《Real-Time Rendering》第四版学习笔记——Chapter 3 The Graphics Processing Unit
Posted 董小虫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Real-Time Rendering》第四版学习笔记——Chapter 3 The Graphics Processing Unit相关的知识,希望对你有一定的参考价值。
引言
GPU设计的初衷是为了图形加速,而且GPU对CPU的唯一优势就是图形计算速度。
GPU通过专注于高度并行的少量任务来获取高速度。GPU会专门提供定制化的芯片来实现深度缓冲、快速访问纹理图像、查找三角形覆盖像素等等。
每一个着色器核心都是一个处理相对独立任务的小型处理器。
所有的处理器都面临着延迟的问题。而访问数据会消耗一些时间。通常情况下,我们可以认为,信息离处理器越远,时间消耗越多。这里的关键点就是,等待数据会导致处理器停顿,进而影响性能。
一、数据并行结构
CPU避免停顿的主要策略是处理大量不同的数据结构和代码。CPU拥有多个处理器,但是每个处理运行代码的方式偏向于串行,限制SIMD处理,最小化异常。并且CPU包含快速局部寄存器,保存之后可能会处理的数据。一些例如分支预测、寄存器重命名、缓存预获取等技术也是CPU用来避免停顿的方式。
GPU采用不同的方案,将大量的芯片面积用来作为处理器,也就是着色器核心。这种处理器一般来说都是以千为单位来计数。GPU一般处理的数据有高度的相似性,所以GPU可以以高度并行的方式来处理。另外,这些处理任务会尽可能的相互独立,所以不需要等待其他任务的信息,也不需要共享可写内存地址。
GPU是面向吞吐量优化的,也就是最大的数据处理速率。当然,快速处理也存在代价,那就是用于缓存和逻辑控制的芯片面积更少。也就是说,单个着色器核心的延迟会比CPU高的多。
GPU采用SIMD(single instruction, multiple data)来减小延迟产生的影响,即将指令执行逻辑与数据分离。这样可以在固定数量的着色器程序上齐步执行相同指令。相较于用单独的逻辑和分发单元来运行每个程序,SIMD的优势是可以用更少的芯片面积来处理数据和切换。
术语定义:
- 线程(thread),一个片段之行的一次像素着色器调用。每个线程含有为存储输入值的少量内存和为执行着色器的一些寄存器空间。
- 股(warp,NVIDIA)或波阵面(wavefront,AMD):使用相同着色器程序的线程绑定成的一个线程组。
股(或波阵面)运行方式如图所示:
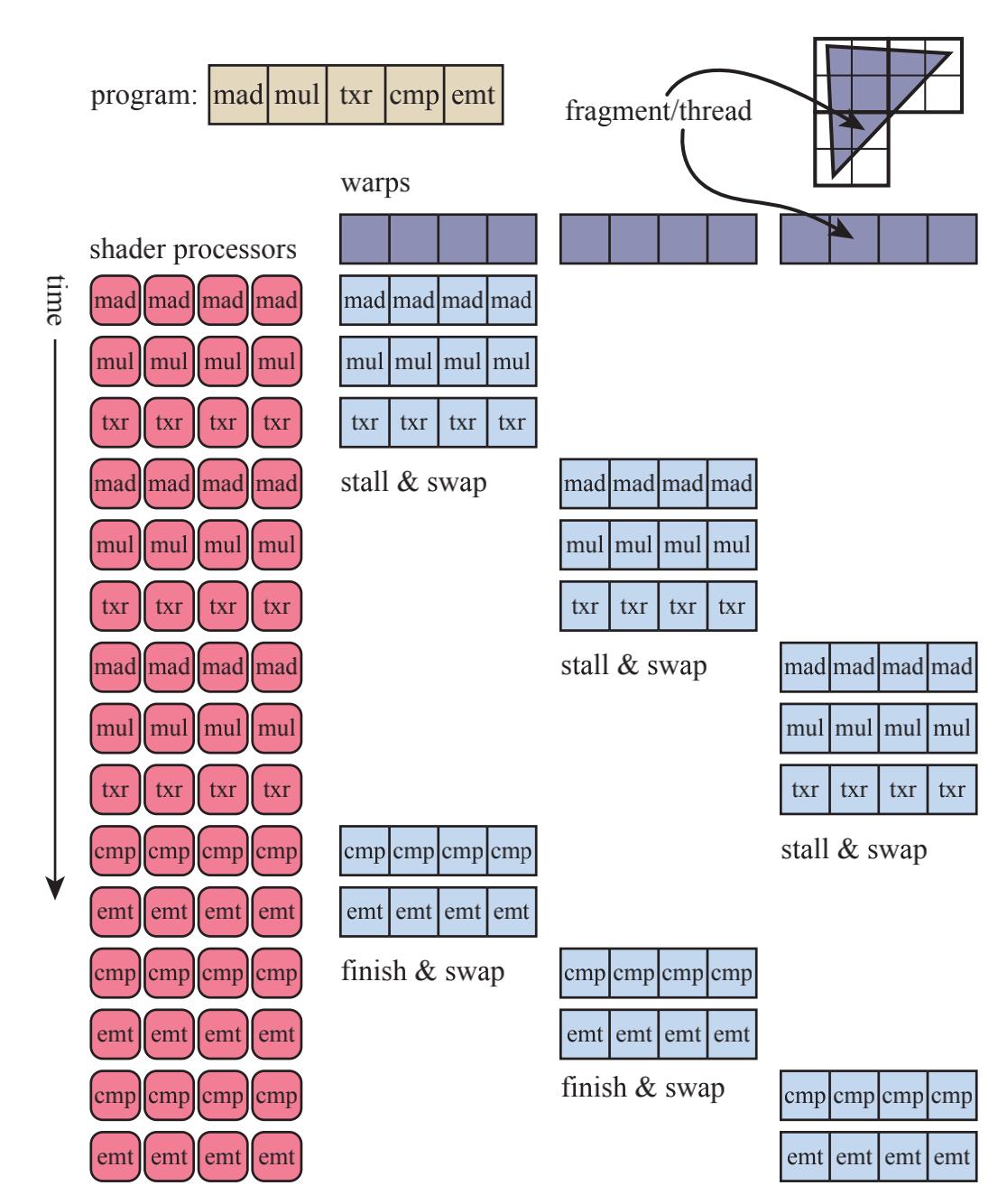
内存获取导致的延迟可以通过股交换来避免,而且股交换机制是GPU降延迟的主要机制。
着色器程序结构会影响到性能,主要有以下几个因素:
- 每个线程使用的寄存器数量。使用寄存器数量越多,那么线程数量越少,相应的股数量也越少。因此,股交换机制的降延迟能力相应的降低;
- 内存获取的频率;
- 动态分支,即“if”语句和循环。股内如果有部分的线程执行了另一条分支,那么该股所有的线程都将执行两个分支,最后根据线程自身需求抛弃掉不需要的结果。这种现象叫做线程分歧。
二、GPU管线概述
与上一章从功能角度分割整体管线的方式略有不同,本章会在在物理层面上对管线进行分割,如下图所示:

其中,绿色的为可编程步骤,黄色的为可配置步骤,蓝色的为固定功能步骤;虚线框为可选步骤。
此处描述的是GPU的逻辑模型,即暴露给我们的API;而逻辑管线的实现则是GPU的物理模型,具体实现取决于厂商。
GPU管线整体的演变方向是由固定能力向着更高的灵活性和可控性发展。
三、可编程着色器步骤
现代的着色器程序使用统一的设计。从内部来讲,是相同的指令集结构(instruction set architecture, ISA)。
基础数据类型是32位单精度浮点型标量和向量。在现代GPU中,也支持32位整型和64位浮点型。浮点型向量通常表示位置(xyzw)、颜色(rgba)或纹理坐标(uvwq)等;整型通常作为计数器、索引和位遮罩等。也支持一些例如结构体、数组、矩阵等聚合类型。
绘图指令(draw call)会触发图形API来绘制一些列图元,以此来运行图形管线和着色器。
每个可编程阶段都有两种类型的输入:统一输入(uniform inputs)和变量输入(varying inputs);其中uniform inputs会在当前draw call内保持不变;而varying inputs则是来自三角形顶点或光栅化的结果。
虚拟机会对不同类型的输入和输出分配特定的寄存器。其中分配uniform类型的常量寄存器数量,会比分配给变量输入输出的寄存器数量大的多。
着色语言支持操作符和内置函数,如 ∗ , + , arctan ( ) , log ( ) *,+,\\arctan (),\\log() ∗,+,arctan(),log()等。
流控制(flow control)指的是通过分支指令来改变代码的执行流程,分为静态和动态两种。静态控制是基于uniform输入,所以不会产生线程分歧;动态控制则是基于varying输入,能力更强但是会导致性能下降。
四、可编程着色和API的演变
略。。。
总而言之就是越来越灵活。
五、顶点着色器
顶点着色器是管线的第一个阶段。在此之前,有一些数据操作,在Direct X中叫做输入装配(input assembler)。数据会被组成若干数据流,来形成发送到管线的顶点集和图元。
三角形网由一个顶点集合表示。除了位置,一些可选属性,如颜色、纹理坐标、法线等。
顶点着色器是处理三角形网格的第一个步骤。在顶点着色器中,那些用于描述组成什么三角形的数据是无法获取的;该阶段仅仅处理顶点数据本身。顶点着色器提供了一个修改、创建或忽略顶点数值的途径。一般情况下,顶点着色器程序会将顶点从模型空间转换到齐次裁剪空间。顶点着色器至少需要输出顶点位置。
