Hadoop详解——Hive的原理和安装配置和UDF,flume的安装和配置以及简单使用,flume+hive+Hadoop进行日志处理
Posted LIUXUN1993728
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop详解——Hive的原理和安装配置和UDF,flume的安装和配置以及简单使用,flume+hive+Hadoop进行日志处理相关的知识,希望对你有一定的参考价值。
hive简介
什么是hive?
① hive是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,可以用来进行数据提取转换加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive定义了简单的类似于SQL的查询语言称为QL,它允许熟悉SQL的用户查询数据。同时这种语言也允许熟悉MapReduce的开发者进行开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的负载的分析工作。 ② Hive是SQL的解析引擎,它将SQL语句转成M/R job 然后在Hadoop执行。 ③ Hive的表其实就是HDFS目录/文件,按照表名将将文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R job里使用这些数据。 数据仓库和数据库的区别:数据仓库主要用来保存数据,对保存的数据进行分析计算。一次写入,多次读取。不能删除单条数据,除非将整个文件删除。修改数据时只有将整个文件下载下来,修改之后重写上传。Hive的主要功能可以将一条语句转换为MapReduce,Hive依赖于HDFS和Yarn
注意:HBASE数据库适用于结构简单,表与表之间没有密切联系的业务需求。关系型数据库适用于业务复杂表与表之间联系密切的业务。Hive是数据仓库,是用来进行数据挖掘的。
Hive的系统架构?
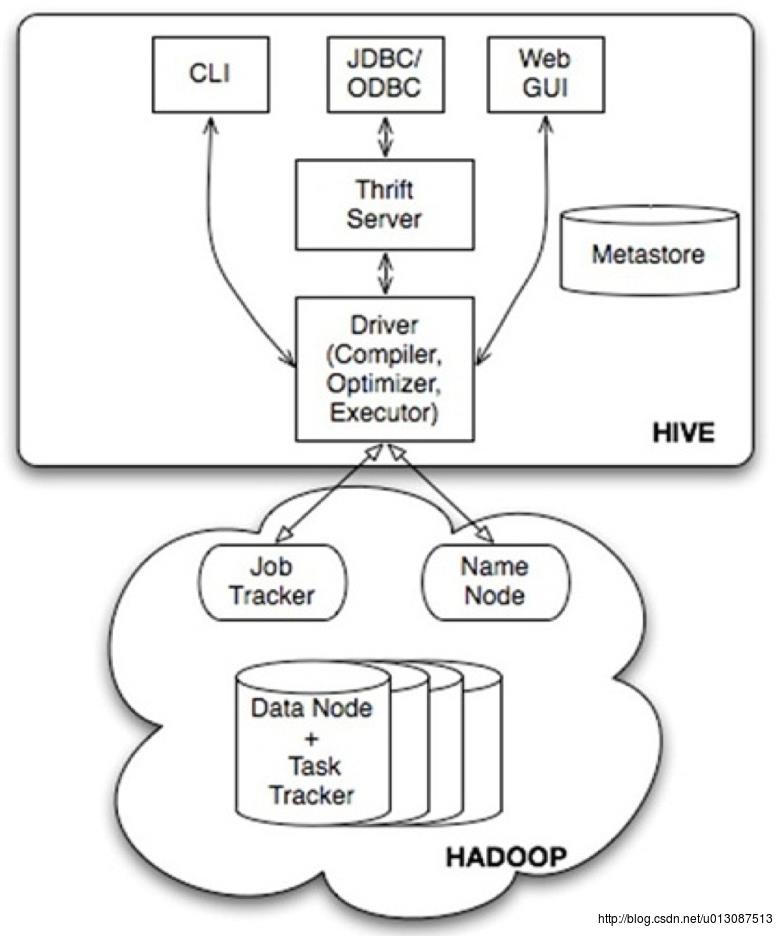
用户接口,包括 CLI,JDBC/ODBC,WebUI
元数据存储,通常是存储在关系数据库如 mysql, derby 中
解释器、编译器、优化器、执行器
Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算
MetaStore:元数据库,保存着表、分区等的描述信息,通常在开发时使用MySQL作为它的元数据库。
如果不指定元数据库,hive默认会使用自带的derby数据库来保存元数据信息,使用默认的derby数据库有很大的局限性,它只支持单连接。所谓的单连接是指在哪个目录下启动hive命令就会在哪个目录下创建Metastore数据库(metastore_db)并使用,不允许在同一目录下同时启动多个hive命令,如果要支持多连接,除非切换不同的目录来执行hive命令,又会重新创建一个新的metastore_db来保存元数据,不能共享多个连接之间的元数据。因此要使用MySQL来作为它的元数据库。
使用CLI命令行的方式最多(可以编写自动化脚本进行执行),JDBC/ODBC的问题非常多 比如连接池,高并发等方面都有问题。
Compiler
•Driver调用编译器(compiler)处理HiveQL字串,这些字串可能是一条DDL、DML或查询语句
•编译器将字符串转化为策略(plan)
•策略仅由元数据操作和HDFS操作组成,元数据操作只包含DDL语句,HDFS操作只包含LOAD语句
•对插入和查询而言,策略由map-reduce任务中的具有方向的非循环图(directedacyclic graph,DAG)组成
Hive与传统数据库比较

Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\\t”、”\\x001″)、行分隔符 (”\\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
Hive的数据类型
(1) 基本数据类型tinyint/smallint/int/bigint
float/double
boolean
string
(2) 复杂数据类型
Array/Map/Struct
没有date/datetime
Hive的数据存储
Hive的数据存储基于Hadoop HDFSHive没有专门的数据存储格式
存储结构主要包括:数据库、文件、表、视图
Hive默认可以直接加载文本文件(TextFile),还支持sequence file 、RC file
创建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据
Hive的数据模型
Hive的数据模型-数据库
类似传统数据库的DataBase默认数据库"default"
使用#hive命令后,不使用hive>use <数据库名>,系统默认的数据库。可以显式使用hive> use default;
创建一个新库
hive > create database test_dw;
Hive的数据模型-表
① Table 内部表② Partition 分区表
③ External Table 外部表
④ Bucket Table 桶表
Hive的数据模型-内部表
① 与数据库中的 Table 在概念上是类似② 每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 test,它在 HDFS 中的路径为:/ warehouse/test。 warehouse是在 hive-site.xml 中由 $hive.metastore.warehouse.dir 指定的数据仓库的目录
③ 所有的 Table 数据(不包括 External Table)都保存在这个目录中。
④ 删除表时,元数据与数据都会被删除
⑤ 创建数据文件inner_table.dat
⑥ 创建表
hive>create table inner_table (key string);
⑦ 加载数据
hive>load data local inpath '/root/inner_table.dat' into table inner_table;
⑧ 查看数据
select * from inner_table
select count(*) from inner_table
⑨ 删除表 drop table inner_table (删除表时可能报错max key length is 1000 bytes
把mysql的MetaStore数据库字符类型改为latin1)
Hive的数据模型-分区表
① Partition 对应于数据库的 Partition 列的密集索引② 在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中
例如:test表中包含 date 和 city 两个 Partition,
则对应于date=20130201, city = bj 的 HDFS 子目录为:
/warehouse/test/date=20130201/city=bj
对应于date=20130202, city=sh 的HDFS 子目录为;
/warehouse/test/date=20130202/city=sh
CREATE TABLE tmp_table #表名
(
title string, # 字段名称 字段类型
minimum_bid double,
quantity bigint,
