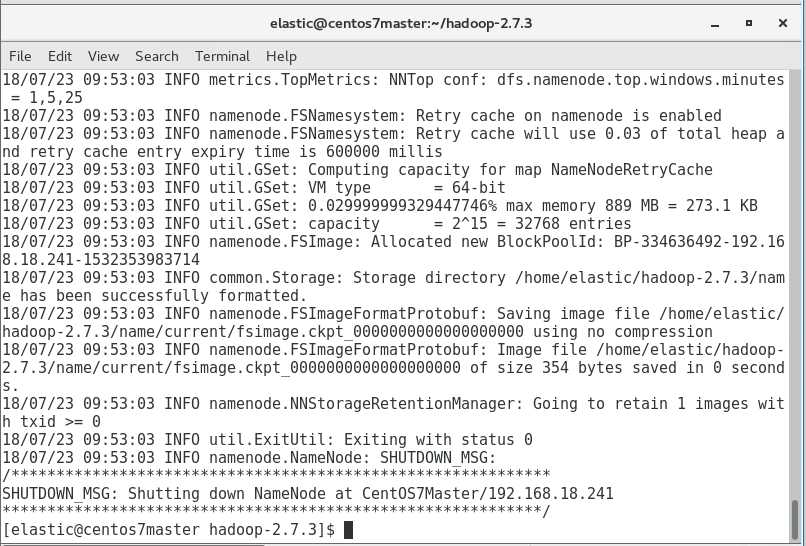
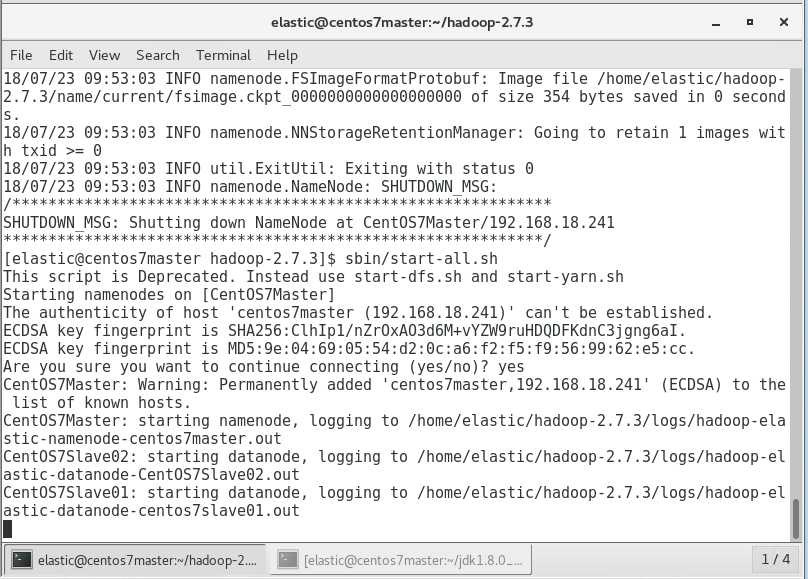
sbin/start-all.sh
jps看一下
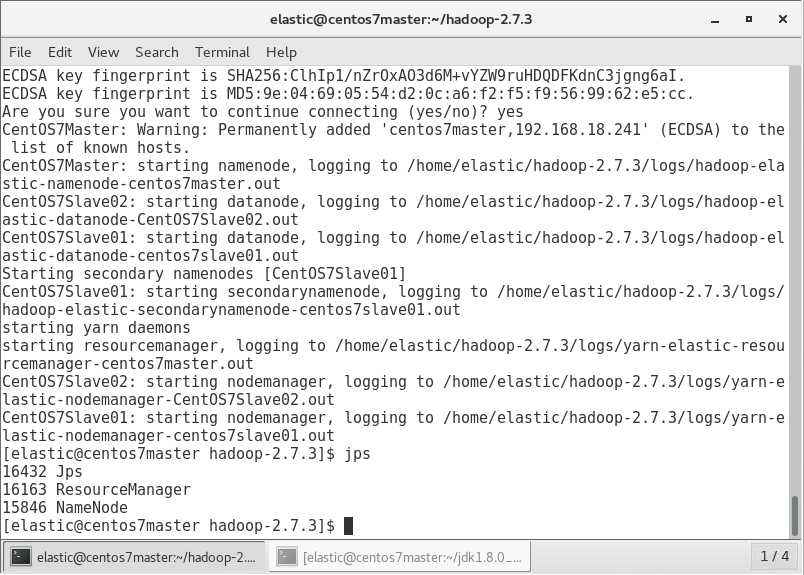
master启动了NameNode和ResourceManager
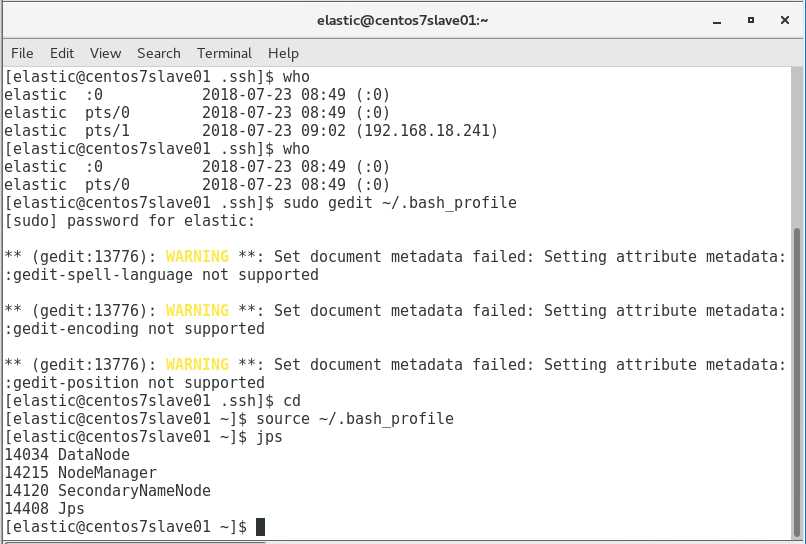
