Elasticsearch聚合优化 | 聚合速度提升5倍!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch聚合优化 | 聚合速度提升5倍!相关的知识,希望对你有一定的参考价值。

1、聚合为什么慢?
大多数时候对单个字段的聚合查询还是非常快的, 但是当需要同时聚合多个字段时,就可能会产生大量的分组,最终结果就是占用 Elasticsearch大量内存,从而导致 OOM 的情况发生。
实践应用发现,以下情况都会比较慢:
1)待聚合文档数比较多(千万、亿、十亿甚至更多);
2)聚合条件比较复杂(多重条件聚合);
3)全量聚合(翻页的场景用)。
2、聚合优化方案探讨
优化方案一:默认深度优先聚合改为广度优先聚合。
"collect_mode" : "breadth_first"
depth_first 直接进行子聚合的计算
breadth_first 先计算出当前聚合的结果,针对这个结果在对子聚合进行计算。
优化方案二: 每一层terms aggregation内部加一个 “execution_hint”: “map”。
"execution_hint": "map"
国内解释最详细的版本来自Wood大叔: 
Map方式的结论可简要概括如下:
1)查询结果直接放入内存中构建map,在查询结果集小的场景下,速度极快;
2)但如果待结果集合很大的情况,map方式不一定也快。
优化方案N:
待进一步深入实践......
3、做个实验
聚合的平衡点是多少呢?
3.1 实验场景
场景一:在近亿的document中,检索满足给定条件的数据,并对聚合结果全量聚合。
场景二:在百万级别的document中,全量聚合。
场景三:在近亿级别的document中,全量聚合。
3.2 聚合操作
POST index_*/_search
{
"sort": [
{
"nrply": "desc"
}],
"aggs": {
"count_over_sin": {
"terms": {
"field": "sin_id","execution_hint": "map",
"size": 1000,
"collect_mode": "breadth_first"
}
}},
"size":0
}
1)修改索引名称,以获取更多的文档。
2)map模式添加 “execution_hint”: “map”,默认是global_ordinals模式。
3)”size”: 1000,设定聚合取值。
3.3 聚合结果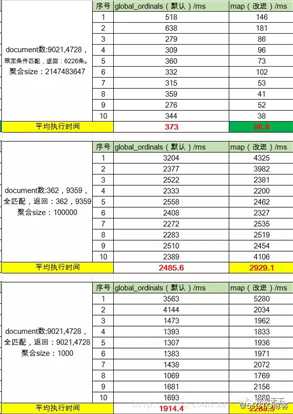
3.4 结果分析
对比场景一与场景二、三,说明:
当结果集合比较少的时候,map聚合方式明显速度更快,速度提升了接近5倍!
当结果集合比较大的时候(百万——亿级别)的时候,传统的聚合方式会比map方式快。
4、小结
global_ordinals是关键字字段( keyword field )的默认选项,它使用 全局顺序(global ordinals) 来动态分配存储区,因此内存使用情况与作为聚合作用域一部分的文档值的数量成线性关系。
只有极少数文档与查询匹配匹配时才应考虑使用map方式。
默认情况下,只有在脚本上运行聚合时才会使用map,因为它们没有序号( ordinals )。否则,基于 顺序(ordinals) 的执行模式会相对更快。
参考:
http://t.cn/R8WI6QD
http://t.cn/R8WIKta
https://elasticsearch.cn/question/1008
http://t.cn/R8WIpYn
以上是关于Elasticsearch聚合优化 | 聚合速度提升5倍!的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearches Elasticsearch 聚合性能优化六大猛招