elasticsearch检索,聚合,建模,优化--《elasticsearch核心技术与实战》笔记
Posted jazon@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elasticsearch检索,聚合,建模,优化--《elasticsearch核心技术与实战》笔记相关的知识,希望对你有一定的参考价值。
检索相关
- 基于Term的查询
Term是表达语意的最小单位,在ES中,term查询,对输入不做分词,会将输入作为一个整体,在倒排索引中查找准确的词项,并且使用相关度算分公式为每个包含该词项的文档进行相关度算分。

第一个查询能查得到,第二个查询查不到。根据dynamic mapping,desc字段是text,会对文档内容进行分词器处理。所以录入iPone会在倒排索引里记录了iphone,所以能查得到。productId经过分词器处理后,会以’-'切割成一个一个字符存起来,所以term查询去找productId是找不到的。dynaminc mapping默认是会创建多字段mapping的,所以解决方案是使用productId.keyword。
- 符合查询-Constant Score转为Filter
1.将Query转成Filter,忽略TF-IDF计算,避免相关性算分的开销
2.Filter可以有效利用缓存

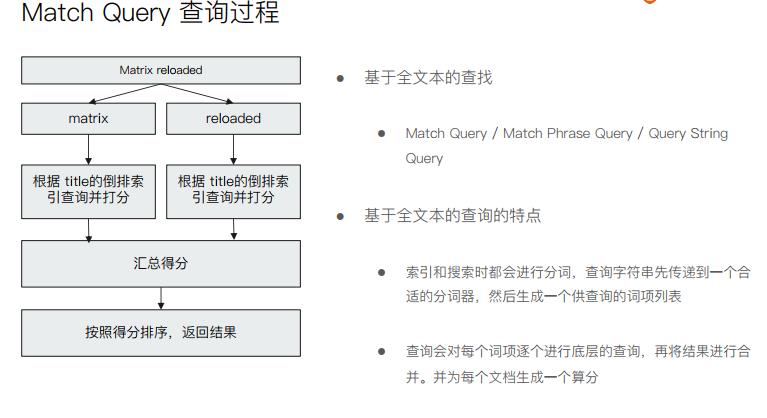
- 基于全文的查询
MatchQuery/Match Phrase Query/Query String Query,
查询字符串先传递一个合适的分词器,然后生成一个供查询的词项列表,对每个词逐个进行底层的查询,最终将结果进行合并,并为每个文档生成一个算分。

Operator操作,确定match query的多个单词的关系

Minium_should_match,最少匹配个数

Match Phrase Query
Phrase Match意为短语匹配,查询词语会经过分词器处理,但是它要求文档包含所有搜索词条的文档,并且词条的位置要邻接,可以通过slop参数控制词条间距。

总结
- 结构化数据

// 布尔值
POST products/_search
{
"query": {
"term": {
"avaliable": {
"value": "false"
}
}
}
}
// 数字range,日期range
...
// 处理空值,必需不存在date字段
POST products/_search
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "date"
}
}
}
}
}
// 查找多个精确值,terms,相当于term的OR
// 查询name 带Mike或者John的
POST stu/_search
{
"query": {
"terms": {
"name.keyword": ["Mike", "John"]
}
}
}
- 对于多字段类型,term是包含而不是相等,对于多字段查询要注意

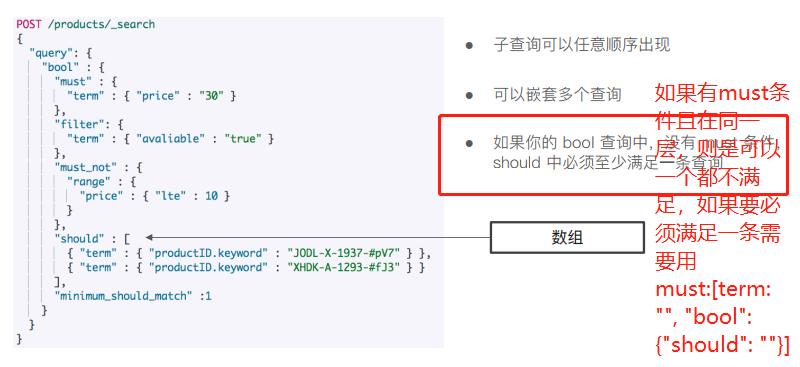
- bool查询

- bool查询语法
- 单字符串多字段查询: Dis Max Query
Dis Max Query将任何与任一查询匹配的文档作为结果返回,采用字段上最匹配的评分最终评分返回。

