读书随笔图像处理单元 GPU:《Real-Time Rendering》fourth Edition Chapter 3
Posted thdt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读书随笔图像处理单元 GPU:《Real-Time Rendering》fourth Edition Chapter 3相关的知识,希望对你有一定的参考价值。
本文总结了 Real-Time Rendering (第四版) 中第三章的内容
这里仅总结在书中自己认为或者不懂的要点并结合实际工作学习所需,若内容讲解不详细还请谅解
随着市场对计算机图形渲染的需求越来越大,图像处理单元 GPU 产生了。因为图像渲染管线需要处理大量的,重复的简单计算,为了实现渲染效率,GPU 则被设计成高度并行式的计算模式。GPU用于在短时间进行大量的关于顶点,图元和像素的计算,GPU 的每一个硅晶体可以同时处理这些运算。
GPU 最开始是难以被编程的,但随着 GPU 的发展,GPU 在往灵活的,可编程的方式发展。其中,着色器(shader)就是进行 GPU 编程的主要形式。着色器可以进行顶点处理,几何坐标变换,像素颜色处理等。随着成千上万的图元被送入 GPU 中,每秒钟也会有无数的着色器结合渲染指令处理它们。
一个着色器处理一次图元的过程叫做 shader invocations(在这里是指一个片元在 shader 中从头到尾一次处理),其中一个 shader invocation 对片元(注意是片元 fragment)的处理叫一个线程(Thread),进行相同着色处理的线程叫做一个 Wrap (NVIDIA 术语,AMD术语叫做 wavefront)。在 NIVIDIA GPU 中,一个 wrap 有 32 个线程(32 的倍数可以方便的映射到硬件上从而提升效率 [3])。
-
Data-Parallel Architectures
与 CPU 能够处理多种数据结构和大块复杂代码的功能不同,GPU 只能处理固定的图像相关数据和着色器代码。但 GPU 在处理单指令多数据(SIMD)的效率则远远高于 CPU,这主要得益于 GPU 的并行设计模式:每一个处理单元都是独立的,且数据流会被分配到各个处理单元内并行处理,这种处理器也叫做流处理器(stream processor),其中 GPU 的每一个运算处理单元被叫作着色器核心(shader cores)。CPU 和 GPU 的硬件架构不同可见下图:
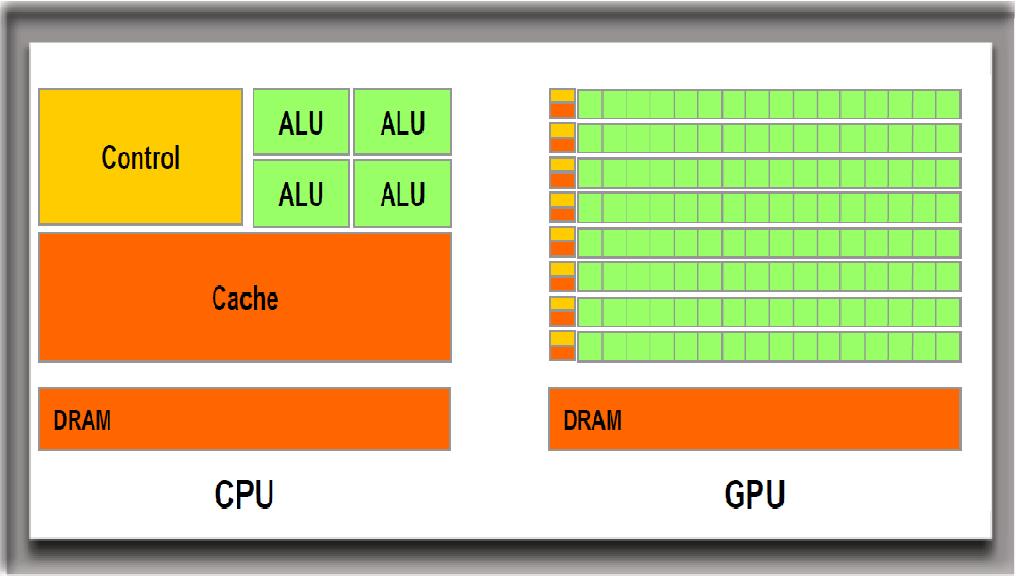
