HTTP 规范中的那些暗坑
Posted skychx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTTP 规范中的那些暗坑相关的知识,希望对你有一定的参考价值。

HTTP 协议可以说是开发者最熟悉的一个网络协议,「简单易懂」和「易于扩展」两个特点让它成为应用最广泛的应用层协议。
虽然有诸多的优点,但是在协议定义时因为诸多的博弈和限制,还是隐藏了不少暗坑,让人一不小心就会陷入其中。本文总结了 HTTP 规范中常见的几个暗坑,希望大家开发中有意识的规避它们,提升开发体验。
1.Referer
HTTP 标准把 Referrer 写成 Referer(少些了一个 r),可以说是计算机历史上最著名的一个错别字了。
Referer 的主要作用是携带当前请求的来源地址,常用在反爬虫和防盗链上。前段时间闹的沸沸扬扬的新浪图床挂图事件,就是因为新浪图床突然开始检查 HTTP Referer 头,非新浪域名就不返回图片,导致很多蹭流量的中小博客图都挂了。
虽然 HTTP 标准里把 Referer 写错了,但是其它可以控制 Referer 的标准并没有将错就错。
例如禁止网页自动携带 Referer 头的 <meta> 标签,相关关键字拼写就是正确的:
<!-- 全局禁止发送 referrer -->
<meta name="referrer" content="no-referrer" />
还有一个值得注意的是浏览器的网络请求。从安全性和稳定性上考虑,Referer 等请求头在网络请求时,只能由浏览器控制,不能直接操作,我们只能通过一些属性进行控制。比如说 Fetch 函数,我们可以通过 referrer 和 referrerPolicy 控制,而它们的拼写也是正确的:
fetch(‘/page‘, {
headers: {
"Content-Type": "text/plain;charset=UTF-8"
},
referrer: "https://demo.com/anotherpage", // <-
referrerPolicy: "no-referrer-when-downgrade", // <-
});
一句话总结:
凡是涉及到 Referrer 的,除了 HTTP 字段是错的,浏览器的相关配置字段拼写都是正确的。
二.「灵异」的空格
1.%20 还是 + ?
这个是个史诗级的大坑,我曾经被这个协议冲突坑了一天。
开始讲解前先看个小测试,在浏览器里输入 blank test( blank 和 test 间有个空格),我们看看浏览器如何处理的:

从动图可以看出浏览器把空格解析为一个加号「+」。
是不是感觉有些奇怪?我们再做个测试,用浏览器提供的几个函数试一下:
encodeURIComponent("blank test") // "blank%20test"
encodeURI("q=blank test") // "q=blank%20test"
new URLSearchParams("q=blank test").toString() // "q=blank+test"

代码是不会说谎的,其实上面的结果都是正确的,encode 结果不一样,是因为 URI 规范和 W3C 规范冲突了,才会搞出这种让人疑惑的乌龙事件。
2.冲突的协议
我们首先看看 URI 中的保留字,这些保留字不参与编码。保留字符一共有两大类:
gen-delims: :/?#[]@sub-delims: !$&‘()*+,;=
URI 的编码规则也很简单,先把非限定范围的字符转为 16 进制,然后前面加百分号。
空格这种不安全字符转为十六进制就是 0x20,前面再加上百分号 % 就是 %20:
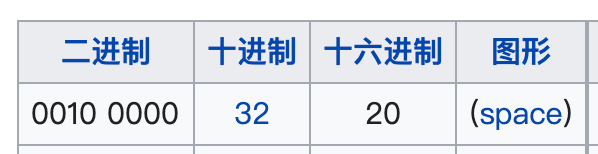
所以这时候再看 encodeURIComponent 和 encodeURI 的编码结果,就是完全正确的。
既然空格转为%20 是正确的,那转为 + 是怎么回事?这时候我们就要了解一下 html form 表单的历史。
早期的网页没有 AJAX 的时候,提交数据都是通过 HTML 的 form 表单。form 表单的提交方法可以用 GET 也可以用 POST,大家可以在 MDN form 词条上测试:

经过测试我们可以看出表单提交的内容中,空格都是转为加号的,这种编码类型就是 application/x-www-form-urlencoded,在 WHATWG 规范里是这样定义的:

到这里基本上就破案了,URLSearchParams 做 encode 的时候,就按这个规范来的。我找到了 URLSearchParams 的 Polyfill 代码,里面就做了 %20 到 + 的映射:
replace = {
‘!‘: ‘%21‘,
"‘": ‘%27‘,
‘(‘: ‘%28‘,
‘)‘: ‘%29‘,
‘~‘: ‘%7E‘,
‘%20‘: ‘+‘, // <= 就是这个
‘%00‘: ‘x00‘
}
规范里对这个编码类型还有解释说明:
The
application/x-www-form-urlencodedformat is in many ways an aberrant monstrosity, the result of many years of implementation accidents and compromises leading to a set of requirements necessary for interoperability, but in no way representing good design practices. In particular, readers are cautioned to pay close attention to the twisted details involving repeated (and in some cases nested) conversions between character encodings and byte sequences. Unfortunately the format is in widespread use due to the prevalence of HTML forms.这种编码方式就不是个好的设计,不幸的是随着 HTML form 表单的普及,这种格式已经推广开了
其实上面一大段句话就是一个意思:这玩意儿设计的就是 ??,但积重难返,大家还是忍一下吧
3.一句话总结
URI 规范里,空格 encode 为
%20,application/x-www-form-urlencoded格式里,空格 encode 为+实际业务开发时,最好使用业内成熟的 HTTP 请求库封装请求,这些杂活儿累活儿框架都干了;
如果非要使用原生 AJAX 提交
application/x-www-form-urlencoded格式的数据,不要手动拼接参数,要用URLSearchParams处理数据,这样可以避免各种恶心的编码冲突。
三.X-Forwarded-For 拿到的就是真实 IP 吗?
1.故事
在这个小节开始前,我先讲一个开发中的小故事,可以加深一下大家对这个字段的理解。
前段时间要做一个和风控相关的需求,需要拿到用户的 IP,开发后灰度了一小部分用户,测试发现后台日志里灰度的用户 IP 全是异常的,哪有这么巧的事情。随后测试发过来几个异常 IP:
10.148.2.122
10.135.2.38
10.149.12.33
...
一看 IP 特征我就明白了,这几个 IP 都是 10 开头的,属于 A 类 IP 的私有 IP 范围(10.0.0.0-10.255.255.255),后端拿到的肯定是代理服务器的 IP,而不是用户的真实 IP。
2.原理
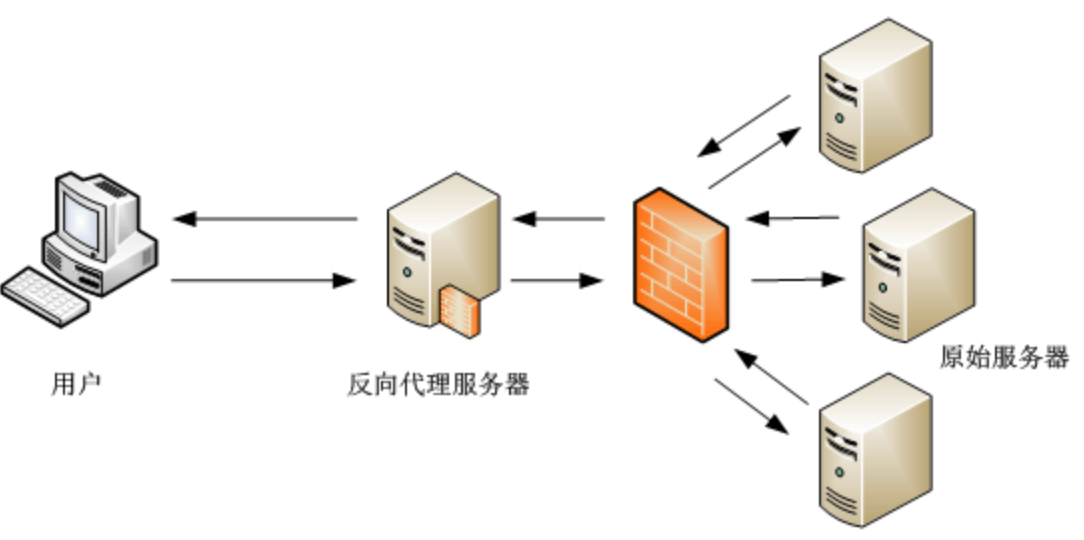
现在有些规模的网站基本都不是单点 Server 了,为了应对更高的流量和更灵活的架构,应用服务一般都是隐藏在代理服务器之后的,比如说 nginx。
加入接入层后,我们就能比较容易的实现多台服务器的负载均衡和服务升级,当然还有其他的好处,比如说更好的内容缓存和安全防护,不过这些不是本文的重点就不展开了。
网站加入代理服务器后,除了上面的几个优点,同时引入了一些新的问题。比如说之前的单点 Server,服务器是可以直接拿到用户的 IP 的,加入代理层后,如上图所示,(应用)原始服务器拿到的是代理服务器的 IP,我前面讲的故事的问题就出在这里。
Web 开发这么成熟的领域,肯定是有现成的解决办法的,那就是 X-Forwarded-For 请求头。
X-Forwarded-For 是一个事实标准,虽然没有写入 HTTP RFC 规范里,从普及程度上看其实可以算 HTTP 规范了。
这个标准是这样定义的,每次代理服务器转发请求到下一个服务器时,要把代理服务器的 IP 写入 X-Forwarded-For 中,这样在最末端的应用服务收到请求时,就会得到一个 IP 列表:
X-Forwarded-For: client, proxy1, proxy2
因为 IP 是一个一个依次 push 进去的,那么第一个 IP 就是用户的真实 IP,取来用就好了。
但是,事实有这么简单吗?
3.攻击
从安全的角度上考虑,整个系统最不安全的就是人,用户端都是最好攻破最好伪造的。有些用户就开始钻协议的漏洞:X-Forwarded-For 是代理服务器添加的,如果我一开始请求的 Header 头里就加了 X-Forwarded-For ,不就骗过服务器了吗?
1. 首先从客户端发出请求,带有 X-Forwarded-For 请求头,里面写一个伪造的 IP:
X-Forwarded-For: fakeIP
2. 服务端第一层代理服务收到请求,发现已经有 X-Forwarded-For,误把这个请求当成代理服务器,于是向这个字段追加了客户端的真实 IP:
X-Forwarded-For: fakeIP, client
3. 经过几层代理后,最终的服务器拿到的 Header 是这样的:
X-Forwarded-For: fakeIP, client, proxy1, proxy2
要是按照取 X-Forwarded-For 第一个 IP 的思路,你就着了攻击者的道了,你拿到的是 fakeIP,而不是 client IP。
4.破招
服务端如何破招?上面三个步骤:
第一步是客户端造假,服务器无法介入 第二步是代理服务器,可控,可防范 第三步是应用服务器,可控,可防范
第二步的破解我拿 Nginx 服务器举例。
我们在最外层的 Nginx 上,对 X-Forwarded-For 的配置如下:
proxy_set_header X-Forwarded-For $remote_addr;
什么意思呢?就是最外层代理服务器不信任客户端的 X-Forwarded-For 输入,直接覆盖,而不是追加。
非最外层的 Nginx 服务器,我们配置:
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
$proxy_add_x_forwarded_for 就是追加 IP 的意思。通过这招,就可以破解用户端的伪造办法。
第三步的破解思路也很容易,正常思路我们是取X-Forwarded-For 最左侧的 IP,这次我们反其道而行之,从右边数,减去代理服务器的数目,那么剩下的 IP 里,最右边的就是真实 IP。
X-Forwarded-For: fakeIP, client, proxy1, proxy2
比如说我们已知代理服务有两层,从右向左数,把 proxy1 和 proxy2 去掉,剩下的 IP 列表最右边的就是真实 IP。
相关思路和代码实现可参考 Egg.js 前置代理模式。
5.一句话总结总结
通过 X-Forwarded-For 获取用户真实 IP 时,最好不要取第一个 IP,以防止用户伪造 IP。
四.略显混乱的分隔符
1.HTTP 标准
HTTP 请求头字段如果涉及到多个 value 时,一般来说每个 value 间是用逗号「,」分隔的,就连非 RFC 标准的 X-Forwarded-For,也是用逗号分隔 value 的:
Accept-Encoding: gzip, deflate, br
cache-control: public, max-age=604800, s-maxage=43200
X-Forwarded-For: fakeIP, client, proxy1, proxy2
因为一开始用逗号分隔 value,后面想再用一个字段修饰 value 时,分隔符就变成了分号「;」,最典型的请求头就是 Accept 了:
// q=0.9 修饰的是 application/xml,虽然它们之间用分号分隔
Accept: text/html, application/xml;q=0.9, */*;q=0.8
虽然 HTTP 协议易于阅读,但是这个分隔符用的还是很不符合常识的。按常理来说,分号的断句语气是强于逗号的,但是在 HTTP 内容协商的相关字段里却是反过来的。这里的定义可以看 RFC 7231,写的还是比较清楚的。
2.Cookie 标准
和常规认识不同,Cookie 其实不算 HTTP 标准,定义 Cookie 的规范是 RFC 6265,所以分隔符规则也不一样了。规范里定义的 Cookie 语法规则是这样的:
cookie-header = "Cookie:" OWS cookie-string OWS
cookie-string = cookie-pair *( ";" SP cookie-pair )
多个 cookie 之间是用分号「;」分隔的,而不是逗号「,」。我随便扒了个网站的 cookie,可见是用分号分隔的,这里需要特别注意一下:

3.一句话总结
大部分 HTTP 字段的 value 分隔符是逗号「,」
Cookie 不属于 HTTP 标准,分隔符是分号「;」
五、文章推荐
下面我要推荐我的几篇文章:
一篇介绍了 webpack 中最易混淆的 5 个知识点,掘金快 800 赞了,一文讲清楚 Webpack 中那些长得像却意义不同的概念 一篇详细介绍了 webpack dll 是个什么东西,并且给出了 2 条最佳实践,摆脱繁琐的 dll 配置 React Native 性能优化指南从渲染层的角度分析了 RN 性能优化的 6 个点,并以图文形式讲解了 FlatList 的实现原理 Web Scraper——轻量数据爬取利器 介绍了一个小巧的浏览器爬虫插件,可以实现简单的数据爬取功能
最后推荐一下我的个人公众号:「卤蛋实验室」,平时会分享一些前端技术和数据分析的内容,大家感兴趣的话可以关注一波:

以上是关于HTTP 规范中的那些暗坑的主要内容,如果未能解决你的问题,请参考以下文章