上面的查询 Brown fox在文档2的title最匹配,所以它的socre会高一些。
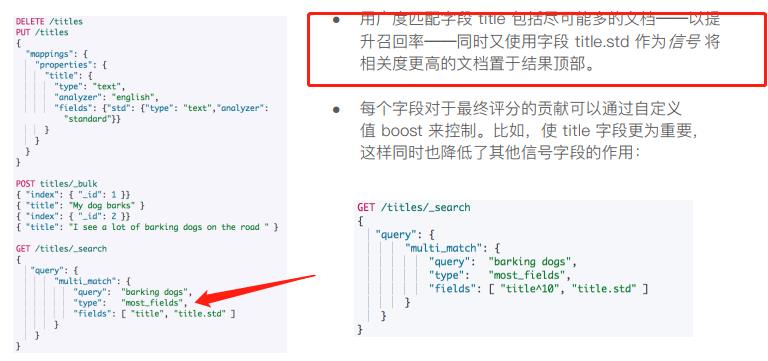
- 单字符串多字段查询Multi Match
三种场景: 1.最佳字段,当字段之间相互竞争,又相互关联,评分取最匹配字段。2.多数字段,在主字段抽取词干,加入同义词,以匹配更多文档,相同的文本,加入子字段(Standard Analyzer),以提供更加精确的匹配,其他字段作为匹配文档提高相关度的信号,匹配字段越多则越好。3.混合字段,对于某些实体,例如人名,地址,图书信息,需要在多个字段中确定信息,单个字段只能作为整体的一部分。
Best Fields的例子

Most Fields的例子
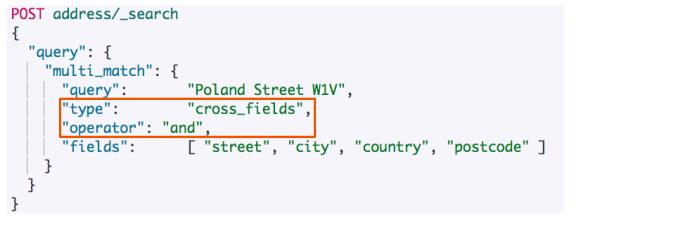
Cross Fields跨字段搜索,解决不能使用operator问题,要求每个查询词都要出现,用and。
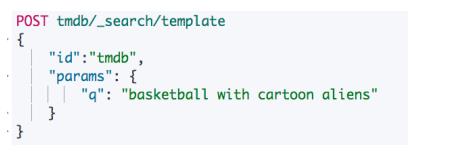
- Search Template 解耦程序
创建search template

使用search template进行查询
- 使用索引别名

- 使用alias创建查询视图

- Elasticsearch Suggester API

- Term Suggester
假设用户输入的检索词是错的,会到指定的field搜索,返回建议的词。

结果:

- Phrase Suggester

- Completion Suggester
提供了"自动完成"的功能,用户没输入一个字符,就需要即时发送一个查询请求到后端查找匹配项。

搜索数据:

- Context Suggester
可以在搜索中加入更多的上下文信息,例如,输入"start",只搜索咖啡相关,建议"starbucks",只搜索电影相关,“star wars”。
定义Mapping