图 1:CPU vs GPU: 黄色为控制单元,橘色为存储单元(DRAM / Cache),绿色为算数逻辑单元(ALU)[t1]
GPU 优化了吞吐量(throughput),也就是单次可处理的最大数据量。GPU 处理图元数据流的方式则是使用了 SIMD 的思想:将所有图元使用一个指令进行处理,然后再执行下一个指令处理所有的图元。这样可以有效的加速对所有图元的处理,并且避免了频繁切换指令而造成的效率损失。尽管看来处理单个图元的时间增长了,但整体效率却提高了。
相对于 CPU 的低延迟和低吞吐量,GPU 则采用了高延迟和高吞吐量的设计:因为要尽可能单次处理更多的数据,所以要尽可能保证一次处理的数据量能够充分的利用所有的计算资源。可以想象成一个罐头工厂,工厂生产一个罐头需要启动所有机器一次,工厂要生产一百个罐头也要启动所有机器一次(假设生产多个罐头同时完成),所以要尽可能地少开关机器,并一次能多生产罐头。
在处理每一个线程也是遵循同样的原理:如上面所说,所有执行相同着色操作的线程将会被封装成一个 wrap。其中,为了减少延迟,GPU 可以对每一个 wrap 进行一个或者一系列处理后切换到到(swap)下一个 wrap:比如对于第一个 wrap 处理的最后一个步骤需要一定的时间去提取数据,在等待对第一个 wrap 处理的最后一步返还提取数据时,GPU 会对第二个 wrap 进行和对第一个 wrap 相同的处理。循环往复直到处理完所有的线程。这也是基于了 SIMD-processing 的思想以加快处理效率。书中给了一个简单的例子(见图 2):
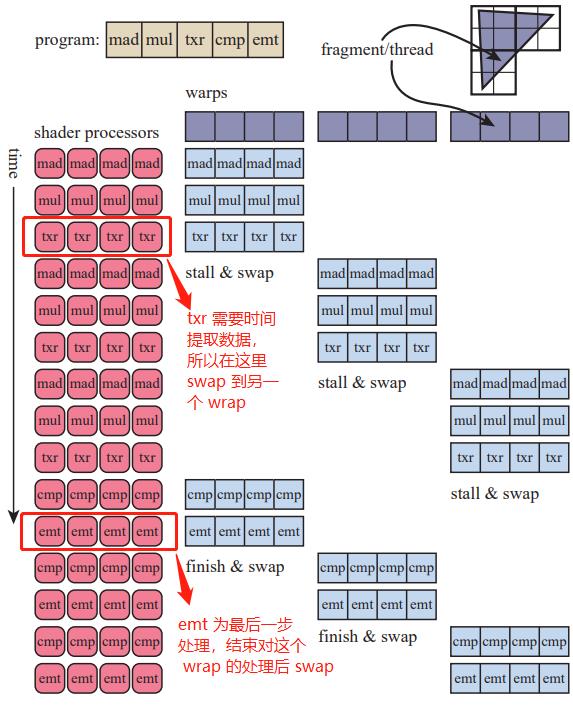
图 2:处理多个指令,多个 wrap(假设能同时处理 32 个线程,即一个 wrap)
Shader 的结构也会影响 GPU 的效率。简而言之:越复杂的 shader 会使 GPU 效率降低,主要原因是复杂的 shader 将会占用大量的存储资源(在书中的体现是寄存器 register),当一个 shader 使用的 寄存器越多时,GPU 单次能处理的线程也就越少,这时线程的在 GPU 中的占有量(occupancy)也就越少。低占有量意味着 GPU 的效率越低,单次能处理的线程越少。
另一个原因是在 shader 中的动态分支(dynamic branching)造成的性能损耗,也就是 if statement 所造成的;如果一个 wrap 里面的数据有些在一个 if statement 判 true,有些判 false,那么这个 wrap则要被执行两次,且针对不同的 branch 只保留一半结果。 这个现象叫做 thread divergence。
-