have_invoice bigint
)COMMENT '注释:XXX' #表注释
PARTITIONED BY(pt STRING) #分区表字段(如果文件非常之大的话,采用分区表可以快过滤出按分区字段划分的数据)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\001' # 字段是用什么分割开的
STORED AS SEQUENCEFILE; #用哪种方式存储数据,SEQUENCEFILE是hadoop自带的文件压缩格式
一些相关命令
SHOW TABLES; # 查看所有的表
SHOW TABLES '*TMP*'; #支持模糊查询
SHOW PARTITIONS TMP_TABLE; #查看表有哪些分区
DESCRIBE TMP_TABLE; #查看表结构
③ 创建数据文件partition_table.dat
④ 创建表
create table partition_table(rectime string,msisdn string) partitioned by(daytime string,city string) row format delimited fields terminated by '\\t' stored as TEXTFILE;
⑤ 加载数据到分区
load data local inpath '/home/partition_table.dat' into table partition_table partition (daytime='2013-02-01',city='bj');
⑥ 查看数据
select * from partition_table
select count(*) from partition_table
⑦ 删除表 drop table partition_table
⑧ alter table partition_table add partition (daytime='2013-02-04',city='bj');
通过load data 加载数据
⑨ alter table partition_table drop partition (daytime='2013-02-04',city='bj')
元数据,数据文件删除,但目录daytime=2013-02-04还在
Hive的数据模型-外部表
① 指向已经在 HDFS中已经存在的数据,可以创建 Partition② 它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异
③ 内部表的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除
④ 外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个 外部表 时,仅删除该链接
⑤创建示例
CREATE EXTERNAL TABLE page_view
( viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination‘
)
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '44' LINES TERMINATED BY '12'
STORED AS TEXTFILE
LOCATION 'hdfs://centos:9000/user/data/staging/page_view';
⑥ 创建数据文件external_table.dat
⑦ 创建表
hive>create external table external_table1 (key string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t' location '/home/external';
在HDFS创建目录/home/external
#hadoop fs -put /home/external_table.dat /home/external
⑧ 加载数据
LOAD DATA INPATH '/home/external_table1.dat' INTO TABLE external_table1;
⑨ 查看数据
select * from external_table
select count(*) from external_table
⑩ 删除表
drop table external_table
hive操作
视图操作
① 视图的创建CREATE VIEW v1 AS select * from t1;
表的操作
① 表的修改alter table target_tab add columns (cols,string)
② 表的删除
drop table
导入数据
① 当数据被加载至表中时,不会对数据进行任何转换。Load 操作只是将数据复制/移动至 Hive 表对应的位置。LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
② 把一个Hive表导入到另一个已建Hive表
INSERT OVERWRITE TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement FROM from_statement
③ CTAS 新创建一个表保存查询结果
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
(col_name data_type, ...) …
AS SELECT …
例:create table new_external_test as select * from external_table1;
查询
① selectSELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] | [ORDER BY col_list] ]
[LIMIT number]
② 基于Partition的查询
一般 SELECT 查询是全表扫描。但如果是分区表,查询就可以利用分区剪枝(input pruning)的特性,类似“分区索引“”,只扫描一个表中它关心的那一部分。Hive 当前的实现是,只有分区断言(Partitioned by)出现在离 FROM 子句最近的那个WHERE 子句中,才会启用分区剪枝。例如,如果 page_views 表(按天分区)使用 date 列分区,以下语句只会读取分区为‘2008-03-01’的数据。
SELECT page_views.* FROM page_views WHERE page_views.date >= '2013-03-01' AND page_views.date <= '2013-03-01'
③ LIMIT Clause
Limit 可以限制查询的记录数。查询的结果是随机选择的。下面的查询语句从 t1 表中随机查询5条记录:
SELECT * FROM t1 LIMIT 5
④ Top N查询
下面的查询语句查询销售记录最大的 5 个销售代表。
SET mapred.reduce.tasks = 1SELECT * FROM sales SORT BY amount DESC LIMIT 5
表连接
① 导入ac信息表hive> create table acinfo (name string,acip string) row format delimited fields terminated by '\\t' stored as TEXTFILE;