slave01启动了DataNode,NodeManger和SecondaryNameNode
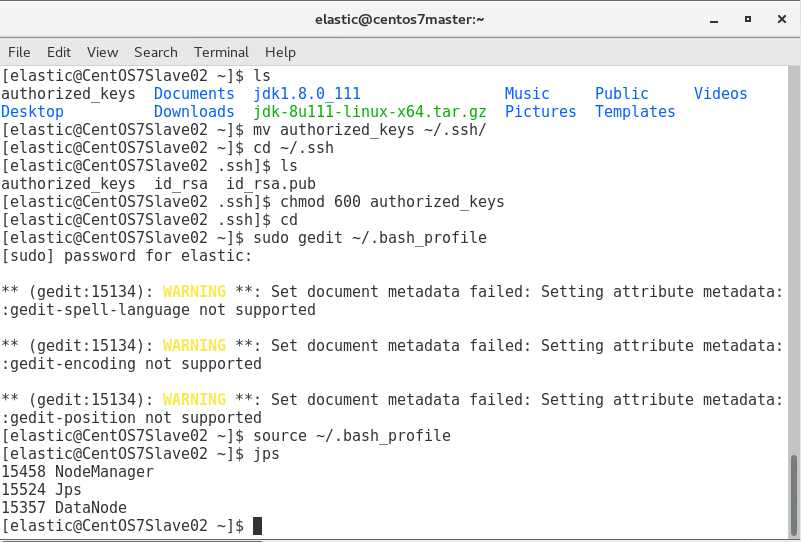
slave02启动了DataNode,NodeManger
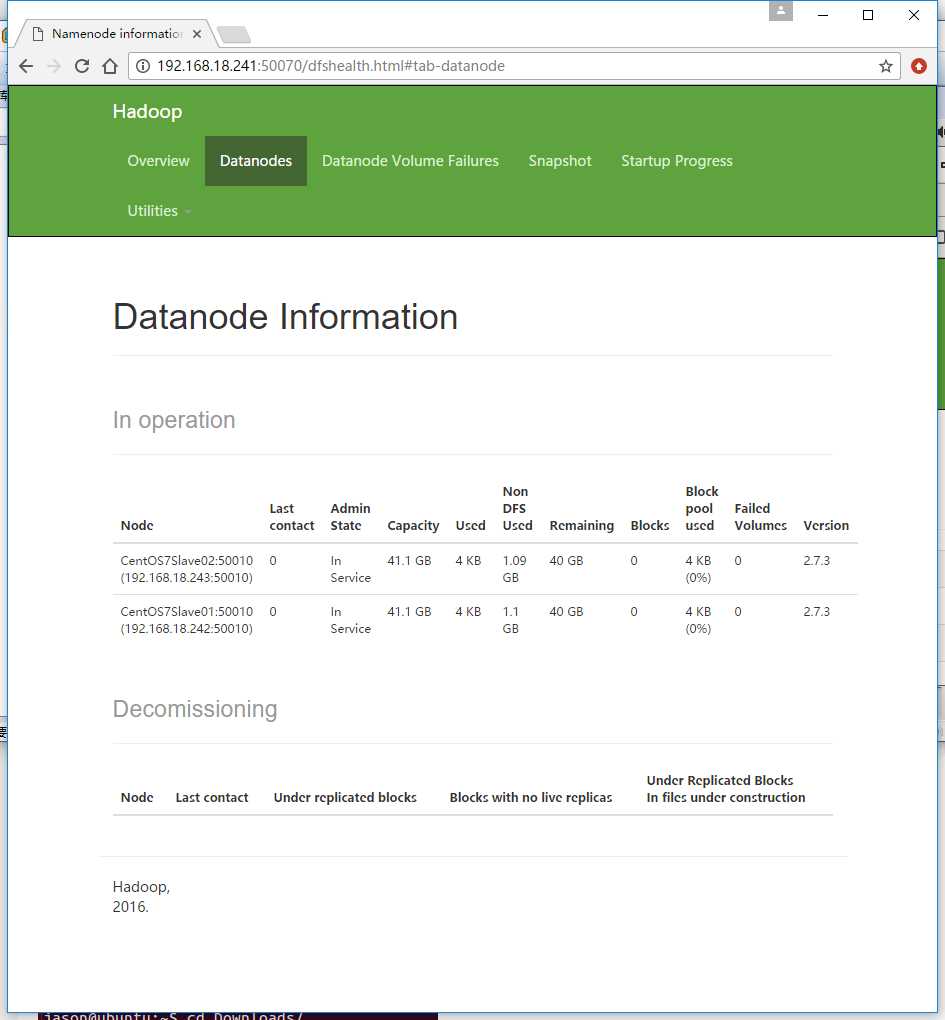
访问一下50070(本地还没配置hosts,用IP访问)
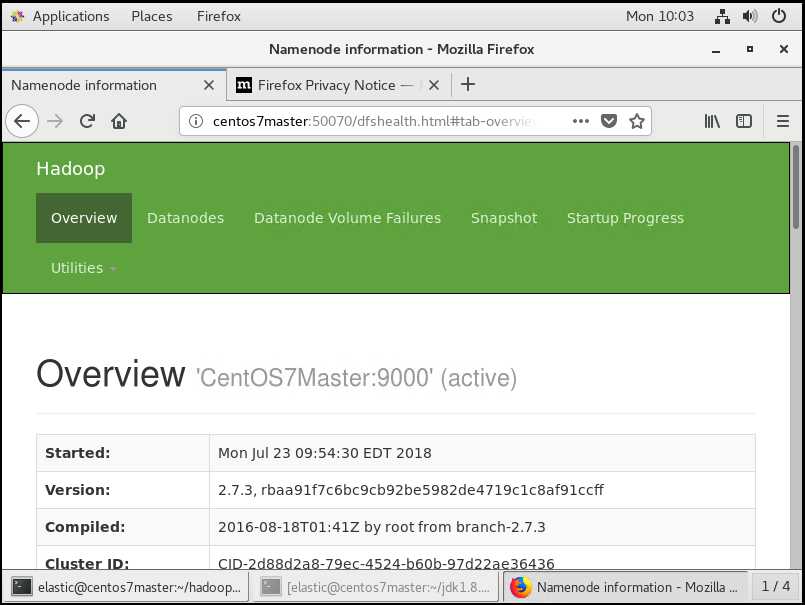
