案例分享:巧用各种工具提升无源码系统的性能和稳定性
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了案例分享:巧用各种工具提升无源码系统的性能和稳定性相关的知识,希望对你有一定的参考价值。
案例分享:巧用各种工具提升无源码系统的性能和稳定性
导读:在没有核心系统源码的情况下,修改源码打印耗时的方法无法使用,通过tcpdump、wireshark、gdb、010 editor、火焰图、ida、数据库抓sql耗时语句、oracle ash报告、loadrunner等工具找到了服务器tps上不去,C程序进程随机挂掉的问题,并顺利解决,收获颇多。
 杨振,宜信工程师,前微博feed组工程师,对源码学习感兴趣
杨振,宜信工程师,前微博feed组工程师,对源码学习感兴趣
 董建,宜信工程师,前微博工程师,关注大数据和高可用技术
董建,宜信工程师,前微博工程师,关注大数据和高可用技术
背景:
公司最近新上线一个系统,主要架构如下: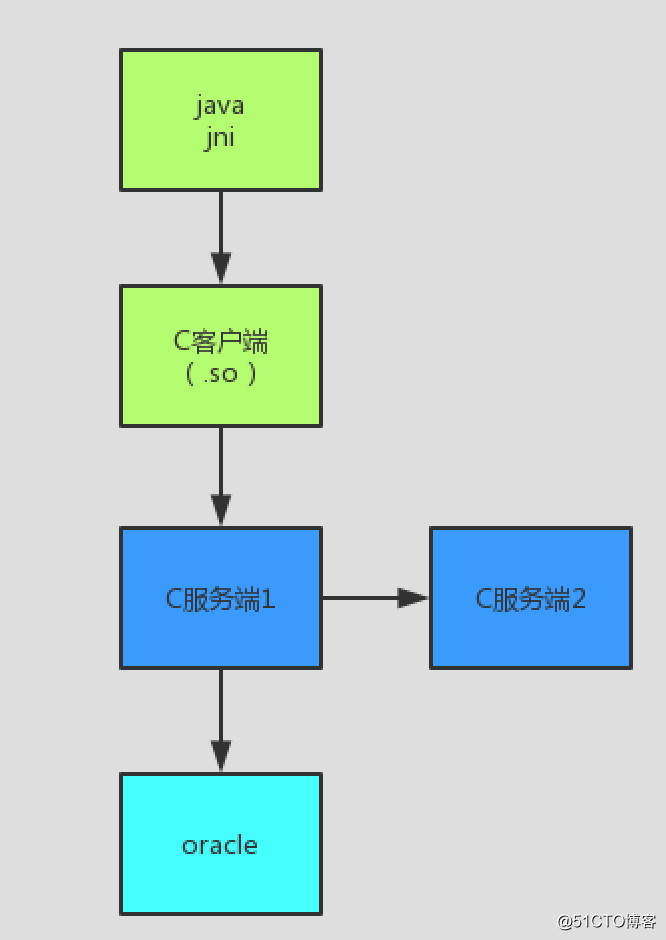
测试环境系统部署后,出现了两个问题:
- loadrunner压测tps上不去,压测java接口tps 单机只能到100多tps就上不去了,耗时从单次访问的100ms上升到110并发时的1s左右。
2.压测期间C服务器1 经常不定时挂掉。
因为某些原因,该项目C相关程序没有源码,只有安装部署文件,为了解决上述两个问题,我们几个同事和重庆同事一块参与问题排查和解决。因为没有源码,中间经历了层层波折,经过一个月努力,终于解决了上述两个问题,整个排查过程学到了很多知识。
用到的分析工具:
1.tcpdump,
2.wireshark,
3.gdb,
4.010 editor,
5.火焰图,
6.ida,
7.数据库抓sql耗时语句,
8.oracle ash报告,
9.loadrunner
几句话总结:
- C程序客户端socket长连接调用C服务端存在性能瓶颈,通过tcpdump,wireshark 二进制分析出传输协议后改用java调用C服务端,单机tps提升1倍,性能提升3倍
- 数据库语句存在for update 语句导致并发上不去,经过分析从业务上采用sequence 替换for update语句,并通过010 editor直接修改二进制 修改for update 语句相关逻辑为sequence ,系统具备了扩容服务器tps也能同步提升的能力
- 数据库insert语句并发情况下存在瓶颈,扩大oracle redo log日志大小解决,继续提升tps40%。
- 程序进程随机挂掉,通过gdb分析core dump文件,定位到在并发情况下程序中使用的gethostbyname有问题,采用临时方法解决。
分析过程:
1.第一次瓶颈定位
刚开始排查问题时,loadrunner压测java接口,并发用户从0逐渐增加到110个的情况下,tps到100左右就不再提升,响应耗时从100ms增大到1s。此时我们的分析重点是谁是当前的主要瓶颈
再看一遍架构图, 图中5个节点都有可能是瓶颈点,数据库此时我们通过数据库dba管理权限抓取耗时sql,没抓取到,先排除数据库问题,java的我们打印分步耗时日志,定位到jni调用 c客户端耗时占比最大。这时瓶颈点初步定位到C客户端,C服务端1,C服务端2 这三个节点。
因为没有源码,我们采用tcpdump抓包分析,在C服务器1上