hive> load data local inpath '/home/acinfo/ac.dat' into table acinfo;
② 内连接
select b.name,a.* from dim_ac a join acinfo b on (a.ac=b.acip) limit 10;
③ 左外连接
select b.name,a.* from dim_ac a left outer join acinfo b on a.ac=b.acip limit 10;
Hive中的UDF
1、UDF函数可以直接应用于select语句,对查询结构做格式化处理后,再输出内容。2、编写UDF函数的时候需要注意一下几点:
a)自定义UDF需要继承org.apache.hadoop.hive.ql.UDF。
b)需要实现evaluate函数,evaluate函数支持重载。
3、步骤
a)把程序打包放到目标机器上去;
b)进入hive客户端,添加jar包:hive>add jar /run/jar/udf_test.jar;
c)创建临时函数:hive>CREATE TEMPORARY FUNCTION add_example AS 'hive.udf.Add';
d)查询HQL语句:
SELECT add_example(8, 9) FROM scores;
SELECT add_example(scores.math, scores.art) FROM scores;
SELECT add_example(6, 7, 8, 6.8) FROM scores;
e)销毁临时函数:hive> DROP TEMPORARY FUNCTION add_example;
注:UDF只能实现一进一出的操作,如果需要实现多进一出,则需要实现UDAF
Hive的操作流程

选择hive的原因? ① 基于Hadoop的大数据的计算/扩展能力 ② 支持SQL like查询语言 ③ 编程简单
Hive的安装和配置
① 步骤一:安装前准备前提准备:首先启动Hadoop集群(启动顺序:ZooKeeper集群—>启动HDFS—>启动Yarn)
下载Hive安装包:http://archive.apache.org/dist/hive/hive-0.13.0/
Hive安装在任意一台机器上都可以,我的安装在hadoop3上
上传Hive安装包,并解压到指定位置
tar -zxvf apache-hive-0.13.0-bin.tar.gz -C /cloud/
修改所属的用户和组均为root
chown -R root:root /cloud/apache-hive-0.13.0-bin/
② 步骤二:安装MySQL数据库
在hadoop5机器上安装MySQL数据库(之所以不在hadoop3上安装mysql数据库,是为了测试MySQL的远程访问)
下载地址:https://dev.mysql.com/downloads/mysql/ 分别下载Server和Client
上传到hadoop5上
rpm -ivh mysql-community-server-5.7.19-1.el7.x86_64.rpm --force --nodeps
……
参数说明:i-install 安装 v-显示详情 h-显示进度条
以上安装方式比较麻烦且容易出现问题 可以使用以下安装方式
yum –y install mysql-server
启动mysqld服务:service mysqld start
启动MySQL服务器,设置管理员root的密码:mysqladmin –u root password ‘root’
客户端登录:mysql –u root –p ‘root’
配置登录用户的密码:
Show databases;
Use mysql;
select host,user,password form user;
delete from user where password = “”;
配置允许第三方机器访问本机Mysql:
update user set host = ‘%’;
必须刷新权限:
flush privileges;
测试两台主机间的数据库访问:
Mysql –u root –p –h otherIp;
如果还是不能访问,必须关闭防火墙:
service iptables stop;
chkconfig iptables off; //开机关闭防火墙
注意:还有一种为MySQL远程连接授权的方法
『如果出现没有权限的问题,在mysql授权(在安装mysql的机器上执行)
mysql -uroot -p
#(执行下面的语句 *.*:所有库下的所有表 %:任何IP地址或主机都可以连接)
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY ‘root’ WITH GRANT OPTION;
FLUSH PRIVILEGES; 』
③ 修改hive的配置文件
进入hadoop3中hive的安装目录的配置文件目录
cd /cloud/apache-hive-0.13.0-bin/conf
将hive-default.xml.template 重命名为hive-site.xml
修改内容 vim hive-site.xml 修改配置内容后如下如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<!— 配置hive连接哪台机器上的哪个数据库作为元数据库 —>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop5:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>首先在hadoop3上进入到hive的lib下
cd /cloud/apache-hive-0.13.0-bin/lib/
cp /root/Desktop/mysql-connector-5.1.8.jar ./
⑤ 为hive配置环境变量
vim /etc/profile
修改内容如下:
export JAVA_HOME=/usr/java/jdk1.8.0_144 #必须配
export HADOOP_HOME=/cloud/hadoop-2.7.4 #必须配
export SQOOP_HOME=/cloud/sqoop-1.4.4
export HIVE_HOME=/cloud/apache-hive-0.13.0-bin
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SQOOP_HOME/bin:$HIVE_HOME/bin
保存退出
使其生效 source /etc/profile
⑥ 输入命令 hive 即可进入hive的命令界面进行操作
hive> create table people (id int,name string);
使用Navicat客户端连接hadoop5上的MySQL 刷新发现多了一个hive数据库
查看TBLS表 里面存放的是表的元数据信息

MANAGED_TABLE 类型表示内部表
查看COLUMNS_V2表 里面存放的是表中列的元数据信息


查看SDS表,里面存放的是表在HDFS上存放位置信息


hive建表的默认目录:user/hive/warehour/
查看DBS表,里面存放的是所有数据库的位置信息


Hive HQL的使用
hive的HQL语法show databases; 查看有哪些数据库