顶点着色器不能创建或销毁顶点;且每个顶点的处理都是独立的,GPU会并行的处理这些数据。
输入装配通常会表示为发生在顶点着色器运行之前的步骤,但这是逻辑模型的表示方式。物理模型中,获取用于创建顶点数据的动作可能是发生在顶点着色器中的,而且驱动会隐式的将合适的指令附在每个着色器之后。
顶点着色器能做什么:
- 顶点混合(vertex blending),用于活动关节;
- 轮廓渲染;
- 生成物体;创建一次网格,然后通过顶点着色器变形;
- 使用蒙皮(skinning)和渐变(morphing)技术来移动角色的身体和面部;
- 程序变形(procedual deformation),用于旗帜、布料或水的移动变形;
- 粒子生成;通过将退化网格传入管线,并赋予其一个面积来实现;
- 透镜失真、热浪效果、水面涟漪、纸张卷曲或者其他的效果;
- 运用高度场;
六、细分步骤
细分步骤可以渲染曲面。GPU的任务是将每个曲面描述转换成一个三角形集合。该步骤是可选步骤,并且至少需要DirectX 11、OpenGL 4.0和OpenGL ES 3.2才支持。
细分步骤有以下优点:
- 节省内存;曲面描述比三角形本身更紧凑;
- 避免总线称为瓶颈,尤其在移动角色或物体时,其发生形变的情况;
- LOD(level of details);
细分步骤通常包含三个元素:
- hull shader(DirectX)/ tesselation control shader(OpenGL);
- tessellator(DirectX)/ primitive generator(OpenGL);
- domain shader(DirectX)/ tessllation evaluation shader(OpenGL);
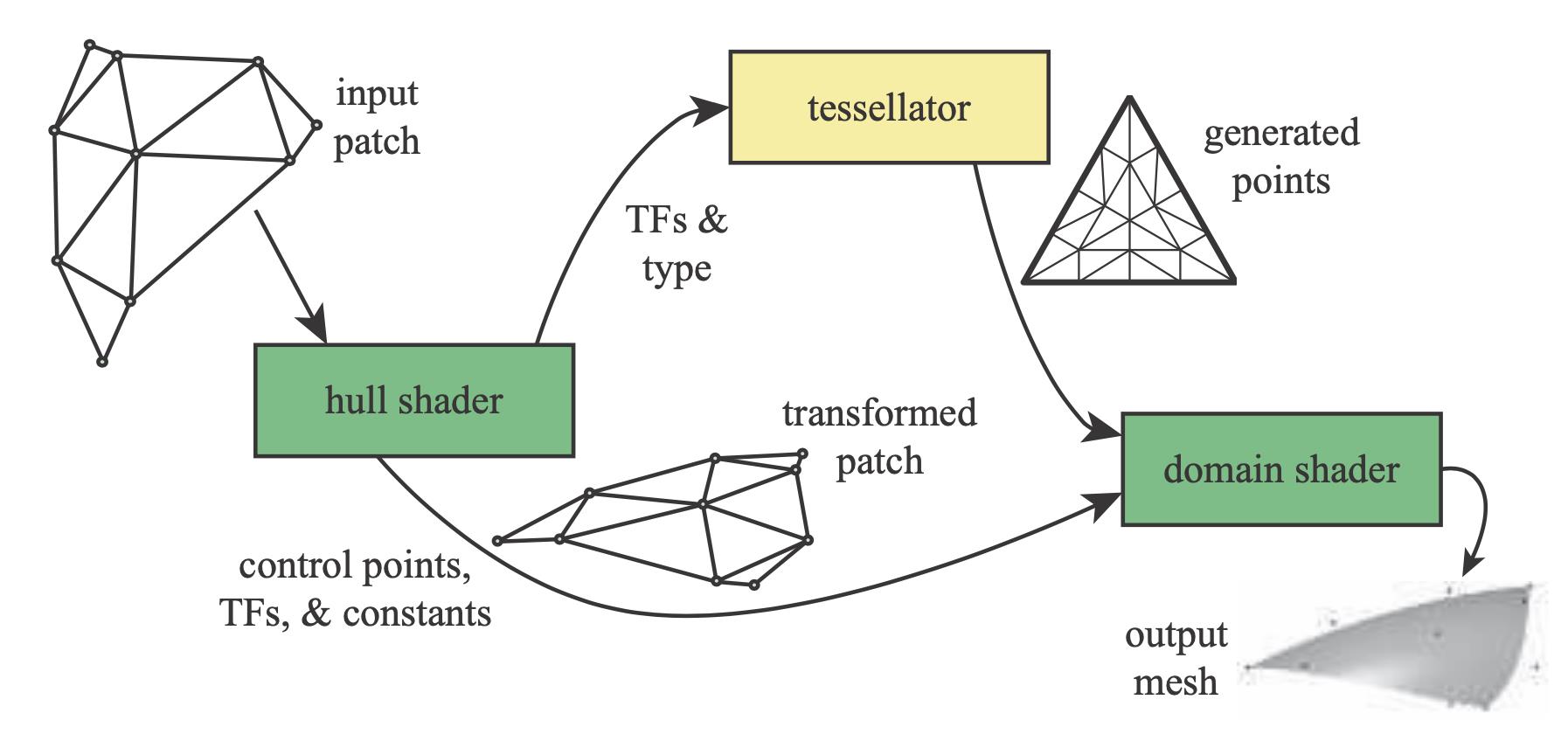
Hull shader的输入是一个补丁(patch),包含细分曲面的若干控制点。Hull shader有两个功能:1. 告诉tessellator需要产生的三角形数量以及如何配置;2. 对每个控制点进行处理。Hull shader可以修改面片描述、增加或删除控制点等。最后将一些列控制点,以及细分控制数据,输出到domain shader;同时也输出一个补丁,即一些列控制点的位置。
Tessellator是一个固定函数步骤,旨在将图元(四边形、三角形或线)分割为很多较小对象(三角形、点或线)。Hull shader会将细分表面类型信息、细分因子(tessellation factor, DirectX / tessellation level, OpenGL)传递到tesselator。
Domain shader会针对每个tessellator输出点运行一次,使用从hull shader产生的控制点数据。最后输出相应的顶点。