跨集群搜索
单集群,当水平扩展时,节点数不能无限增加,当集群的meta信息(节点,索引,集群状态)过多,会导致更新压力变大,单个Active Master会成为性能瓶颈,导致整个集群无法正常工作。
Elasticsearch 5.3引入了跨集群搜索的功能,推荐使用:
- 允许任何节点扮演federated节点,以轻量的方式,将搜索请求进行代理
- 不需要以Client Node的形式加入其他集群。
集群分布式模型及选主与脑裂问题
- Elasticsearch的分布式架构带来的好处,1.存储的水平扩容,支持PB级数据。2.提高系统的可用性,部分节点停止服务,整个集群的服务不受影响。Elasticsearch的分布式架构:1.不同的集群通过不同的名字来区分,默认名字"elasticsearch"。2.通过配置文件修改,或者在命令行 -E cluster.name=yourclustername 进行设定。
- Coordinating Node
处理请求的节点,叫Coordinating Node,路由请求到正确的节点,例如创建索引的请求,需要路由到Master节点,所有节点默认都是Coordinating Node,通过将其他类型设置成False, 使其成为Dedicated Coordinating Node。
- Data Node
可以保存数据的节点,叫做Data Node,用于保存分片数据,在数据扩展上起到了至关重要的作用,通过增加数据节点解决数据水平扩展和解决数据单点问题。
- Master Node
处理创建,删除索引等请求,决定分片被分配到哪个节点,负责索引创建与删除,维护并更新cluster state,Master Node在部署上需要解决单点问题,为一个集群设置多个Master节点,每个节点只承担Master的单一角色。
- Master Eligible Nodes & 选主流程
一个集群,支持配置多个Master Eligible节点,这些节点可以在必要时参与选主流程,成为Master节点,每个节点启动后,默认就是一个Master eligible节点,可以设置node.master:false禁止。当集群内第一个Master eligible节点启动的时候,它会将自己选举成Master节点。
- 集群状态
集群状态信息,维护了一个集群中必要的信息: 1.所有的节点信息。2.所有的索引和其相关的Mapping与Setting信息。2.分片的路由信息。在每个节点上都保存了集群的状态信息,只有Master节点才能修改集群的状态信息,并负责同步给其他节点,因为任意节点都能修改信息会导致Cluster State信息的不一致。