use <数据库名>; 使用哪个数据库作为当前的数据库
show create table <表名>; 查看某个表的描述信息,例如存放位置,字段等信息。
load data local inpath ‘<LocalPathName>’ into table <tableName>; 将本地系统文件中数据加载到指定表中。
创建内部表
create table <表名>(<fieldName1> <fieldType1>,[<fieldName2> <fieldType2>,…]) row format delimited fields terminated by ‘<分割符>’;
创建外部表
create external table <表名>(<fieldName1> <fieldType1>,[<fieldName2> <fieldType2>,…]) row format delimited fields terminated by ‘<分割符>’ location ‘HDFS_ADDR’;
注意:在Linux命令端也可以调用hive的命令 hive -e “<hive命令>”,例如:hive -e “show tables”,一般在编写shell脚本时使用。
① 创建表(默认是内部表)
[在桌面创建stuInfo.txt 内容如下:
[root@hadoop3 Desktop]# cat stuInfo.txt
1 张三
2 李四
3 王五
4 赵六
]
hive> show databases;
hive> create database test1;
hive> use test1;
hive> create table student(id bigint,name string) row format delimited fields terminated by '\\t'; #创建表student
hive> load data local inpath '/root/Desktop/stuInfo.txt' into table student; #加载本地文件到student表
hive> select * from student; #查询student表的数据 不会转化成MapReduce
hive> select * from student limit 2; # 查询前两条信息,也不会转化为MapReduce
hive> select sum(id) from student; # 计算id的总和,会转为MapReduce
②创建外部表
内部表和外部表的区别:内部表是首先创建好表,指定在HDFS上的地址,然后往里面load数据,先有表后有数据。外部表是先准备好数据,然后创建表指向它,先有数据后有表。外部表的作用:公司有很多历史数据已经在HDFS上存在,现在想用hive去分析它,如果使用第一种方式新建内部表,然后将数据重新load进去非常麻烦,这时可以使用建一个外部表指向原先的数据。
在hive命令窗口下也可以使用Hadoop的命令,但是格式有所改变,要使用dfs <命令> 的格式例如”dfs -ls / ;“
hive> dfs -ls /
hive> dfs -mkdir /data;
hive> dfs -put /root/Desktop/stuInfo.txt /data/a.txt;
hive> dfs -put /root/Desktop/stuInfo.txt /data/b.txt;
hive> create external table ext_student(id int,name string) row format delimited fields terminated by '\\t' location '/data';
hive> select * from ext_student;
hive> show create table ext_student;
以后再向HDFS的/data目录下上传文件 在hive中查询ext_student 就可以查询出来了。
注意:无论数内部表还是外部表,只要向表指向的目录下存放数据,都可以在表中查询出来。
测试验证:
hive> show create table student; #查询student表在HDFS上的位置信息
hive> dfs -put /root/Desktop/stuAdd.avi /user/hive/warehouse/test1.db/student; #将新的数据文件上传到student表的目录
hive> select * from student;
发现查询出了stuAdd.avi中的数据信息
③创建分区表
相当于MapReduce中的Partition,可以将数据按照年月日进行分区,按照省市进行分区。分区可以提高查询效率,在数据量非常大的时候一定要优先考虑分区。
在本地系统创建三个数据文件 内容如下
[root@hadoop3 Desktop]# cat b.a
7 艾玛 34
6 艾米丽 35
[root@hadoop3 Desktop]# cat b.c
1 刘亦菲 25
2 景甜 28
3 范冰冰 35
[root@hadoop3 Desktop]# cat b.j
4 武藤兰 36
5 井控 34
[root@hadoop3 Desktop]#
hive> create external table beauties (id bigint,name string,size double) partitioned by (nation string) row format delimited fields terminated by '\\t' location '/beauty'; # 指定的位置不存在就会在HDFS自动创建对应目录
hive> dfs -put /root/Desktop/b.c /beauty;
hive> dfs -put /root/Desktop/b.j /beauty;
hive> dfs -put /root/Desktop/b.a /beauty;
hive> dfs -ls /beauty;
hive> select * from beauties; # 发现从分区表中没有查询到数据
正确的做法如下所示:
(其实分区表并不是直接从全表的根目录下进行查询的,而是从对应的分区(子目录)中进行查找的)
hive> load data local inpath '/root/Desktop/b.c' into table beauties partition (nation='China');
hive> load data local inpath '/root/Desktop/b.j' into table beauties partition (nation='Japan');
hive> select * from beauties;
hive> select * from beauties where nation='China';
hive> select * from beauties where nation='Japan';
分区表是在表的根目录下创建”分区字段=分区值”的子文件夹,然后将数据导入到子文件夹内,并将其目录信息写入到Metastore中,如果仅仅创建对应的子文件夹,但是不将其目录等信息写入Metastore中,在查询时是搜索不到的;
hive> dfs -mkdir /beauty/nation=America;
hive> dfs -put /root/Desktop/b.a /beauty/nation=America;