七、几何着色器
几何着色器可以将图元转化为其他的图元。几何着色器需要至少DirectX 10、OpenGL 3.2或OpenGL ES 3.2才能支持。
几何着色器的输入是一个物体,及其相应的顶点;这里的物体一般可以包含三角形条带、线段或者只是一个点。几何着色器会处理这些图元,最终输出0个或多个顶点;这些顶点会被当作图元来处理。
几何着色器是为了修改输入数据或做一些有限复制而设计的。输出结果中的图元顺序应该于输入的顺序相一致,这会影响到性能;因为如果多个着色器核心在并行运行,那么结果必须要存储并且排序。所以,几何着色器尽量不要在一次调用中复制或创建数量较大的几何体。
7.1 流输出
在标准的GPU管线中,数据会传入到顶点着色器处理,然后依次往后传入到光栅化阶段,并在像素着色器中处理;中途是没法获取到中间数据的。但是在Shader Model 4.0中,引入了流输出(stream output)概念。顶点着色器、细分桌阶段、几何着色器的输出结果可以穿入一个数据流,如有序数组等。在这种情况下,甚至可以完全关闭后续的光栅化阶段,使得管线完全成为一个非图像的流处理器。
输出的数据可以传回到管线开头,实现循环处理。这种操作可以用于模拟水流或粒子效果;也可以用于模型蒙皮和顶点复用。
流输出只能以浮点型数字返回数据,所以比较消耗内存;流输出针对的是图元,而不是直接针对顶点。
八、像素着色器
经过顶点着色器、细分和几何着色器后,图元会被裁剪,并且被装配后进行光栅化。光栅化器也会粗略的计算出三角形会覆盖像素多少面积。这些三角形部分或完全覆盖像素的部分,称为片段(fragment)。
三角形顶点所持有的数据,包括深度值,都会在三角形表面上进行逐像素插值。这些经过插值的数据会被穿入到像素着色器。插值的类型由像素着色器程序决定;通常采用透视正确的差值。在程序层面,顶点着色器程序输出的结果经过插值后,成为像素着色器的实际输入。
当像素着色器有了输入后,通常会计算片段的颜色;也可能会生成透明度值,或者可能修改深度值。在后续的融合阶段,会使用这些数值。模版缓存通常是不可改变的,但是同样会传递到融合阶段去。另外,在Shader Model 4中,诸如雾计算、alpha测试也从融合阶段转移到了像素着色器中。
像素着色器有一个独特的能力,那就是忽略片段,即不输出相应结果。通过这种能力,可以做到任意的裁剪方式。
起初,像素着色器只能将结果输出到融合阶段。现在有多渲染目标(multiple render targets, MRT)技术,即可以将像素着色器的结果输出到不同的缓存中。这个能力催生了一种不同的渲染管线类型:延迟着色(deferred shading),即可见性和着色分别在不同的render pass内实现。