- 选主过程
互相Ping对方,NodeId低的会成为被选举的节点,其他节点会加入集群,但是不承担Master节点的角色,一旦发现被选中的主节点丢失,就会选举出新的Master节点。
- 脑裂问题,es7已经解决了这个问题。
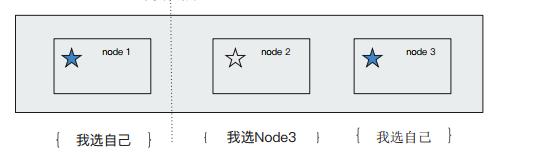
- 节点配置
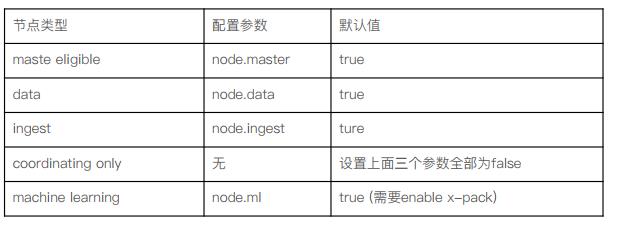
文档分布式存储
shard=hash(_routing)%number_of_primary_shards,_routing值默认是文档id,可以指定。
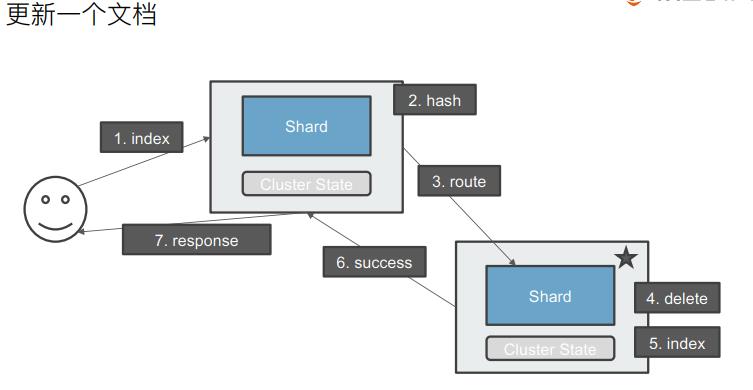
分片及其生命周期
- 什么是ES的分片
ES中最小的工作单元/是一个Lucene的Index
- 倒排索引的不可变性
倒排索引采用Immutable Design,一旦生成,不可更改,不可变性带来的好处:无需考虑并发写文件的问题,避免了锁机制带来的性能问题。一旦读入内核的文件系统缓存,便留在那,只要文件系统有足够的空间,大部分请求就会直接内存命中,不会命中磁盘,提升了很大的性能,缓存容易生成和维护,数据可以被压缩。不可变性,带来了的挑战:如果需要让一个新文档可以被搜索,需要重建整个索引。
- Lucene Index
在Lucene中,单个倒排索引文件被称为Segment,Segment是自包含,不可变更的,多个Segments汇总在一起,称为Lucene的Index,其对应的就是ES的Shard。当有新文档写入时,会生成新Segment,查询时会同时查询所有Segments,并且对结果汇总,Lucene中有一个文件,用来记录所有Segments信息,叫做Commit Point。删除文档信息,保存在".del"文件中。
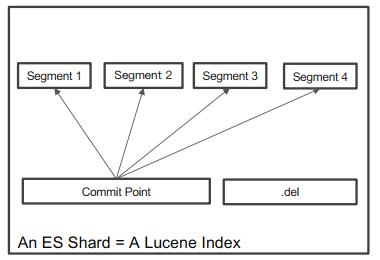
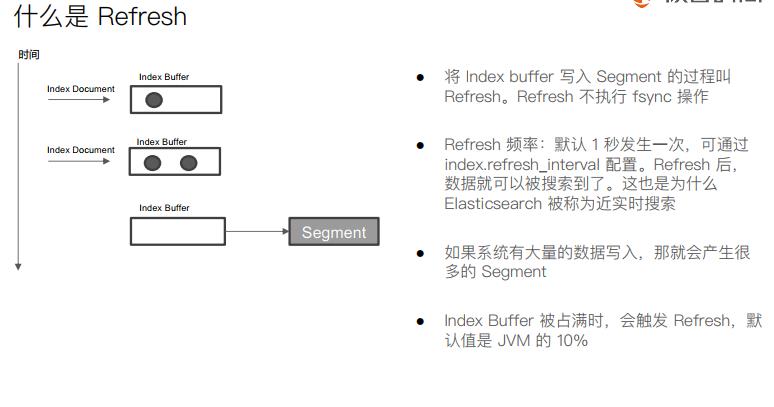
Refresh的间隔是一秒,所以Es被称为近实时搜索。
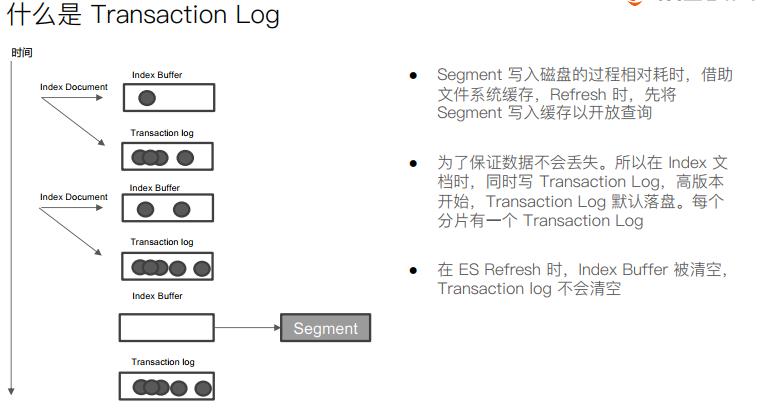
Transaction Log类似于Innodb的redolog,为了保证数据不丢做的日志。
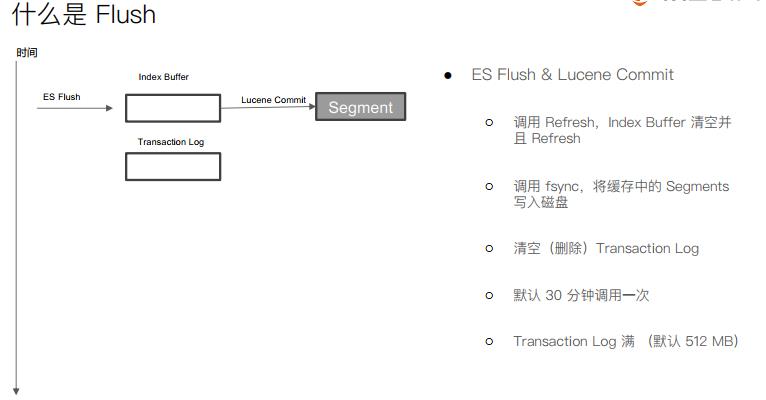

