将验证码识别功能集成到现有的爬虫框架
Posted Java与Android技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了将验证码识别功能集成到现有的爬虫框架相关的知识,希望对你有一定的参考价值。
验证码的识别
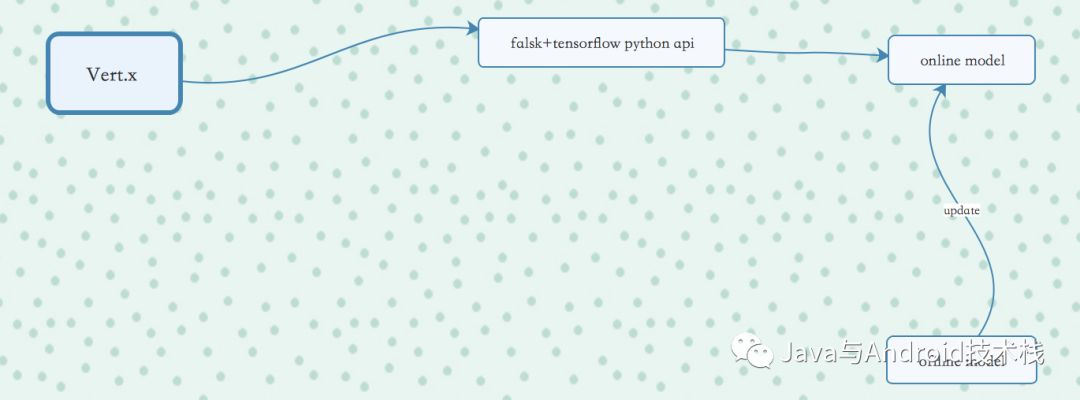
过年期间我曾经写过一篇文章, 目前已经对该功能做了一些优化,可以支持几种类型的验证码识别。其核心思想仍然是上一篇文章所提到的,使用tensorflow来训练标注过的验证码。目前,多种类型的验证码训练完之后可以放到一个模型中。未来,有新增的验证码类型通过训练之后也可以整合到这个模型中。
通过多次训练得到的经验大致是,一种类型的验证码标注4000-5000个数据,就能获得90%以上的识别准确率。
集成到爬虫框架
/**
* 返回验证码的内容
* @param imageUrl 验证码的url
* @return
*/
public static String getCaptcha(String imageUrl)
测试几张图片
System.out.println(Utils.getCaptcha("http://47.97.7.119/qianmou/images/captcha/1.png"));
System.out.println(Utils.getCaptcha("http://47.97.7.119/qianmou/images/captcha/2.png"));
System.out.println(Utils.getCaptcha("http://47.97.7.119/qianmou/images/captcha/3.png"));
System.out.println(Utils.getCaptcha("http://47.97.7.119/qianmou/images/captcha/4.png"));
System.out.println(Utils.getCaptcha("http://47.97.7.119/qianmou/images/captcha/5.png"));
System.out.println(Utils.getCaptcha("http://47.97.7.119/qianmou/images/captcha/6.png"));
执行结果:
862FF
7FA88
F3686
6D964
FE9FC
6494A
经过测试后,发现只有第一个验证码是识别错误的,其余五个都能够正确地识别出验证码中的数字和字母。
第一个验证码正确的值应该是862DF,而不是862FF。
识别完验证码之后,爬虫就可以模拟“用户”的登录行为,登录成功后记录下Header中的“Set-Cookie”的值,后面的操作就可以使用这个Cookie的值。
NetDiscovery的未来
首先,NetDiscovery需要增加多种类型验证码的识别,需要不断的标注数据。
其次,NetDiscovery打算做成一个比较通用的爬虫框架,虽然最近工作比较繁忙,但是每周仍然会有代码的提交。
下一个比较大的功能,应该是完成跟图像框架的结合。目前NetDiscovery的selenium模块可以实现对网页的截图,未来打算实现从截取的图片中提取有用的信息。这样从一定程度上能够对抗反爬虫。
关注【Java与Android技术栈】
更多精彩内容请关注:
以上是关于将验证码识别功能集成到现有的爬虫框架的主要内容,如果未能解决你的问题,请参考以下文章