tcpdump -i eth0 -s 0 -w aa.txt host java客户端ip
抓出的包用wireshark分析
通过追踪流-TCP流 分析服务端耗时并没有变的太大,因为C客户端和C服务端是长连接,多个请求可能会共用一个连接,所以此时分析出的数据可能会不太准,因此我们采用loadrunner压测,其它条件不变,一台C服务器1和两台C服务器1分别查看耗时变化,
其它条件不变,一台java服务器和两台java服务器分别查看耗时变化.
最终定位到是C客户端的问题。(ps:在wireshark的分析数据时还跟秦迪大师弄明白了tcp延迟确认)
2.改造C客户端
C客户端和C服务端是通过长连接通信的,直接改造C代码难度较大,所有我们准备把C替换成java,这就需要分析C之间通信传参时候用的什么协议,然后根据这个协议用java重写。我们根据之前的经验推测出了编码协议,用wireshark分析二进制确认确实是这种编码。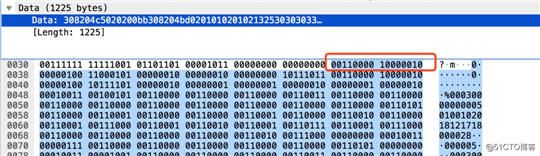
我们根据这种协议编码采用java重写后,同样在110并发用户情况下,tps提升到了210(提升两倍),耗时降到了330ms(是原来的三分之一)
3.第二次瓶颈定位。
经过第二步优化后tps提升了两倍,但是此时扩容tomcat,扩容C服务器,tps就维持在210左右,不会变高了。因此我们继续进行定位新的瓶颈点。此时找dba要到一个实时查看oracle 耗时sql的语句
select
(select b.SQL_TEXT from v$sqlarea b where b.SQL_ID=a.SQL_ID ) sqltxt,
(select c.SQL_FULLTEXT from v$sqlarea c where c.SQL_ID=a.SQL_ID ) sqlfulltxt,
a.username, a.LAST_CALL_ET,a.MACHINE ,a.command, a.EVENT, a.SQL_ID ,a.SID,a.SERIAL#,
‘alter system kill session ‘‘‘ || a.SID ||‘,‘||a.SERIAL# ||‘‘‘;‘ as killstment
from v$session a
where a.STATUS = ‘ACTIVE‘
and a.USERNAME not in (‘SYS‘, ‘SYSTEM‘)
order by
a.LAST_CALL_ET desc ,a.username,a.MACHINE ,a.command, a.EVENT, a.SQL_ID ,a.SID;
发现有个for update的sql 并发量大的时候部分请求 LAST_CALL_ET列的值能达到6秒,for update导致了所有请求被串行执行,影响了并发能力。我们经过分析业务逻辑后,用sequence暂时替换 for update 语句,但是我们没有源码,没法修改,后来又通过010 editor 直接修改二进制文件,通过010 editor 查询找到了 for update 语句,顺利替换。
替换后,4台C服务器tps达到了580,提升了2.7倍(580/210),系统初步具备了横向扩展能力
4.第三次瓶颈定位。