hive> select * from beauties; (手动加目录上传文件,是搜索不到数据的,因为没有将目录信息写入到Metastore)
只有通知hive在Metadata中添加对应的信息才行
hive> alter table beauties add partition (nation='America') location '/beauty/nation=America';
如果数据量很大,可以建立多重子分区,如年分区内可以建立月分区。

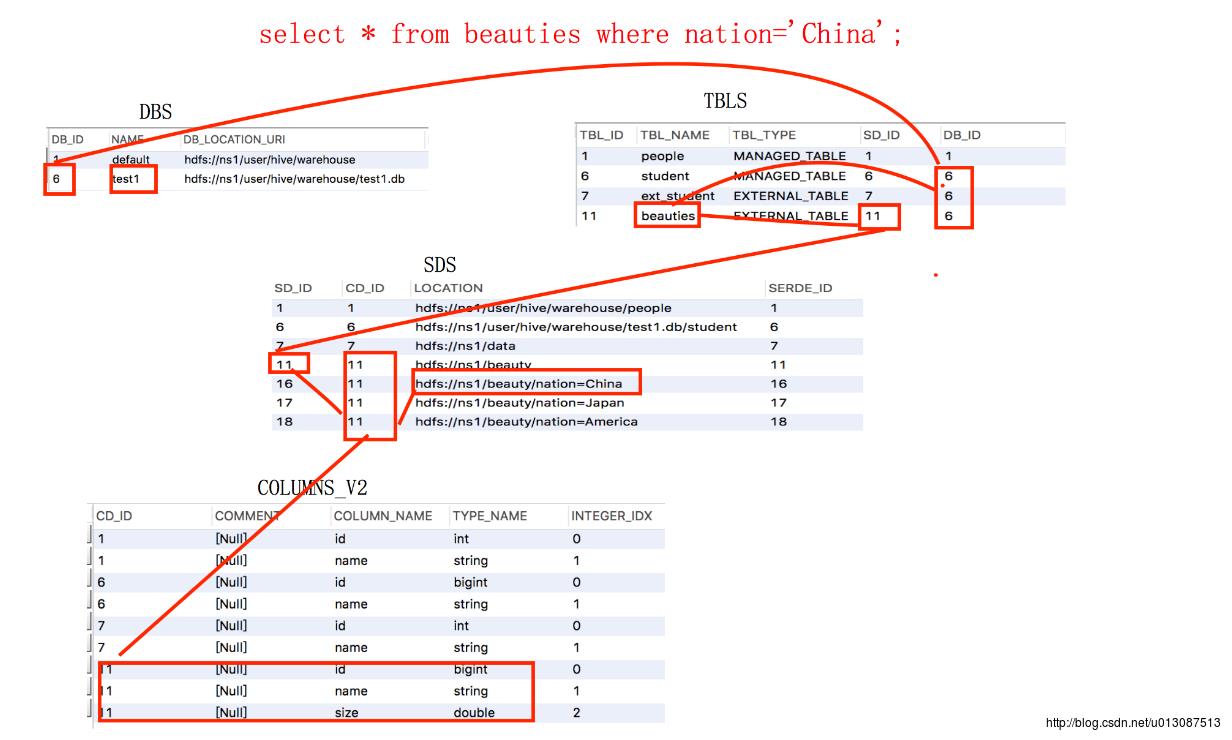
根据当前使用的数据库名称在DBS表中查询到对应主键DB_ID,根据DB_ID和SQL中的表名在TBLS中查询出对应的SD_ID,根据SD_ID和分区条件在SDS中查询出对应的记录,记录中的Location字段是分区数据在HDFS上的访问地址,根据记录中的CD_ID可以关联COLUMNS_V2中对应的字段信息。从MetaStore中最终得到检索内容的HDFS地址和要返回的字段类型.....
Hive UDF的使用
hive的UDF就是自定义函数,是在工作中使用最多的(注意:函数和存储过程的区别在于存储过程没有返回值而函数都有返回值)
下载地址:Apache官方网站下载hive-udf
开发工具:Eclipse
编写UDF程序
package hadoop.hive.udf;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class NationUDF extends UDF
public static Map<String, String> nationMap = new HashMap<String, String>();
static
nationMap.put("China", "中国");
nationMap.put("Japan", "日本");
nationMap.put("America", "美国");
Text t = new Text();
// 10000 sum(income)
// 中国 getNation(nation)
public Text evaluate(Text nation)
String nation_e = nation.toString();
String name = nationMap.get(nation_e);
if (name == null)
name = "火星人";
t.set(name);
return t;
注意:evaluate中可以添加任意个参数(必须是Hadoop可序列化的)
自定义函数的调用过程
① 添加jar包(在hive命令行里面执行)
hive> add jar /root/Desktop/nation.jar;
② 创建临时函数
hive> create temporary function getNation as 'hadoop.hive.udf.NationUDF';
③ 调用
hive> select id, name,size, getNation(nation) from beauties order by size;
④ 可以将查询结果保存到HDFS中
hive> create table res_beauty row format delimited fields terminated by '\\t' as select id,name,size, getNation(nation) from beauties order by size;
Hive+sqoop结合处理统计业务
原理:先使用sqoop将关系型数据库中的数据导入到HDFS中的临时文件里面,然后再将临时文件中的数据导入到hive表里。如下所示:在我的Mac端的MySQL上的hadoop数据库上有如下信息
trade_detail表

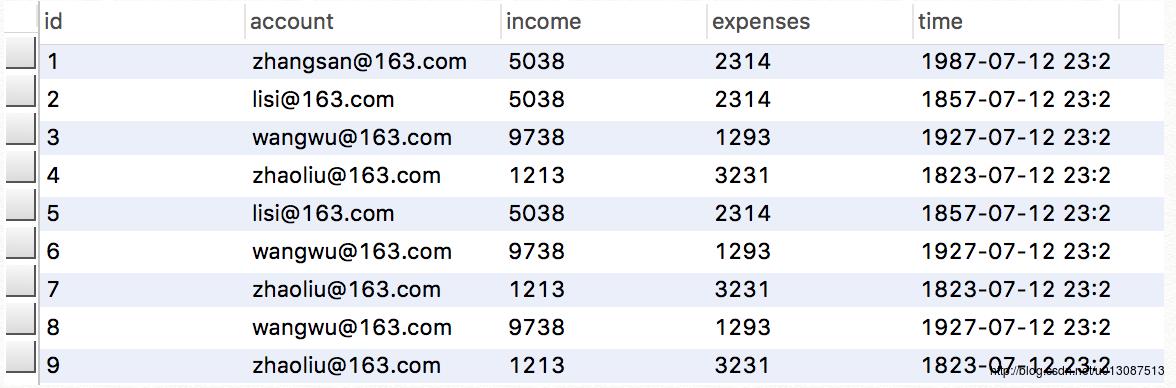
user_info表


SQL语言统计每个用户的总收入,总支出和总的结余:
select t.account,u.name,t.income,t.expenses,t.surplus from user_info u join (select account,sum(income) as income,sum(expenses) as expenses,sum(income-expenses) as surplus from trade_detail group by account) t on t.account=u.account;
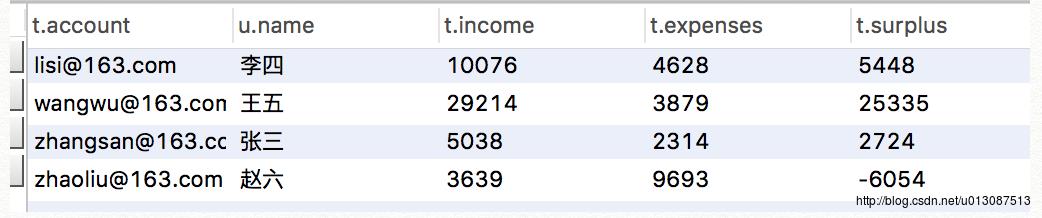
以上SQL语句在数据量不很大时速度很快,如果数据量很大会变得非常慢, 就不能使用SQL语句来进行计算统计了。
解决方案:使用hive在系统上创建与基本表对应的表(字段一一对应),使用sqoop将表的数据分别load到hive所建的表中,
然后就可以使用hive的HQL语句进行统计了。
(1) 在hive中创建两张表
hive> create table trade_detail (id bigint, account string, income double,expenses double,time string) row format delimited fields terminated by '\\t';
hive> create table user_info (id bigint,account string,name string,age int) row format delimited fields terminated by '\\t';
(2) 将mysq当中的数据直接导入到hive当中
sqoop import --connect jdbc:mysql://192.168.0.103:3306/hadoop --username root --password root --table trade_detail --hive-import --hive-overwrite --hive-database test1 --hive-table trade_detail --fields-terminated-by '\\t';
sqoop import --connect jdbc:mysql://192.168.0.103:3306/hadoop --username root --password root --table user_info --hive-import --hive-overwrite --hive-database test1 --hive-table user_info --fields-terminated-by '\\t';
(3) 创建一个结果表保存SQL语句的执行结果
create table result row format delimited fields terminated by '\\t' as select t2.account, t2.name, t1.income, t1.expenses, t1.surplus from user_info t2 join (select account, sum(income) as income, sum(expenses) as expenses, sum(income-expenses) as surplus from trade_detail group by account) t1 on (t1.account = t2.account);