ElasticSearch的QueryThenFetch
Query阶段: 用户发出搜索请求到ES节点,节点收到请求后,会以Coordinating节点身份,选择分片,发送查询请求,被选中的分片执行查询,进行排序,然后每个分片都会返回From+Size个排序后的文档Id和排序值给Coordinating节点。Fetch阶段: Coordinating Node会将Query阶段,从每个分片获取的排序后的文档Id列表,重新进行排序,选择From到From+Size的文档Id,以multi get请求的方式,到相应的分片获取详细的文档数据。
- QueryThenFetch潜在的问题
每个分片上需要查的文档个数=from+size,最终协调节点需要处理number_of_shard * (from + size),深度分页。相关性算分,每个分片都基于自己的分片上的数据进行相关度计算,这会导致打分偏离。
- 解决算分不准的方法
1.数据量不大时,将主分片设置为1。2.使用DFS Query Then Fetch,会进行统一的算分,不推荐。
排序及Doc Values & Field Data
Elasticsearch默认采用相关性算分对结果进行降序排序,可以通过设定sorting参数,自定设定排序,不过不用_score排序,算分为null。

text字段默认是不打开Fielddata的,而且Doc Values对Text无效,意味着要对text字段排序需要打开fielddata。

关闭Doc Values可以提高索引速度,减少磁盘空间,如果重新打开,需要重建索引,如果明确不需要排序及聚合分析,可以关闭。

分页与遍历 --From,Size, Search After & Scroll API
- from/size
默认情况下,查询按照相关度算分排序,返回前10条记录,from即开始位置,size期望获取文档的总数。分布式系统中深度分页的问题,会在每个分片上先都获取1000个文档,然后通过CoordinatingNode聚合所有结果,最后再通过排序选取前1000个文档,页数越深,占用内存越多,为了避免深度分页带来的内存开销,ES有一个设定,默认设定到10000个文档,即From+size必须小于10000。为什么要统一到CoordinatingNode计算呢?
- Search After深度分页问题
SearchAfter不支持指定页数From,只能往下翻,第一步搜索需要指定sort,并且保证值是唯一的(加入_id作为排序条件),然后使用上一次最后一个文档的sort值进行查询。通过唯一排序值定位,将每次要处理的文档书都控制在10。
- Scroll API
创建一个快照,有新的数据写入以后,无法被查到,每次查询后,输入上一次的Scroll Id。

ES文档的并发控制

Bucket & Metric聚合分析与嵌套聚合
聚合查询,建议size设置为0,这样hits就不会返回数据了。
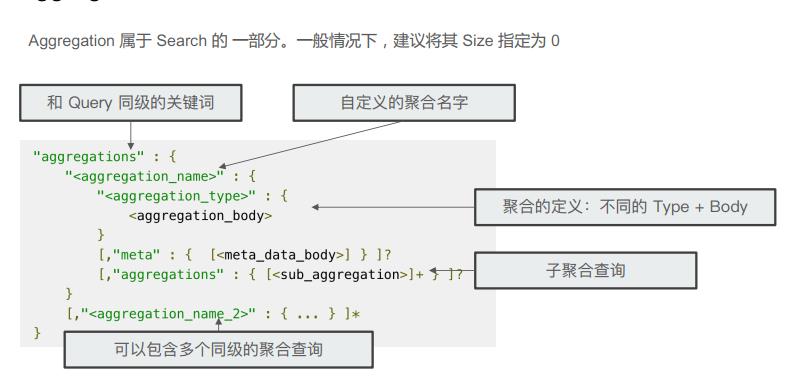
Metric Aggregation

- Bucket
按照一定的规则,将文档分配到不同的桶中,从而达到分配的目的,ES提供一些常见的Bucket Aggregation,Terms和数字类型: Range/Data Range; Histogram/Date Histogram。支持嵌套:也就在桶里再做分桶。
- Terms Aggregation
字段需要打开fielddata,才能进行TermsAggregation,keyword默认支持doc_values,Text需要在Mapping中enable,会按照分词后的结果进行分桶。
- Cardinality
类似SQL中的Distinct
- Bucket Size & Top Hits Demo
获取分桶后,只取顶部的数据。
- 优化Terms聚合的性能
在mapping将keyword类型的field的eager_global_ordinals设置为true,则会给keyword开启global oridinals data-structure。这将使得term agg更加快。
Pipeline聚合
管道的概念: 支持对聚合分析的结果,再次进行聚合分析。Pipeline的分析结果会输出到原结果中,根据位置的不同,分为两类: 1.sibling-结果和现有分析结果同级,比如对所有桶求最大值,求平均值,统计信息,百分位数。2.Parent-结果内嵌到现有聚合分析结果之中,对逐个桶求导,对桶内元素累计求和等.
聚合的作用范围及排序

Filter只对当前的子聚合语句生效;Post_Filter是对聚合分析后的文档进行再次过滤,Size无需设置为0,使用场景:一条语句,获取聚合信息+获取符合条件的文档;Global: 无视query,对全部文档进行统计.
排序

