flume使用详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flume使用详解相关的知识,希望对你有一定的参考价值。
1. Flume简介
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。
这篇文章介绍的是Flume 1.7版本,flume v1.7新增了tailDir数据源。我负责的车载OBD项目的日志服务部分就是使用taildir作为采集数据的source。
1.1 系统要求
Flume1.7运行系统要求:jdk1.7,linux
由于taildir的实现是基于jdk1.7的,所以要求jdk版本在1.7以上。
Flume也可以运行的windows上。但是在启动及管理比较繁琐。在官方的文档介绍中启动命令等都是linux基础上。另外部分flume组件的运行只有linux系统支持,比如taildir source中对文件按照inode来唯一标识,然而windows系统中文件没有inode的概念。所以本篇也是基于linux系统。
1.2 资料整理
在搜索引擎中输入flume将会得到很多资料。官方文档如下。查看官方资料对于学习新事物非常重要。
Flume介绍:http://flume.apache.org/
可以在这个网站下载flume。不过关于flume其他的原理或入门例子等,建议查看flume用户手册。
Flume用户手册:http://flume.apache.org/FlumeUserGuide.html
Flume开发者手册:http://flume.apache.org/FlumeDeveloperGuide.html
Flume github源码:https://github.com/apache/flume
1.3 flume 原理介绍
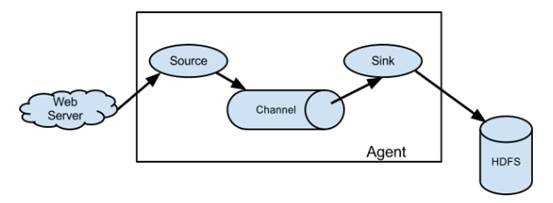
图 1 flume agent 组成结构
一个flume由三个部分组成:source,channel,sink。根据官方的介绍原文,我整理如下:
- Source:A source consumes events delivered to it by external source.
- Channel: when a source receive an event, it stores it into one or more channels.The channel is a passive store that keeps the event until it’s consumed by a flume sink
- Sink: The sink remove the event from the channel and puts it into an exteral repository like HDFS.
- The source and sink within the given agent run asynchronously with the events staged in the channel.
1.4 flume agent 示例
- 配置文件
下载好flume解压后,在conf文件夹下存放着配置文件模板,可以复制一份重命名后在此基础上进行修改。
# example.conf: A single-node Flume configuration
# 指定flume组件的名称,agent名为a1,source为r1,sink为k1,channel为c1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 配置sink,logger表示接受到的event将直接展示到console,这个类型经常在调试时使用
a1.sinks.k1.type = logger
#配置 channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 给source及sink指定channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 启动
使用flume-ng shell脚本进行启动,如下:
$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template -Dflume.root.logger=INFO,console
启动命令由4部分组成:
-n $agent_name:这里指定启动的agent 名,按照配置文件中的命名这里应该替换成a1
-c conf: 指定配置文件目录,可以是相对路径或绝对路径
-f conf/flume-conf.properties.template :指定具体配置文件名
-Dflume.root.logger=INFO,console:将flume运行日志展示到console台,这个是可选的,但是一般都需要加上,便于查看flume运行情况。
- 运行结果
在另外一个终端,使用telnet命令发送Hello world!
因为根据配置文件我们指定了netcat类型的source是监听在本机的44444端口上。
$ telnet localhost 44444
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is ‘^]‘.
Hello world! <ENTER>
OK
将在flume运行的控制台查看到sink已经将接受到的event打印到控制台。
12/06/19 15:32:19 INFO source.NetcatSource: Source starting
12/06/19 15:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
12/06/19 15:32:34 INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. }
至此,一个完整的flume运行过程完成。
2. Flume Source
Flume不仅提供了丰富的source类型,可以直接使用,目前已经覆盖了很多应用场景。同时也支持自定义source。
在这里简单介绍下exec,spooldir,taildir三种source。其他类型及具体详情请查看官方文档Flume Source章节。
2.1 Exec
使用exec作为数据源,需要指定执行的shell命令。经常使用到的命令tail -F [file],来读取新增到日志文件的内容。
缺点:数据可能丢失,官方推荐spooldir作为数据源。
2.2 Spooldir
Spooldir将从指定的文件夹中读取文件,并且是按行读取文件中的内容。如果指定的文件夹中出现新文件,也将会被识别并读取。Spooldir将读取完的文件进行重命名(默认添加.COMPLETE)或永久删除。
优点:Spooldir不会出现丢失数据的情况,即使flume重启或停止。
缺点:1. 放置在spooldir目录中的文件不允许进行修改,否则flume会报错并停止工作
2. 在spooldir目录中的文件名不可重复使用,否则flume会报错并停止工作
2.3 Taildir
Taildir可以说是exec和spooldir两种source的优点集合。在车载OBD的日志服务功能就是使用此作为数据源。
注意:taildir目前不支持windows系统。
查看源码可以看到在ReliableTaildirEventReader.java实现代码中获取文件的inode,其中“unix”表明仅在linux系统生效:
Taildir数据源将会监控指定目录下所有文件,实时获取新附加到各个文件末尾的内容。它将定时保存各个文件最后读取位置记录到一个json格式的文件。Flume重新启动后将按照此json文件保存的位置开始读取。