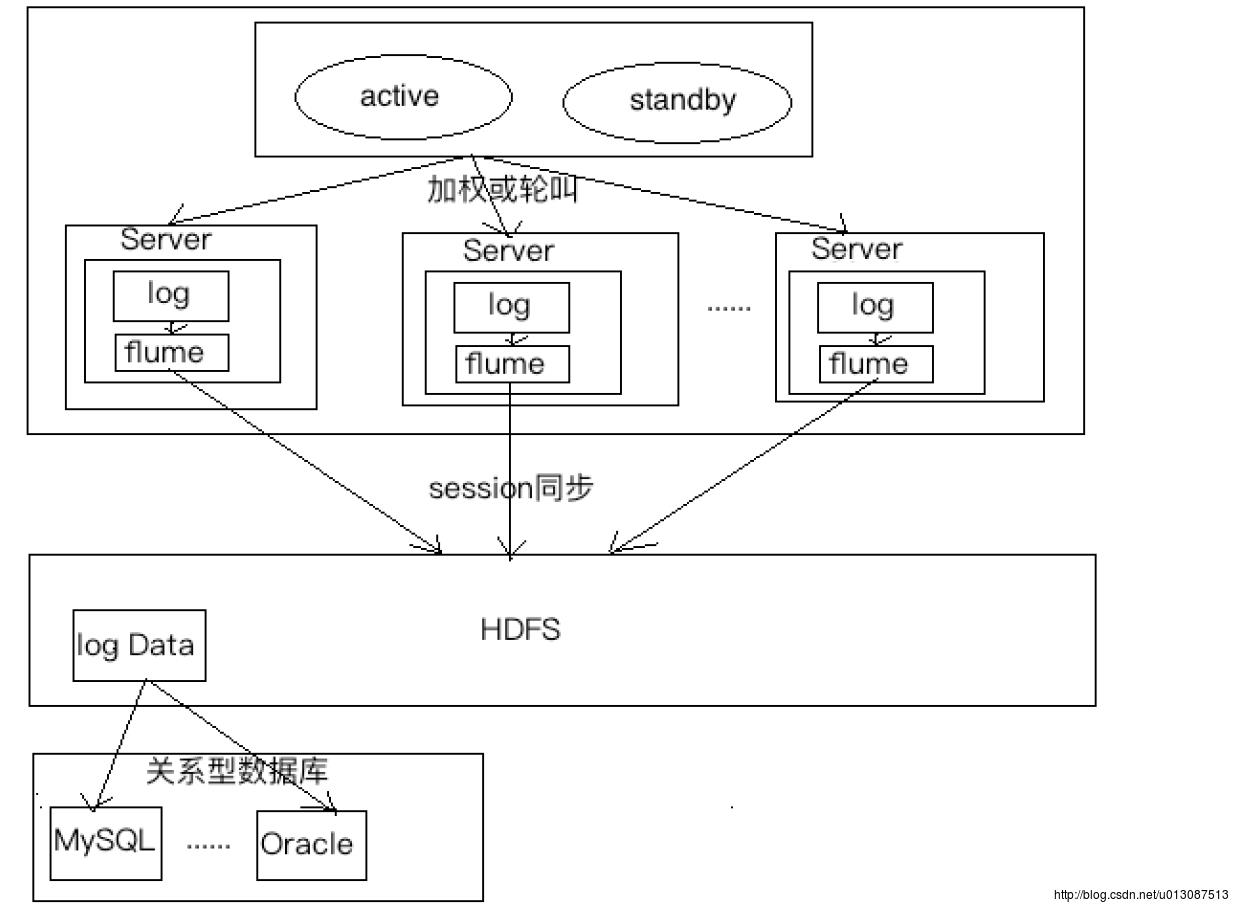
Flume日志搜集工具
flume 日志收集工具的使用分布式系统中每台机器都有自己的日志,如果想进行收集比较麻烦。
因此可以在每台机器上都安装一个flume,将日志采集、清洗过滤后存入HDFS中,然后将HDFS中的日志结果导入到关系型数据库中,其它模块通过访问关系型数据库就可以将内容展示在页面了。

flume的总体架构(官方文档中的)

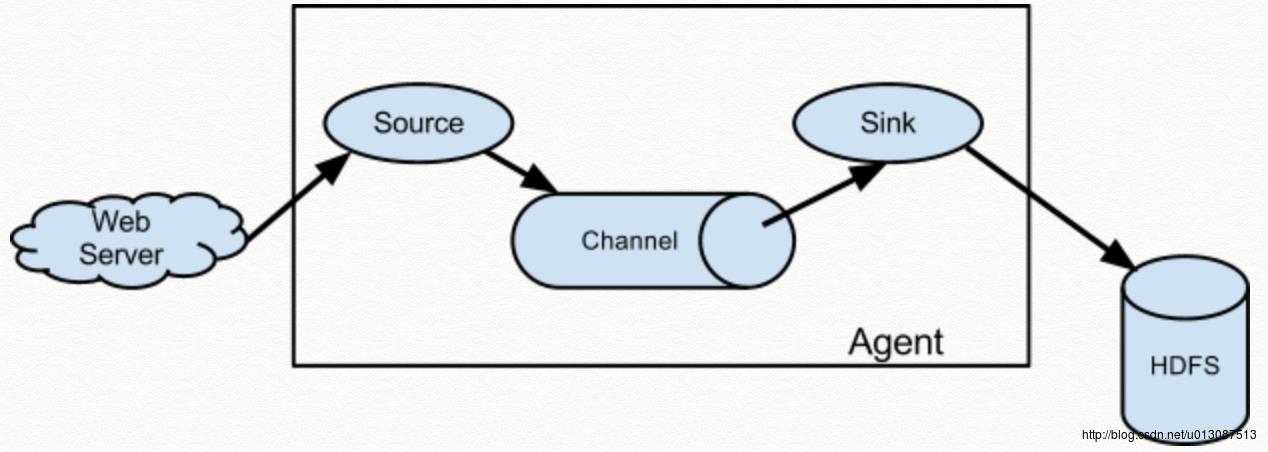
source用来搜集数据
channel 用来暂时存放数据
sink 将数据写入到某种介质里面
官方文档中给出了很多Source、channel、sink的各种实现类、配置以及自定义的方法
下载和安装配置flume
下载地址仍是在Apache下载
上传安装包 我使用的是hadoop3
tar -zxvf apache-flume-1.5.0-bin.tar.gz -C /cloud/
① 配置flume-env.sh
cd /cloud/apache-flume-1.5.0-bin/conf
对flume-env.sh.template 配置文件重命名
mv flume-env.sh.template flume-env.sh
编辑flume-env.sh 修改配置内容如下
JAVA_HOME=/usr/java/jdk1.8.0_144
② 配置source、channel和sink
在$FLUME_HOME/conf下添加a4.conf配置文件 内容如下:
#定义agent名, source、channel、sink的名称
a4.sources = r1
a4.channels = c1
a4.sinks = k1
#具体定义source
a4.sources.r1.type = spooldir
a4.sources.r1.spoolDir = /root/logs
#具体定义channel
a4.channels.c1.type = memory
#定义channel可以容纳多少条数据
a4.channels.c1.capacity = 10000
#定义channel每次发送数据的条数
a4.channels.c1.transactionCapacity = 100
#定义拦截器,为消息添加时间戳
a4.sources.r1.interceptors = i1
a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#具体定义sink
a4.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.path = hdfs://ns1/flume/%Y%m%d
a4.sinks.k1.hdfs.filePrefix = events-
a4.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a4.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a4.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a4.sinks.k1.hdfs.rollInterval = 60
#组装source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1③将hadoop集群中的core-site.xml和hdfs-site.xml拷贝到flume的conf下
(因为flume并不知道以上配置文件中ns1是NameService还是具体的主机,因此需要将有关的配置拷贝过去)。
cd /cloud/apache-flume-1.5.0-bin/conf
cp /cloud/hadoop-2.7.4/etc/hadoop/core-site.xml ./
cp /cloud/hadoop-2.7.4/etc/hadoop/hdfs-site.xml ./
④如果在没有安装Hadoop的机器上安装flume,需要将Hadoop中关键的几个jar包拷贝到flume的lib文件夹下
hadoop-hdfs-x.x.x.jar
hadoop-common-x.x.x.jar
hadoop-configuration-x.x.x.jar
然后进入到flume安装的根目录下按照a4.conf配置文件启动
./bin/flume-ng agent -n a4 -c conf -f ./conf/a4.conf -Dflume.root.logger=INFO,console
往/root/logs目录下拖进日志等文件进行测试
在HDFS上查看
crontab 定时器的使用
flume每隔一段时间就会进行日志的搜集 因此涉及到shell脚本的编写和定时器的使用
基本格式 :
* * * * * command
分 时 日 月 周 命令
第1列表示分钟1〜59 每分钟用*或者 */1表示
第2列表示小时1〜23(0表示0点)
第3列表示日期1〜31
第4列表示月份1〜12
第5列标识号星期0〜6(0表示星期天)
第6列要运行的命令
crontab文件的一些例子:
30 21 * * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每晚的21:30重启apache。
45 4 1,10,22 * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每月1、10、22日的4 : 45重启apache。
10 1 * * 6,0 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每周六、周日的1 : 10重启apache。
0,30 18-23 * * * /usr/local/etc/rc.d/lighttpd restart
上面的例子表示在每天18 : 00至23 : 00之间每隔30分钟重启apache。
0 23 * * 6 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每星期六的11 : 00 pm重启apache。
* */1 * * * /usr/local/etc/rc.d/lighttpd restart
每一小时重启apache
* 23-7/1 * * * /usr/local/etc/rc.d/lighttpd restart
晚上11点到早上7点之间,每隔一小时重启apache
0 11 4 * mon-wed /usr/local/etc/rc.d/lighttpd restart
每月的4号与每周一到周三的11点重启apache
0 4 1 jan * /usr/local/etc/rc.d/lighttpd restart
一月一号的4点重启apache
名称 : crontab
使用权限 : 所有使用者
使用方式 :
crontab file [-u user]-用指定的文件替代目前的crontab。
crontab-[-u user]-用标准输入替代目前的crontab.
crontab-1[user]-列出用户目前的crontab.
crontab-e[user]-编辑用户目前的crontab.
crontab-d[user]-删除用户目前的crontab.
crontab-c dir- 指定crontab的目录。
crontab文件的格式:M H D m d cmd.