基于子聚合的值排序

聚合精准度问题
类似于CAP理论
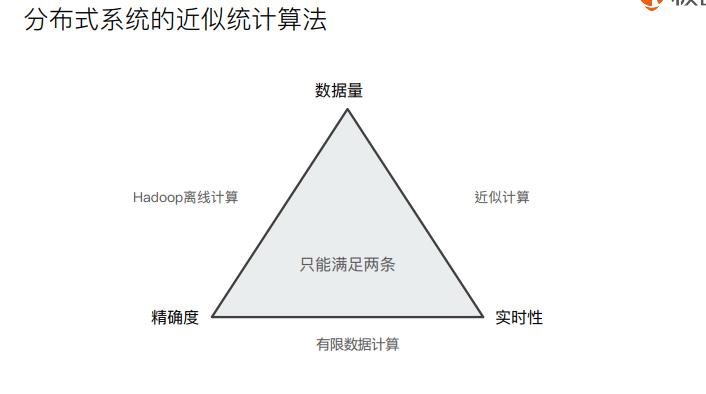
Terms Aggregation的返回值

Terms聚合分析的执行流程
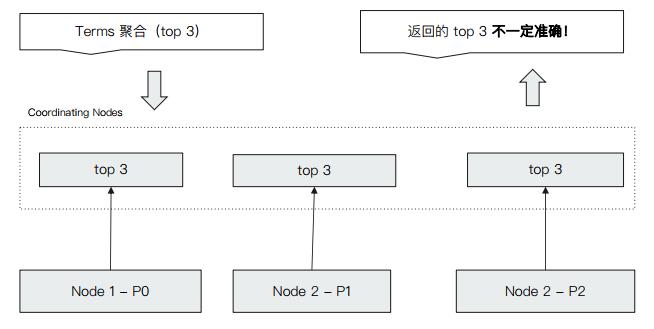
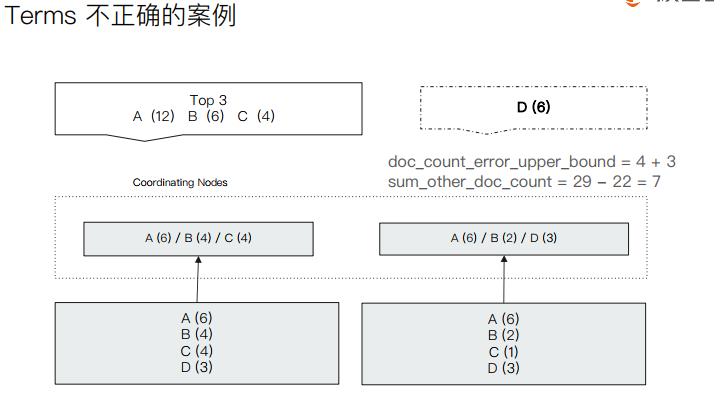
doc_count_error_upper_bound=4+3,意思是左边的分片可能C会被丢弃,右边的分片可能D会被丢弃,因为AB明显大于CD.
sum_other_doc_count = 29 - 22 = 7,意思是总的文档数是29,返回了22个,还有七个没返回.

对象及Nested对象
范式化设计的主要目标是减少不必要的更新,一个完全范式化的数据库经常面临查询缓慢的问题,数据库越范式化,需要join越多的表,范式化节省了存储空间,但是目前存储空间很便宜,范式化简化了更新,但是数据读取操作可能更多.
反范式:不用join,但是更新操作要引起很多数据的更新.
- 在Elasticsearch中处理关联关系
在es中,我们往往考虑使用反范式,读的速度快,无需表链接,无需行锁,一般使用以下四种方法处理关联:
1.对象类型
2.嵌套对象
3.父子关联关系
4.应用端关联
对象类型的数组搜索存在如图问题,搜出来的不是想要的actor