如果需要监控多个文件源,并且对各个不同读取到的数据文件进行区别处理,可以使用提供的headerkey。
配置文件举例:
# Describe/configure source1
agent1.sources.s1.type = TAILDIR
agent1.sources.s1.positionFile = ./bin/taildir_position.json
agent1.sources.s1.filegroups = f1 f2
agent1.sources.s1.filegroups.f1 = /home/neoway/apache-flume-1.7.0-bin/log1/.*
agent1.sources.s1.headers.f1.componentName = mqtt
agent1.sources.s1.filegroups.f2 = /home/neoway/apache-flume-1.7.0-bin/log2/.*
agent1.sources.s1.headers.f2.componentName = mybatis
agent1.sources.s1.fileHeader = true
#agent1.sources.s1.channels = c1
agent1.sources.s1.channels = c1
读取到event:
2017-08-24 09:48:06:INFO SinkRunner-PollingRunner-DefaultSinkProcessor org.apache.flume.sink.LoggerSink - Event: { headers:{ componentName = mqtt, file=/home/neoway/apache-flume-1.7.0-bin/log/mylineDeserializer.log} body: 32 30 31 37 2D 30 38 2D 32 33 54 31 34 3A 33 30 2017-08-23T14:30 }
2017-08-24 09:48:06:INFO SinkRunner-PollingRunner-DefaultSinkProcessor org.apache.flume.sink.LoggerSink - Event: { headers:{ componentName = mqtt, file=/home/neoway/apache-flume-1.7.0-bin/log/mylineDeserializer.log} body: 32 30 31 37 2D 30 38 2D 32 33 54 31 34 3A 33 30 2017-08-23T14:30 }
可以看到在读取到的event中与header部分,在sink部分处理时,可以获取envent的header,从而判断出属于哪个文件源并依此做对应处理。
3. Flume Sink
Flume提供了很多类型的sink,详情可参考flume用户手册的flume sink章节。
在车载的日志服务的需求是将读取到的内容保存到mysql数据库中。这里需要使用自定义sink。我参考了这篇文章:http://blog.csdn.net/poisions/article/details/51695372
- 自定义mysqlSink类,继承 AbstractSink 并实现 Configurable 。重写start()方法,stop()方法,process()方法
- 将编译好的jar包及连接mysql的驱动jar包存放到flume的lib目录下
- 在配置文件中配置sink,为自定义mysqlsink的包路径。
agent1.sinks.k1.type = org.flume.mysql.sink.MysqlSink
agent1.sinks.k1.hostname = 192.168.10.136
agent1.sinks.k1.port=3306
agent1.sinks.k1.databaseName=carcloud
agent1.sinks.k1.recordTableName=log_record
agent1.sinks.k1.configTableName=log_config
agent1.sinks.k1.projectName= carcloud
#the string that joint all componentNames by ‘,‘ and each componentName come from filegroups‘s fileHeader;
agent1.sinks.k1.componentNames = mqtt,mybatis
agent1.sinks.k1.user=root
agent1.sinks.k1.password=ayl123$
agent1.sinks.k1.channel = c1
4. Flume探索路上遇到的问题
4.1 在windows系统运行flume
在除接触flume时,一直在windows上尝试启动flume,碰到很多问题。慢慢查多资料发现flume设计的命令都是linux的,从而转战到linux系统。这也是对linux系统不熟悉造成的坑。
4.2 安装路径有空格
在linux安装路径上的目录有空格,也会出现问题。在文件及文件夹命名时使用空格是个坏习惯,可以使用‘-’代替空格。
4.3 Taildir重复读取
在taildir测试的时候,遇到了往taildir监控的文件中追加内容时,总是会从头读取文件的内容,而不是仅读取新添加的这一行内容。
测试环境是这样的:
- 使用 sed命令往目标文件追加内容
- 查询数据库,数据库表中增加了目标文件所有行内容,而非仅仅是上一步sed的行内容。
一度怀疑taildir是否能读取追加的内容。并且检查了所有的配置,均无效。
查询资料也完全没有提到过使用taildir会重复读取的问题。
最后将源码拷贝下来,自定义为myTaildirSource。并且在运行的关键部分打印日志,顺便了解下tailDir的运行过程。
根据日志发现每次往目标文件中sed内容后,taildir显示目标文件的inode发送了变化,从而被识别为新文件,难怪会从头读取。
接下来查阅资料关于linux系统的inode机制,什么情况下会导致inode发送变化。根据查阅的资料inode仅在重命名后,或者删除后再次新建一个同名的文件时 inode发送变化。
最后无意去查看了车载项目产生的日志文件的inode,在往日志文件中追加内容时inode不会发送变化。至此问题解决。
附件:使用ls –i 可查看文件的inode
4.4 Flume后台启动
前面介绍的启动命令是在前台直接运行的,这时不能关闭这个界面,否则flume也被停止。
在后台启动flume命令:
#!/bin/sh
nohup ../bin/flume-ng agent --conf ../conf --conf-file ../conf/x1_dir_to_db_flume.conf --name a1 -Dflume.root.logger=INFO,console > x1nohup.out 2>&1 &
在原来的启动命令上增加> x1nohup.out 2>&1 &即可实现后台启动。并且flume的运行日志都将打印到x1nohup.out文件中。
以上是关于flume使用详解的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop详解——Hive的原理和安装配置和UDF,flume的安装和配置以及简单使用,flume+hive+Hadoop进行日志处理
Hadoop详解——Hive的原理和安装配置和UDF,flume的安装和配置以及简单使用,flume+hive+Hadoop进行日志处理