GPU 管线概述(GPU Pipeline Overview)

图 3:GPU 的渲染管线实现。其中绿色是可编程的,虚线部分是可选择实现部分,黄色部分是可调设置的,蓝色部分不可调节
GPU 渲染管线的实现基于实时渲染管线的架构(具体见这篇随笔)。随着开发需求越来越趋近追求灵活性,图形管线部分可编程或可调节的部分在逐渐变多,其中最为典型的就是着色器的使用。
-
可编程着色器阶段(The Programmable Shader Stage)
顶点,像素,几何结构等是构成渲染元素的核心,他们本身就有一套相似的指令集架构处理(被相同硬件处理,数据结构相似,可以使用相似的指令集进行处理)。现代渲染模型基于顶点,像素,几何结构等通用模型设计出一套通用着色器核心(common-shader core,DX术语)。基于这些通用核心,GPU 可以在渲染时将工作分为处理顶点,像素或其他种类,以此均衡计算资源的使用。也是基于这套核心,图形 API 设计不同的着色器语言来进行图像处理,比如 DirectX 的 HLSL(high level shading language)和 OpenGL 的 GLSL(OpenGL Shading Language)。
当 draw 指令被唤起,图形 API 会对图元开始绘制,这时着色器将会被启用,这个阶段既是着色器阶段(shader stage)。每个着色器阶段有两种输入:常量输入(uniform inputs)和变量输入(varying inptus)。常量输入的值在每一次 draw 指令期间都不会变,但在不同的 draw 指令之间可以被改变。变量输入通常是来自于图元,比如顶点或者像素。举个例子:一个像素着色器中的光的颜色是常量输入,三角形顶点输入一直在变所以是变量输入。这里注意贴图是一个特别的常量输入,因为贴图会被视为一个很大的颜色数组。
着色器虚拟机(shader virtual machine)会为输入输出提供不同的寄存器,其中常量寄存器(constant registers)给常量输入输出的储存空间远远大于那些分配给变量的寄存器。这是因为常量寄存器需要储存会被重复使用的数据,而变量寄存器不需要。虚拟机也提供临时寄存器(temporary register)用于使用涂销空间(Scratch space),所有类型的寄存器都可以通过临时寄存器内的数组索引找到。着色器虚拟机的输入结构如下:
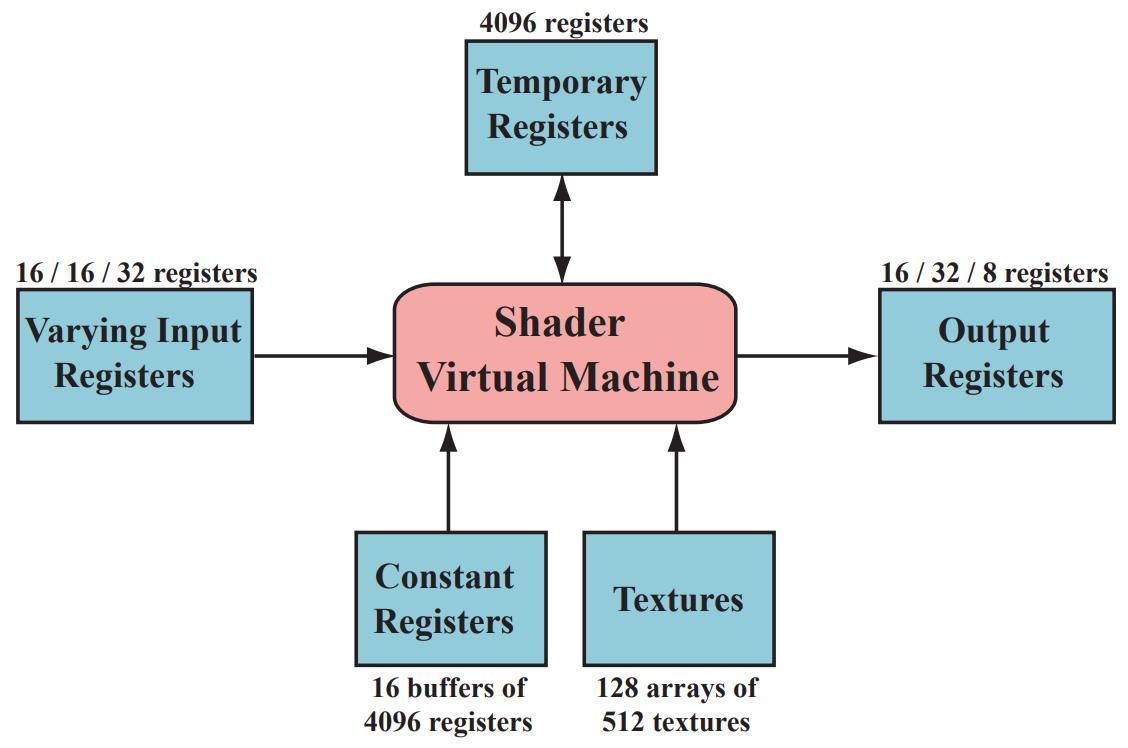
图 4:着色器虚拟机处理输入输出结构