解决方案: 使用nested data type对象
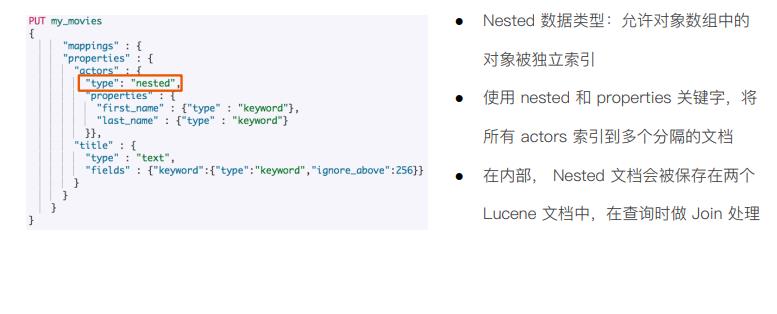
nested的嵌套查询

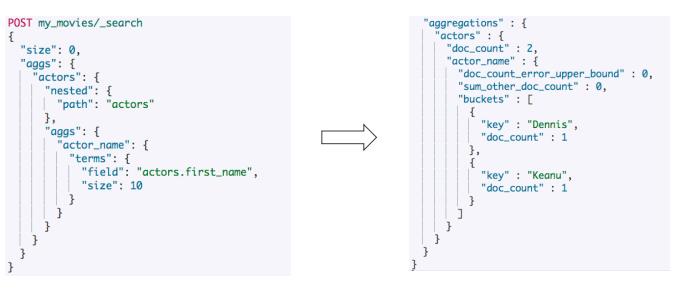
nested的嵌套聚合
文档的父子关系
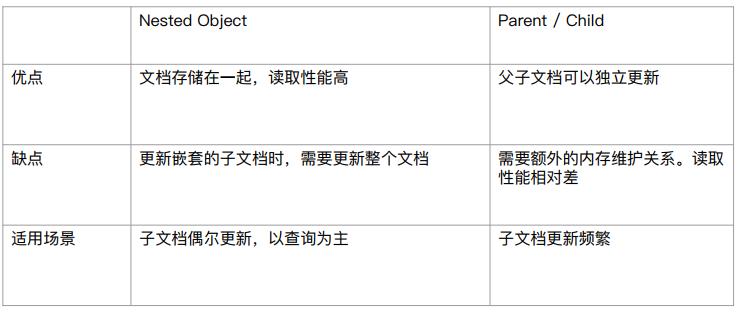
对象和Nested对象的局限性: 每次更新,需要重新索引整个对象(包括根对象和嵌套对象).
ES提供了类似于关系数据库中的Join实现,使用Join数据类型实现,通过维护Parent/Child的关系分离两个对象,分文档和子文档是两个独立的文档,更新父文档无需重新索引子文档,子文档被添加,更新,删除也不会影响父文档和其他的子文档.

嵌套对象VS父子文档
Update By Query & Reindex API
一般在以下几种情况时,我们需要重建索引: 索引的Mappings发生变更,字段类型更改,分词器及字典更新,索引的Settings发生变更,索引的主分片数发生改变,集群内,集群间需要做数据迁移.
Elasticsearch的内置提供的API:
Update By Query:在现有索引上重建
Reindex:在其他索引上重建
一定要尽量使用Index Alias读写数据,即便发生Reindex,也能够实现零停机维护.
Ingest Pipeline与Painless Script
ingest Pipeline可以对doc进行加工,生成最终索引的文档.
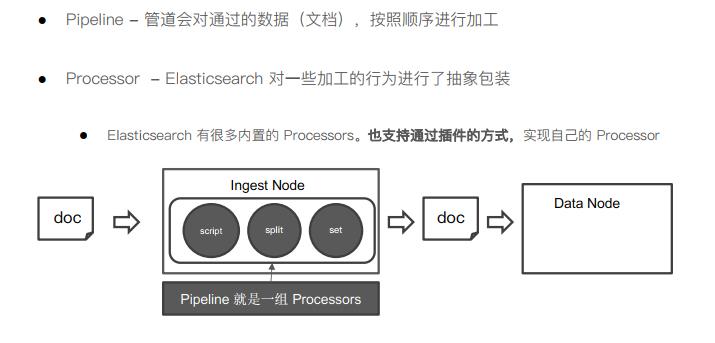