M: 分钟(0-59)。
H:小时(0-23)。
D:天(1-31)。
m: 月(1-12)。
d: 一星期内的天(0~6,0为星期天)。
cmd要运行的程序,程序被送入sh执行,这个shell只有USER,HOME,SHELL这三个环境变量
说明 :
crontab 是用来让使用者在固定时间或固定间隔执行程序之用,换句话说,也就是类似使用者的时程表。-u user 是指设定指定
user 的时程表,这个前提是你必须要有其权限(比如说是 root)才能够指定他人的时程表。如果不使用 -u user 的话,就是表示设
定自己的时程表。
参数 :
crontab -e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑器,则请先设定 VISUAL 环境变数
来指定使用那个文字编辑器(比如说 setenv VISUAL joe)
crontab -r : 删除目前的时程表
crontab -l : 列出目前的时程表
crontab file [-u user]-用指定的文件替代目前的crontab。
时程表的格式如下 :
f1 f2 f3 f4 f5 program
其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份中的第几日,f4 表示月份,f5 表示一个星期中的第几天。program 表示要执
行的程序。
当 f1 为 * 时表示每分钟都要执行 program,f2 为 * 时表示每小时都要执行程序,其馀类推
当 f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行,f2 为 a-b 时表示从第 a 到第 b 小时都要执行,其馀类推
当 f1 为 */n 时表示每 n 分钟个时间间隔执行一次,f2 为 */n 表示每 n 小时个时间间隔执行一次,其馀类推
当 f1 为 a, b, c,... 时表示第 a, b, c,... 分钟要执行,f2 为 a, b, c,... 时表示第 a, b, c...个小时要执行,其馀类推
使用者也可以将所有的设定先存放在档案 file 中,用 crontab file 的方式来设定时程表。
例子 :
#每天早上7点执行一次 /bin/ls :
0 7 * * * /bin/ls
在 12 月内, 每天的早上 6 点到 12 点中,每隔3个小时执行一次 /usr/bin/backup :
0 6-12/3 * 12 * /usr/bin/backup
周一到周五每天下午 5:00 寄一封信给 alex@domain.name :
0 17 * * 1-5 mail -s "hi" alex@domain.name < /tmp/maildata
每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分....执行 echo "haha"
20 0-23/2 * * * echo "haha"
注意 :
当程序在所指定的时间执行后,系统会寄一封信,显示该程序执行的内容,若是不希望收到这样的信,需要在每一行空一格之
后加上 > /dev/null 2>&1 即可
例子2 :
#每天早上6点10分
10 6 * * * date
#每两个小时
0 */2 * * * date
#晚上11点到早上8点之间每两个小时,早上8点
0 23-7/2,8 * * * date
#每个月的4号和每个礼拜的礼拜一到礼拜三的早上11点
0 11 4 * mon-wed date
#1月份日早上4点
0 4 1 jan * date
范例
$crontab -l 列出用户目前的crontab.Flume+hive+sqoop+Hadoop 进行日志处理
日志格式:每行记录有5部分组成:1.访问ip
2.访问时间
3.访问资源
4.访问状态
5.本次流量
————————————————————————————————————————
统计指标:
①浏览量PV
定义:页面浏览量即为PV(Page View),是指所有用户浏览页面的总和,一个独立用户每打开一个页面就被记录1 次。
分析:网站总浏览量,可以考核用户对于网站的兴趣,就像收视率对于电视剧一样。但是对于网站运营者来说,更重要的是,每个栏目下的浏览量。
公式:记录计数
②访客数UV(包括新访客数、新访客比例)
定义:访客数(UV)即唯一访客数,一天之内网站的独立访客数( 以Cookie 为依据),一天内同一访客多次访问网站只计算1 个访客。
分析:在统计工具中,我们经常可以看到,独立访客和IP数的数据是不一样的,独立访客都多于IP数。那是因为,同一个IP地址下,可能有很多台电脑一同使用,这种情况,相信都很常见。
还有一种情况就是同一台电脑上,用户清空了缓存,使用360等工具,将cookie删除,这样一段时间后,用户再使用该电脑,进入网站,这样访问数UV也被重新加一。
当然,对于网站统计来说,关于访客数需要注意的另一个指标就是新访客数,新访客数据可以衡量,网站通过推广活动,所获得的用户数量。新访客对于总访客数的比值,可以看到网站吸引新鲜血液的能力,及如何保留旧有用户。
注册用户计算公式:对访问member.php?mod=register的不同ip,计数
③IP数
定义:一天之内,访问网站的不同独立IP 个数加和。其中同一IP无论访问了几个页面,独立IP 数均为1。
分析:这是我们最熟悉的一个概念,无论同一个IP上有多少电脑,或者其他用户,从某种程度上来说,独立IP的多少,是衡量网站推广活动好坏最直接的数据。
公式:对不同ip,计数
④ 跳出率
定义:只浏览了一个页面便离开了网站的访问次数占总的访问次数的百分比,即只浏览了一个页面的访问次数 / 全部的访问次数汇总。
分析:跳出率是非常重要的访客黏性指标,它显示了访客对网站的兴趣程度:跳出率越低说明流量质量越好,访客对网站的内容越感兴趣,这些访客越可能是网站的有效用户、忠实用户。
该指标也可以衡量网络营销的效果,指出有多少访客被网络营销吸引到宣传产品页或网站上之后,又流失掉了,可以说就是煮熟的鸭子飞了。比如,网站在某媒体上打广告推广,分析从这个推广来源进入的访客指标,其跳出率可以反映出选择这个媒体是否合适,广告语的撰写是否优秀,以及网站入口页的设计是否用户体验良好。
公式:(1)统计一天内只出现一条记录的ip,称为跳出数
(2)跳出数/PV
⑤ 版块热度排行榜
定义:版块的访问情况排行。
分析:巩固热点版块成绩,加强冷清版块建设。同时对学科建设也有影响。
公式:按访问次数、停留时间统计排序
————————————————————————————————————————
开发步骤:
1.通过flume采集数据(通过定时器将日志拷贝到flume指定的目录下)
2.对数据进行清洗
3.使用hive进行数据的多维分析
4.把hive分析结果通过sqoop导出到mysql中
5.提供视图工具供用户使用(使用报表工具)
对数据进行清洗:对无效数据进行过滤
使用hive进行分析:可以在hive上建立一个外部分区表(按照年月日进行分析),可以根据具体业务分析写好语句 自动执行
————————————————————————————————————————
实际开发: flume+hive+hadoop 进行日志的处理
日志原始数据的格式如下:

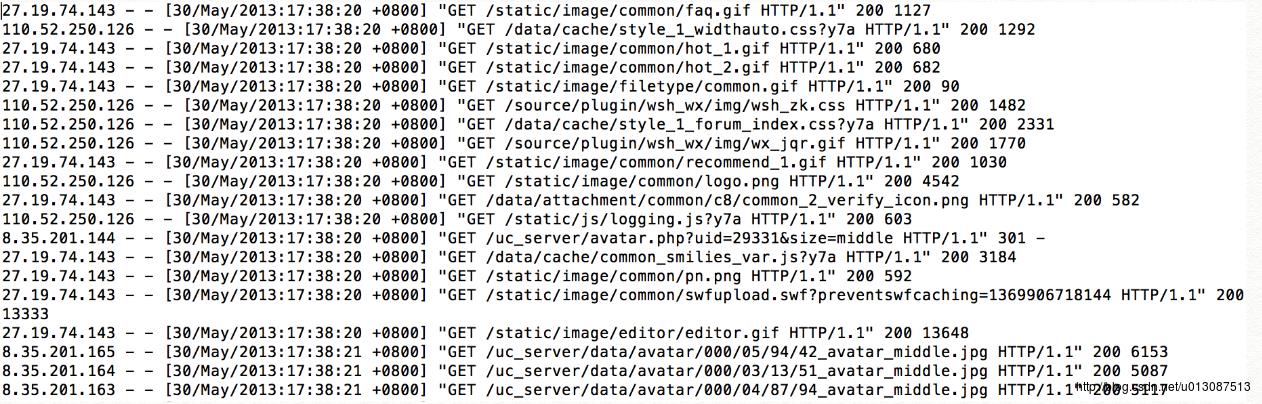
① 初始化,使用hive创建外部分区表
flume监控指定的文件夹,将原始数据存入了HDFS,建立分区表就是为了将原始数据清洗后的内容进行分区存放。
hive> create external table log_td (ip string, logtime string, url string) partitioned by (logdate string) row format delimited fields terminated by '\\t' location '/cleaned';
② 新建MapReduce实现原始数据的清洗过滤,并打成jar包(cleaner.jar) 上传到Linux上
要打包的程序如下 :
package hadoop.mr.cleaner;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Locale;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Cleaner
public static void main(String[] args) throws Exception
final String inputPath = args[0];
final String outPath = args[1];
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Cleaner.class);
FileInputFormat.setInputPaths(job, new Path(inputPath));
job.setMapperClass(CleanMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(CleanReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileOutputFormat.setOutputPath(job, new Path(outPath));
job.waitForCompletion(true);
public static class CleanMapper extends Mapper<LongWritable, Text, LongWritable, Text>
LogParser parser = new LogParser();
Text v2 = new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException
final String line = value.toString();
final String[] parsed = parser.parse(line);
final String ip = parsed[0];
final String logtime = parsed[1];
String url = parsed[2];
//过滤所有静态的资源请求