像素着色器的限制:仅可读写当前片段的内容,无其他片段信息。不过有一些例外使得像素着色器可以获取相邻像素的信息,其中一种是通过计算梯度或者导数信息来间接获取相邻片段信息。所有的现代GPU都是通过以 2 × 2 2\\times 2 2×2为一组的方式来处理片段。实现这一方式的基础是拥有相同的核心,那么在遇到动态控制流的时候,就无法获取相邻片段的信息了。
UAV(unordered access view, Direct X 11) / SSBO(shader storage buffer object, OpenGL 4.3):共享于着色器之间的存储缓冲。
共享数据会产生数据竞争问题。解决数据竞争的方法:使用原子单元;但是会使着色器产生停顿,来等待其他着色器处理完数据。
九、融合阶段
融合阶段的作用是每个独立片段的深度、颜色与缓存合并。在这个阶段中,会用到深度缓存、模版缓存,如果这个像素可见,那么也会用到颜色缓存。对于不透明的表面,并不会真正执行混合操作(blending),只有透明物体和合成操作才会实际将片段颜色和存储的颜色进行混合。
Early-z:提前深度测试。GPU会在像素着色器之前执行一些融合测试,来裁剪掉不可见的片段;这样可以避免浪费资源。但是,如果像素着色器内有修改深度缓冲或忽略片段的操作,那么early-z则会关闭。
十、计算着色器
计算着色器独立于顶点、像素和其他的着色器,可以执行一些非图像相关的任务,通常用于GPU计算领域。在计算着色器内,股和线程相关的信息是可见的。
线程组(threads group):DirectX 11产生的概念,通常包含1到1024个线程,为了简单起见,会以 x − , y − , z − \\mathitx-, y-, z- x−,y−,z−坐标来指示。每个线程组都会有一块小内存用于线程之间共享数据。
计算着色器就是以线程组为单位运行。每个线程组内的线程都是并发运行的。
计算着色器可以用于粒子系统、网格处理(如面部动画)、裁剪、图像滤波、提升深度精度、阴影、深度场,以及其他很多任务。
以上是关于《Real-Time Rendering》第四版学习笔记——Chapter 3 The Graphics Processing Unit的主要内容,如果未能解决你的问题,请参考以下文章
《Real-Time Rendering》第四版学习笔记——Chapter 4 Transforms
《Real-Time Rendering》第四版学习笔记——Chapter 9 Physically Based Shading
《Real-Time Rendering》第四版学习笔记——Chapter 9 Physically Based Shading
《Real-Time Rendering》第四版学习笔记——Chapter 4 Transforms
《Real-Time Rendering》第四版学习笔记——Chapter 4 Transforms
《Real-Time Rendering》第四版学习笔记——Chapter 2 The Graphics Rendering Pipeline