- 使用pipeline
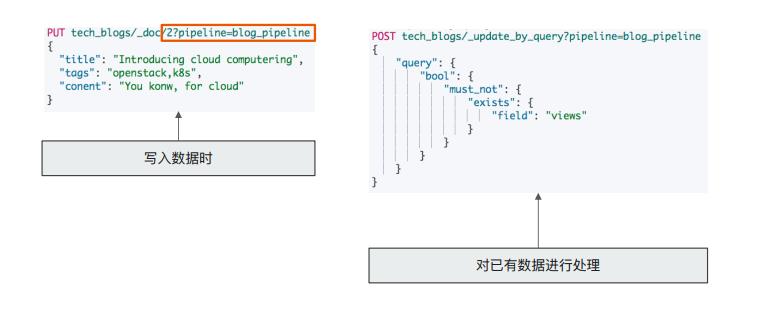
Painless脚本
painless是一种扩展了java的es脚本,可以进行数据处理.
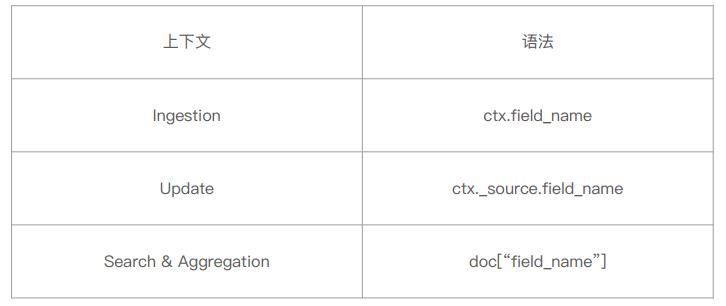
Elasticsearch数据建模实例
数据需求:即实体的属性和实体间的关系,搜索相关的配置
性能需求: 分片数量,字段配置,关系处理
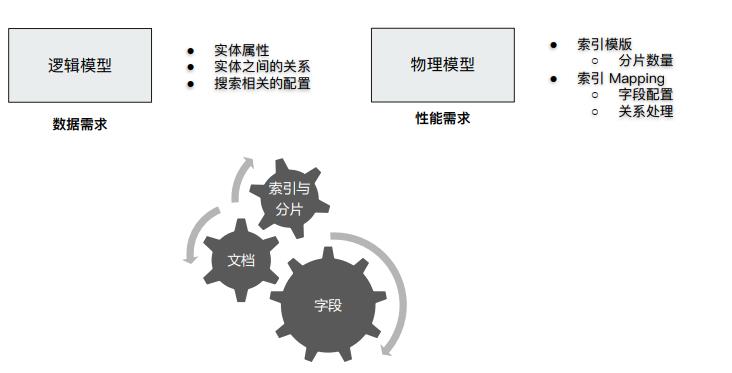
数据建模三个步骤: 1.字段类型.2.是否要搜索及分词3.是否要聚合及排序.4.是否要额外的存储
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nQDeSw4T-1626186205760)(https://cdn.nlark.com/yuque/0/2021/png/12674217/1626101940600-7318773f-89df-4b8c-b649-5c987376ee65.png#align=left&display=inline&height=120&originHeight=120&originWidth=738&size=14454&status=done&style=none&width=738)]
字段类型: Text vs Keyword
- Text,用于全文本字段,文本会被Analyzer分词,默认不支持聚合分析及排序,需要设置fielddata为true.
- keyword,用于id枚举以及不需要分词的文本,例如电话号码,email地址,适用于Filter精准匹配,Sorting和Aggregations.
- 设置多字段类型,默认会为文本类型设置成text,并且设置一个keyword的子字段,在处理人类语言时,通过增加"英文",“拼音”,“标准分词器”,提高搜索结构
字段类型: 结构化数据
- 数值类型: 尽量选择贴近的类型,例如可以用byte,就不要long.
- 枚举类型,设置为keyword,即便是数字,也应该设置成keyword,获取更好的性能.
- 其他:日期/布尔/地理信息
检索
- 如不需要检索,排序和聚合分析,将enable设置成false.
- 如不需要检索,Index设置为false
- 对需要检索的字段,可以通过如下配置设置存储粒度,index_options/Norms,不需要归一化数据时,可以关闭
聚合及排序
- 如不需要检索,排序和聚合分析,将enable设置成false.
- 如不需要排序或者聚合分析功能,Doc_values/fielddata设置成false
- 更新频繁,聚合查询频繁的keyword类型字段,推荐将eager_global_oridianls设置为true
额外的存储
- 是否需要专门存储当前字段的数据,Store设置成true,可以存储该字段的原始内容,一般结合_source的enabled为false时候使用. _source关闭: 节约磁盘,适用于指标型数据,一般建议优先考虑增加压缩比,无法看到_source字段,无法做ReIndex,无法做Update,Kibana中无法做discovery.
_source优化实例
假设文档要存储图书内容的字段,并要求能被搜索同时支持高亮. 此需求会导致_source的内容过大: SourceFiltering只是传输给客户端时进行过滤,Fetch数据时,ES节点还是会传输_source中的数据. 解决方法: 1.关闭_source 2.将每个字段的"store"设置成true.
查询:解决字段过大引发的性能问题

1.返回结果不包含_source字段
2.对于需要显示的信息,可以在查询中指定"stored_fields"
3.禁止_source字段后,还是支持使用highlightsAPI,高亮显示content中匹配的相关信息.
Mapping字段相关配置

Elasticsearch数据建模最佳实践







以上是关于elasticsearch检索,聚合,建模,优化--《elasticsearch核心技术与实战》笔记的主要内容,如果未能解决你的问题,请参考以下文章