字符识别--模型集成
Posted whitebear
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符识别--模型集成相关的知识,希望对你有一定的参考价值。
本节主要讲解如何使用集成学习来提高预测的精度
集成学习方法
在机器学习中的集成学习可以在一定程度上提高预测精度,常见的集成学习方法有Stacking、Bagging和Boosting,同时这些集成学习方法于具体验证集划分联系密切。
由于深度学习模型一般需要较长的训练周期,如果硬件设备不允许,建议采用留出法;如果需要追求精度可以使用交叉验证的方法
交叉验证法
假设构建10折交叉验证,训练得到10个CNN模型
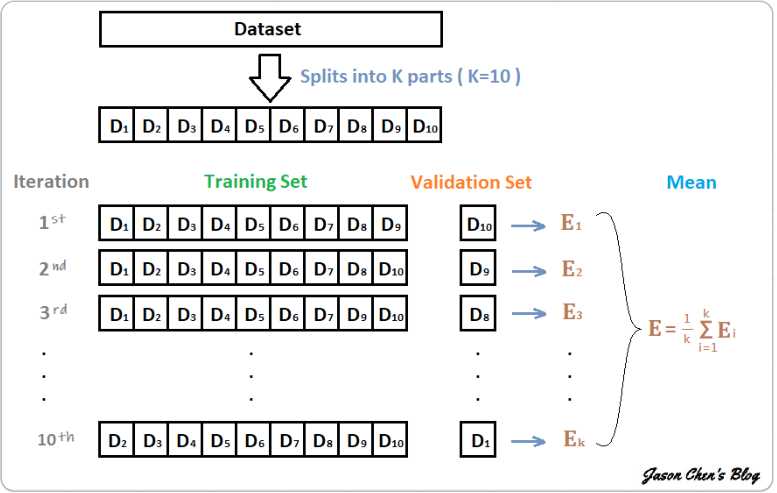
这10个CNN模型可以使用如下方式进行集成:
- 对预测的结果的概率值进行平均,然后解码为具体字符;
- 对预测的字符进行投票,得到最终字符
深度学习中的集成学习
Dropout
Dropout(随机失活) 可以作为训练深度神经网络的一种技巧,在每一次训练批次中,通过随机让一部分的节点停止工作,同时在预测的过程中让所有的节点都起作用
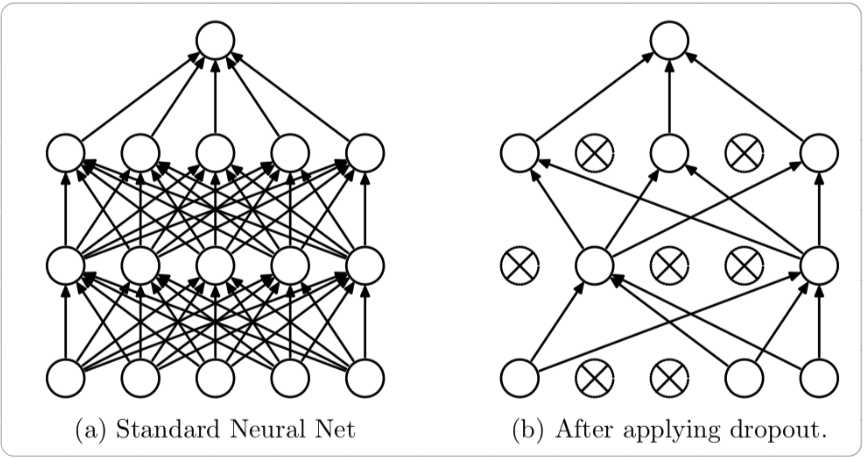
Dropout经常出现在现有的CNN网络中,可以有效缓解模型过拟合现象,也可以在预测时增加模型的精度。
加入Dropout后的网络结构代码实现:
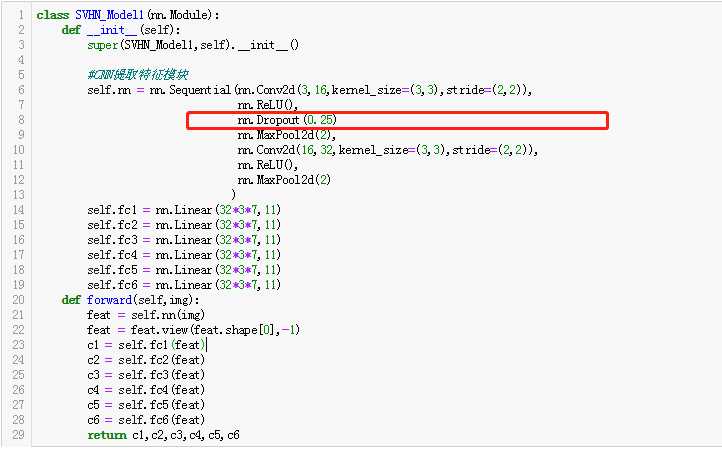

代码实现:
def predict(test_loader,model,tta=10):
model.eval()
test_pred_tta = None
#TTA次数
for _ in range(tta):
test_pred =[]
with torch.no_grad():
for i,(input,target) in enumerate(test_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