在着色器中需要进行流量控制(flow control,主要体现在分流,例如 if else)以处理不同类型的输入。着色器主要支持两种流量控制方式,一种是针对常量输入的静态流量控制(static flow control),静态流量控制中的代码在 draw call 中一直保持不变,它的主要优势是在于可以不同情况下使用同一个着色器,比如在多组光处理中使用相同的着色器,这并不会造成 thread divergence,因为所有的处理都使用了相同的代码。另一种是动态流量控制(Dynamic flow control),它基于变量输入的值,意味着每个片元都可以执行不同的代码。动态流量控制相比静态能适应更复杂的情况,但代价就是性能的损耗,尤其体现在在不同的 shader invocation 间来回切换。
-
The Evolution of Programmable Shading and APIs
(书中这个章节讲了 shader 和图形 API 的发展历程,有兴趣的朋友可以了解下,在此略过)
-
顶点着色器(The Vertex Shader)
在介绍顶点着色器之前,我们有必要先了解一下顶点:顶点(vertex)是模型中的最基本元素,一个顶点有它在模型空间内的具体位置。除了位置外,顶点还有一些可选的属性,比如颜色,贴图坐标以及顶点法线(注:文中提到过面法线,但在实际工作中的大部分使用的都是顶点法线,因为三角形面不一定是平的,详见下图)。
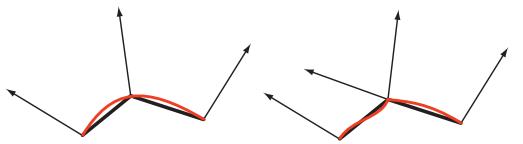
图 5:顶点法线(箭头)与三角形面(红色曲线),左边为平滑表面,右边为弯曲表面
然而在进行顶点着色之前,我们还需要先处理输入数据并将它们组合成顶点着色器能处理的形式,这个步骤叫做输入组装(input assembler,DX 术语)。输入组装将读入的原始数据组装成网格模型,输出一个或多个多边形网格(polygon mesh)模型,其中三角形网格(triangle mesh)模型是最常见的网格模型,其中一个模型由多个顶点组成。在组装完毕后发送给管线的第一步进行顶点着色处理,也就是顶点着色器。
顶点着色处理(vertex shading)是 GPU 渲染管线的第一步,它直接处理每个输入顶点,可以对每个顶点数据属性进行修改,创建或忽视顶点内数据,比如修改顶点的位置或颜色以达到期待的效果。顶点着色器最基本的功能是将模型空间中的顶点数据转换为齐次坐标,这里牵扯几何坐标的转换。顶点着色器输出的数据可被后面多个阶段使用。
-
曲面细分阶段(The Tessellation Stage)
曲面细分阶段可以渲染曲面部分,在这个阶段 GPU 提取面的信息进而生成一系列表示曲面的三角形面。之所以不在模型中直接生成曲面而是用曲面细分的方式是有原因的,具体如下:
- 节省储存资源:试想一下如果游戏引擎每次都需要加载一个三角形面数极多的模型,那么内存需要在 CPU 和 GPU 之间传递非常大的数据。然而这个过程可以在 GPU 中通过少量面数据进行计算得到需要的曲面效果,从而降低内存压力。
- 降低数据传输压力:理由同上,传递少量数据再在 GPU 内计算曲面可减少 CPU 与 GPU 之间总线传输压力。
- 维持帧率:当在不需要渲染太多细节时,停止曲面细分可以维持帧率。比如一个物体里镜头很远时,可以减少其三角形的面数来维持帧率,而当需要展示细节时则开启曲面细分或者恢复之前隐藏的面或顶点。这个操作叫做控制 LOD(level of detail)。
曲面细分阶段主要有三个子阶段:
- 细分控制着色器(OpenGL 叫做 tessellation control shader, DX 叫做 hull shader):接受细分曲面,处理控制点(Control Point,本质是顶点)。输出一系列控制点到 domain shader,输出细分因素(tessellation factors)给细分器。细分因素决定细分方式。
- 细分器(OpenGL 叫做 primitive generator, DX 叫做 tessellator):增加新顶点,传递给 domain shader。
- 细分计算着色器(OpenGL 叫做 tessellation evaluation shader, DX 叫做 domain shader):计算新顶点位置,输出曲面细分后的模型。
这三个阶段由 1 到 3 传递并处理数据,其中 hull shader 和 domain shader 可被编程。过程如下:
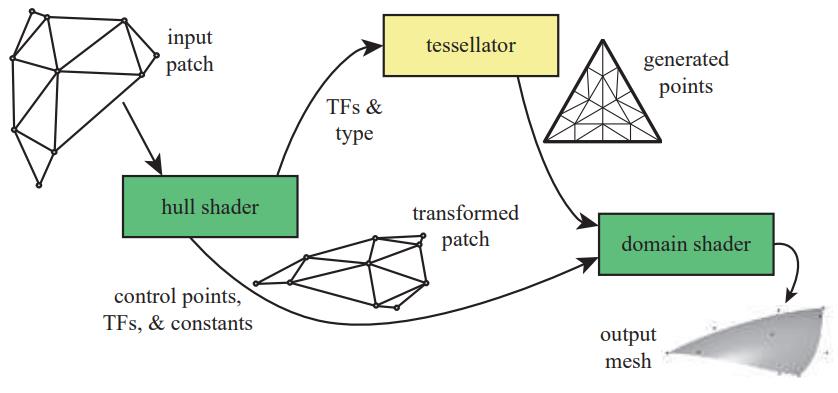
图 6:曲面细分过程
-
几何着色器(The Geometry Shader)
几何着色器基于现有图元生成新的图元,顶点着色和曲面细分无法实现这一点。几何着色器可以实现诸如粒子特效等效果。
《=== TO BE CONTINUE
参考资料:
[1] Real-Time Rendering fourth Edition (大部分内容以及图片来自于此书)
以上是关于读书随笔图像处理单元 GPU:《Real-Time Rendering》fourth Edition Chapter 3的主要内容,如果未能解决你的问题,请参考以下文章
《Real-Time Rendering》第四版学习笔记——Chapter 3 The Graphics Processing Unit
《Real-Time Rendering》第四版学习笔记——Chapter 3 The Graphics Processing Unit