经过上一步改造,4台C服务器时系统的tps提升了2.7倍,但是并没有提升到4倍(210*4=840),没有线性提升,说明还是有别的瓶颈,又通过dba上边给的sql发现insert 语句偶尔耗时也很长,在1s左右,EVENT等待事件是IO事件,DBA同事给修改了redo log file 大小(这个是测试环境Oracle,之前没有优化),从默认的50M,修改为1G, tps 提升到了640 (还没提升到4倍,也就是说还有瓶颈,可能还是数据库,但因为数据库暂时没办法抓取到毫秒级的耗时sql,没再继续追查)
经过这几次性能提升,加上我们测试服务器配置都不高,如果线上服务器性能预估能达到1000tps,基本满足眼前需求,因此就没再继续进行性能优化。
5.程序进程随机挂掉问题。
压测过程中,C服务器进程经常随机挂掉,通过tail -f /var/log/messages 发现生成了core dump 文件,但是又被系统自动删除了。董建查到了开启core dupm文件的方法,如下:
a、ulimit -c
查看是否为0,如果为0,表示coredump文件设置为0,需要修改为不限制
ulimit -c unlimited
b、修改/etc/abrt/abrt-action-save-package-data.conf
ProcessUnpackaged = yes
修改后进程又崩溃时core dump 文件生成了,进入core dump 目录进行调试
gdb 脚本路径 coredump
bt 显示堆栈信息
继续执行如下命令
f 0
set print pretty on
info local //显示当前函数中的局部变量信息。
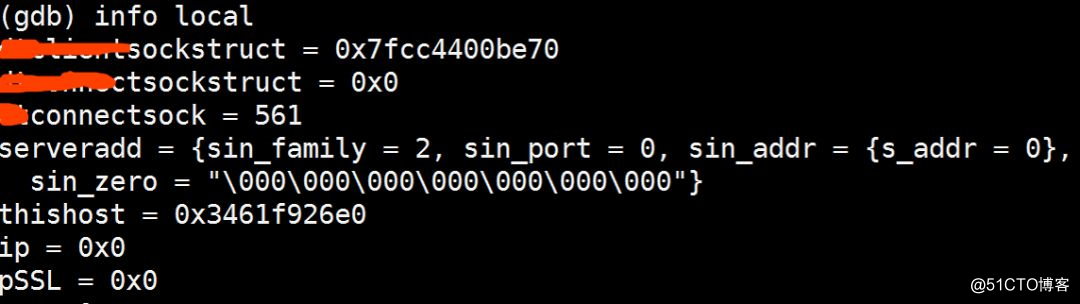
通过p命令查看里边变量的值
发现变量thishost->h_addr_list的值为null
我们分析可能是并发请求时有方法不是线程安全的导致这个值为null,从而引起了进程crash,继续调试。
在gdb中 set logging on 把调试信息输出到文件
thread apply all bt 输出所有的线程信息。
退出gdb
grep --color -i clientconnect -C5 gdb.txt

确实有两个线程并发在访问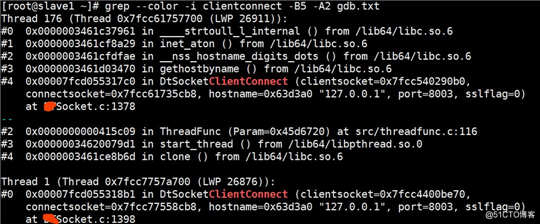
通过ida工具反编译so,最终定位到以下语句在并发时有问题,thishost中的变量可能会被另一个线程在一瞬间初始化为null。
thishost = gethostbyname((const char )hostname);
ip = inet_ntoa((struct in_addr )thishost->h_addr_list);
根据我们的项目特点,因为我们没有远程调用,C服务端1和C服务端2都部署在了同一台服务器上,所以我们通过修改二进制把地址暂时写死成了127.0.0.1,把ip = inet_ntoa((struct in_addr )*thishost->h_addr_list);修改成了空指令,重新部署后没再出现系统崩溃的问题。
相关阅读:
- Go存储怎么写?深度解析etcd存储设计
- SpringBoot 究竟是如何跑起来的?
- 混沌工程实践指南——如何实施一次"完美"的冷启动
- 阿里云mysql及Redis灵异断连现象:安全组静默丢包解决方法
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。
高可用架构
改变互联网的构建方式

以上是关于案例分享:巧用各种工具提升无源码系统的性能和稳定性的主要内容,如果未能解决你的问题,请参考以下文章