c0,c1,c2,c3,c4 = model(input)
target = target.long()
output = np.concatenate([
c0.data.numpy(),
c1.data.numpy(),
c2.data.numpy(),
c3.data.numpy(),
c4.data.numpy()
],axis = 1)
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
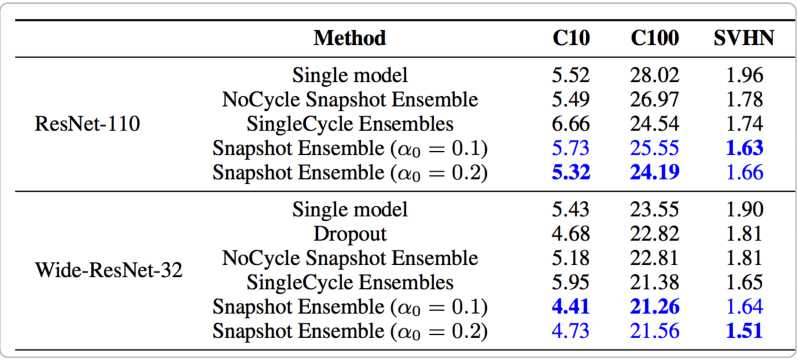
Snapshot
前面提到,加入训练了10个CNN则可以将多个模型的预测结果进行平均,但如果只训练一个CNN模型,那如何进行模型集成呢?
在论文Snapshot Ensembles中,作者提出了cyclical learning rate进行模型训练,并保存精度比较好的一些checkpoint,最后将多个checkpoint进行模型集成。
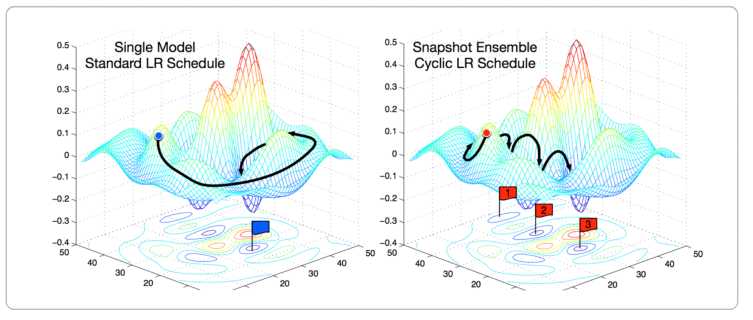
由于在cyclical learning rate中学习率的变化有周期变大和减小的行为,因此CNN模型很有可能在跳出局部最优进入另一个局部最优。在Snapshot论文中作者通过使用声明,此种方法可以在一定程度上提高模型精度,但需要更长时间训练
小结
两周的入门级的CV竞赛--字符识别终于要接近尾声了,非常感谢datawhale组织此次活动。这次我的目标就是熟悉整个深度学习训练过程的流程,从数据的获取,数据的增强,利用pytorch实现自定义网络(虽然是一个非常简单的网络),到数据(训练集、测试集还有测试集)喂给网络,也很遗憾,由于设备的问题,不能够进行多次的训练,得到的结果也不尽完善,但庆幸的是代码跑的通,所涉及的知识点基本补齐。再次感谢datawhale以及助教,你们辛苦了。
以上是关于字符识别--模型集成的主要内容,如果未能解决你的问题,请参考以下文章
使用片段时 Intellij 无法正确识别 Thymeleaf 模型变量