if(url.startsWith("GET /static")||url.startsWith("GET /uc_server"))
return;
if(url.startsWith("GET"))
url = url.substring("GET ".length()+1, url.length()-" HTTP/1.1".length());
if(url.startsWith("POST"))
url = url.substring("POST ".length()+1, url.length()-" HTTP/1.1".length());
v2.set(ip+"\\t"+logtime +"\\t"+url);
context.write(key, v2);
public static class CleanReducer extends Reducer<LongWritable, Text, Text, NullWritable>
@Override
protected void reduce(LongWritable k2, Iterable<Text> v2s,Context context) throws IOException, InterruptedException
for (Text v2 : v2s)
context.write(v2, NullWritable.get());
class LogParser
public static final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH);
public static final SimpleDateFormat dateformat1=new SimpleDateFormat("yyyyMMddHHmmss");
// public static void main(String[] args) throws ParseException
// final String S1 = "27.19.74.143 - - [30/May/2013:17:38:20 +0800] \\"GET /static/image/common/faq.gif HTTP/1.1\\" 200 1127";
// LogParser parser = new LogParser();
// final String[] array = parser.parse(S1);
// System.out.println("样例数据: "+S1);
// System.out.format("解析结果: ip=%s, time=%s, url=%s, status=%s, traffic=%s", array[0], array[1], array[2], array[3], array[4]);
//
/**
* 解析日志的行记录
* @param line
* @return 数组含有5个元素,分别是ip、时间、url、状态、流量
*/
public String[] parse(String line)
String ip = parseIP(line);
String time;
try
time = parseTime(line);
catch (Exception e1)
time = "null";
String url;
try
url = parseURL(line);
catch (Exception e)
url = "null";
String status = parseStatus(line);
String traffic = parseTraffic(line);
return new String[]ip, time ,url, status, traffic;
private String parseTraffic(String line)
final String trim = line.substring(line.lastIndexOf("\\"")+1).trim();
String traffic = trim.split(" ")[1];
return traffic;
private String parseStatus(String line)
String trim;
try
trim = line.substring(line.lastIndexOf("\\"")+1).trim();
catch (Exception e)
trim = "null";
String status = trim.split(" ")[0];
return status;
private String parseURL(String line)
final int first = line.indexOf("\\"");
final int last = line.lastIndexOf("\\"");
String url = line.substring(first+1, last);
return url;
private String parseTime(String line)
final int first = line.indexOf("[");
final int last = line.indexOf("+0800]");
String time = line.substring(first+1,last).trim();
try
return dateformat1.format(FORMAT.parse(time));
catch (ParseException e)
e.printStackTrace();
return "";
private String parseIP(String line)
String ip = line.split("- -")[0].trim();
return ip;


③ 创建一个shell脚本
touch daily.sh
# 添加执行权限
chmod +x daily.sh
④ 编写shell脚本
vim /root/custom_shell/daily.sh
内容如下:
# 获取当前日期,和flume输出文件夹格式一致
CURRENT=`/bin/date +%Y%m%d`
tab=`/bin/date +%Y%m%d`
# 将flume当前日期采集的数据经清洗过滤后存入 指定的hive分区表
# /cloud/hadoop-2.7.4/bin/hadoop jar /root/myjars/Cleaner.jar /flume/$CURRENT /cleaned/$CURRENT
# 通知hive在log_td中添加了一个分区,在Metastore中记录元信息
# /cloud/apache-hive-0.13.0-bin/bin/hive -e "alter table log_td add partition (logdate=$CURRENT) location '/cleaned/$CURRENT'"
# 按照日期从分区表中统计pv
# /cloud/apache-hive-0.13.0-bin/bin/hive -e "create table pv_$tab row format delimited fields terminated by '\\t' as select $CURRENT, count(1) from log_td where logdate=$CURRENT "
# 按照日期从分区表中统计uv
# /cloud/apache-hive-0.13.0-bin/bin/hive -e "create table uv_$tab row format delimited fields terminated by '\\t' as select $CURRENT, count(distinct ip) from log_td where logdate=$CURRENT "
# 按照日期查询注册的人数
# /cloud/apache-hive-0.13.0-bin/bin/hive -e "select count(*) from log_td where logdate = $CURRENT and instr(url, 'member.php?mod=register')>0;"
# 按照访问次数查询当天的VIP用户
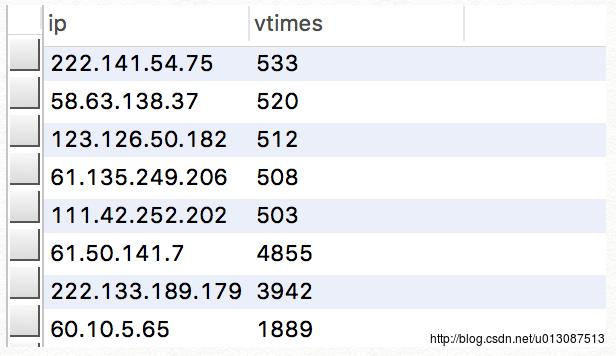
# /cloud/apache-hive-0.13.0-bin/bin/hive -e "create table vip_$tab row format delimited fields terminated by '\\t' as select ip, count(*) as vtimes from log_td where logdate=$CURRENT group by ip having vtimes >= 50 order by vtimes desc limit 20 "
# 远程连接MySQL创建与vip对应的表
mysql -h192.168.0.103 -P3306 -uroot -proot hadoop -e "create table if not exists vip(ip varchar(20),vtimes bigint)"
# 将vip_$tab中的数据导入到指定主机的MySQL数据库中
/cloud/sqoop-1.4.4/bin/sqoop export --connect jdbc:mysql://192.168.0.103:3306/hadoop --username root --password root --export-dir "/user/hive/warehouse/vip_$tab" --table vip --fields-terminated-by '\\t'
最后在192.168.0.103主机上MySQL中查看hadoop数据库的vip表 数据也成功导入
后续工作: 1.周期性把日志数据导入到hdfs中
2.周期性把明细日志导入hbase存储
3.周期性使用hive进行数据的多维分析
4.周期性把hive分析结果导入到mysql中
以上是关于Hadoop详解——Hive的原理和安装配置和UDF,flume的安装和配置以及简单使用,flume+hive+Hadoop进行日志处理的主要内容,如果未能解决你的问题,请参考以下文章