虚拟机上用hostanme
本来这个时候,Hadoop应该是告一段落,但是“应该”么。。。年轻人你想多了

事情是这样:format在我固化思维里,是比重启还好使的万能大法,只要硬盘不利索,我就直接format,但是hdfs的format,似乎不尽然,别忘了,人家hdfs的d可是Distributed,format的只是namenode,datanode还等着呢,在我手欠(对我又手欠了)又format了一遍namenode后,问题来了,集群datanode起不来了
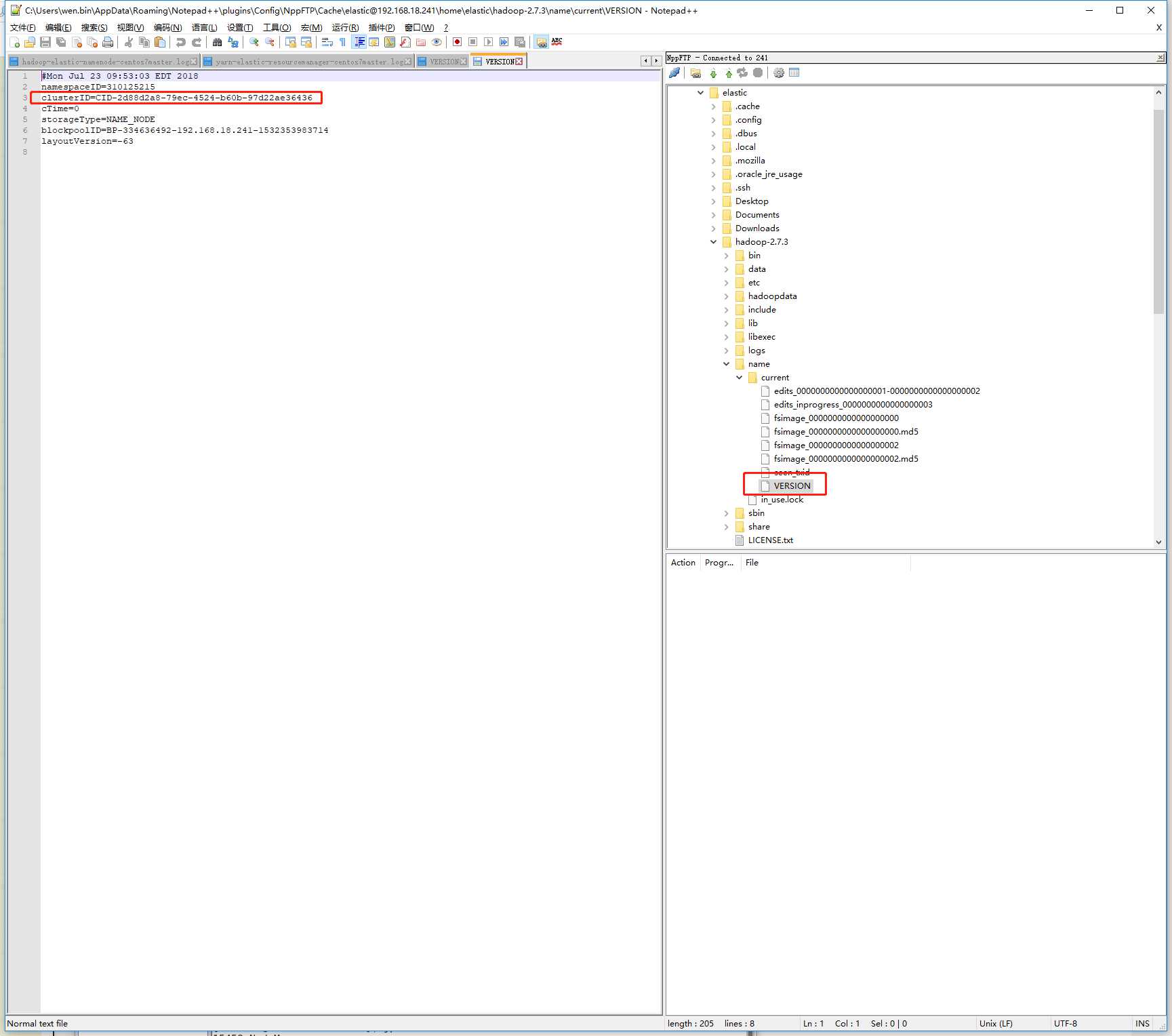
看一下namenode文件夹(hadoop-2.7.3/name),会发现current下有一个VERSION,里面有clusterID
datanode(slave下的hadoop-2.7.3/data)下,current里也有一个VERSION
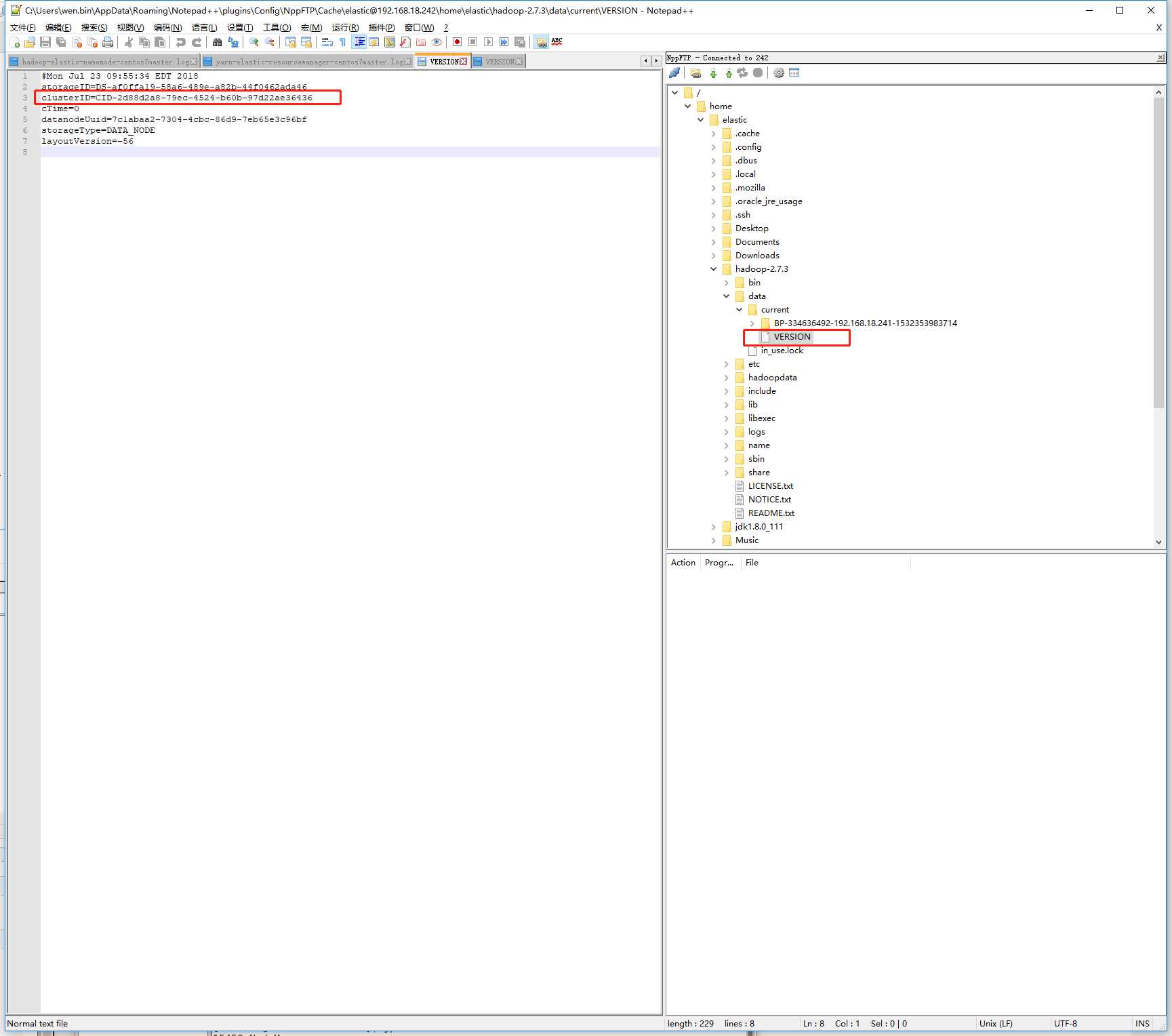
这两个本来是一样的,但是第二次format后,master下的namenode里clusterID变了,对不上了。。。
修改datanode里VERSION文件的clusterID 与namenode里的一致,再重新启动dfs(执行start-dfs.sh),datanode起来了
手欠有代价。。。
以上是关于CentOS7.4到Elasticsearch一路坑的主要内容,如果未能解决你的问题,请参考以下文章