HashMap 的 7 种遍历方式与性能分析!「修正篇」
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap 的 7 种遍历方式与性能分析!「修正篇」相关的知识,希望对你有一定的参考价值。

这是我的第 57 篇原创文章
首先,给大家说声抱歉~
事情经过是这样子的,五一节前我发布了一篇文章《HashMap 的 7 种遍历方式与性能分析!》,但是好心的网友却发现了一个问题,他说 “测试时使用了 sout 打印信息会导致测试的结果不准确,因为这样测试的话,大部分的性能消耗其实来源于信息打印”,我细想了一下,说的确实有道理,于是我就重写了测试部分的代码。
但是不写不知道,一写吓一跳,删除了打印信息的代码之后,惊奇的发现,之前得出的“EntrySet 和 KeySet 性能相近”的结论是错误的,并且我也把 JMH 测试吞吐量的代码换成了平均执行时间,因为这样看起来更直观。而测试的结果是,EntrySet 和 KeySet 的性能相差在一倍以上,详见下文。
本文改动了两处内容:
- 去掉了测试代码中的打印信息,把测试类型从吞吐量测试改成了平均执行时间测试(这样看起来更直观);
- 新增了 EntrySet 和 KeySet 性能差别的原因分析。
备注:以上内容为更正后的完整文章。
随着 JDK 1.8 Streams API 的发布,使得 HashMap 拥有了更多的遍历的方式,但应该选择那种遍历方式?反而成了一个问题。
本文先从 HashMap 的遍历方法讲起,然后再从性能、原理以及安全性等方面,来分析 HashMap 各种遍历方式的优势与不足,本文主要内容如下图所示: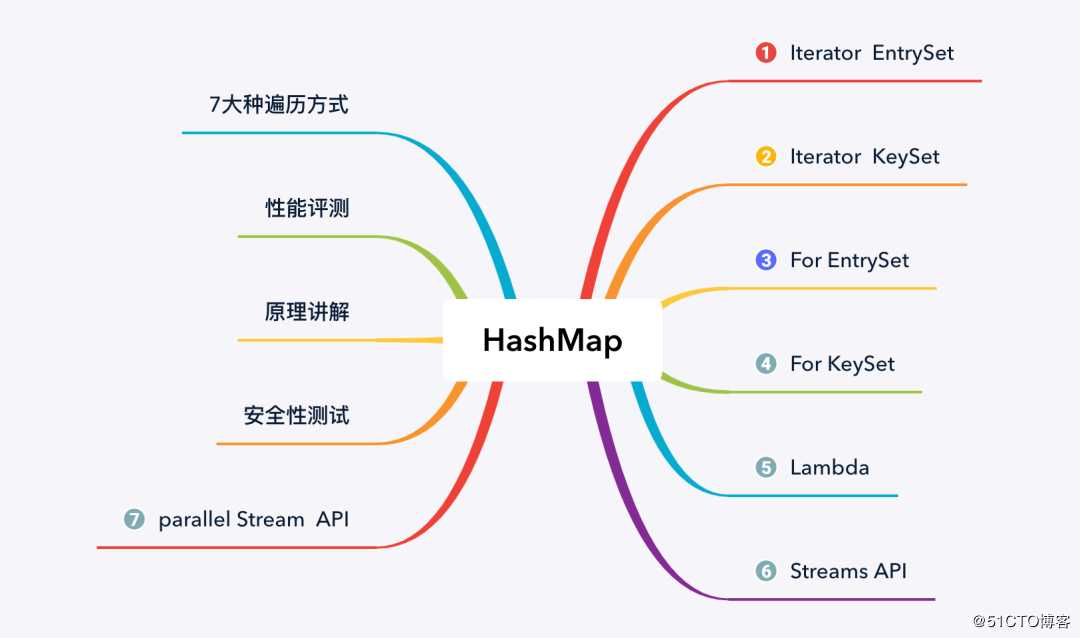
HashMap 遍历
HashMap 遍历从大的方向来说,可分为以下 4 类:
- 迭代器(Iterator)方式遍历;
- For Each 方式遍历;
- Lambda 表达式遍历(JDK 1.8+);
- Streams API 遍历(JDK 1.8+)。
但每种类型下又有不同的实现方式,因此具体的遍历方式又可以分为以下 7 种: - 使用迭代器(Iterator)EntrySet 的方式进行遍历;
- 使用迭代器(Iterator)KeySet 的方式进行遍历;
- 使用 For Each EntrySet 的方式进行遍历;
- 使用 For Each KeySet 的方式进行遍历;
- 使用 Lambda 表达式的方式进行遍历;
- 使用 Streams API 单线程的方式进行遍历;
- 使用 Streams API 多线程的方式进行遍历。
接下来我们来看每种遍历方式的具体实现代码。
1.迭代器 EntrySetpublic class HashMapTest { public static void main(String[] args) { // 创建并赋值 HashMap Map<Integer, String> map = new HashMap(); map.put(1, "Java"); map.put(2, "JDK"); map.put(3, "Spring Framework"); map.put(4, "MyBatis framework"); map.put(5, "Java中文社群"); // 遍历 Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<Integer, String> entry = iterator.next(); System.out.println(entry.getKey()); System.out.println(entry.getValue()); } } }以上程序的执行结果为:
1 Java 2 JDK 3 Spring Framework 4 MyBatis framework 5 Java中文社群 2.迭代器 KeySet public class HashMapTest { public static void main(String[] args) { // 创建并赋值 HashMap Map<Integer, String> map = new HashMap(); map.put(1, "Java"); map.put(2, "JDK"); map.put(3, "Spring Framework"); map.put(4, "MyBatis framework"); map.put(5, "Java中文社群"); // 遍历 Iterator<Integer> iterator = map.keySet().iterator(); while (iterator.hasNext()) { Integer key = iterator.next(); System.out.println(key); System.out.println(map.get(key)); } } }以上程序的执行结果为:
1 Java 2 JDK 3 Spring Framework 4 MyBatis framework 5 Java中文社群 3.ForEach EntrySet public class HashMapTest { public static void main(String[] args) { // 创建并赋值 HashMap Map<Integer, String> map = new HashMap(); map.put(1, "Java"); map.put(2, "JDK"); map.put(3, "Spring Framework"); map.put(4, "MyBatis framework"); map.put(5, "Java中文社群"); // 遍历 for (Map.Entry<Integer, String> entry : map.entrySet()) { System.out.println(entry.getKey()); System.out.println(entry.getValue()); } } }以上程序的执行结果为:
1 Java 2 JDK 3 Spring Framework 4 MyBatis framework 5 Java中文社群 4.ForEach KeySet public class HashMapTest { public static void main(String[] args) { // 创建并赋值 HashMap Map<Integer, String> map = new HashMap(); map.put(1, "Java"); map.put(2, "JDK"); map.put(3, "Spring Framework"); map.put(4, "MyBatis framework"); map.put(5, "Java中文社群"); // 遍历 for (Integer key : map.keySet()) { System.out.println(key); System.out.println(map.get(key)); } } }以上程序的执行结果为:
1 Java 2 JDK 3 Spring Framework 4 MyBatis framework 5 Java中文社群 5.Lambda public class HashMapTest { public static void main(String[] args) { // 创建并赋值 HashMap Map<Integer, String> map = new HashMap(); map.put(1, "Java"); map.put(2, "JDK"); map.put(3, "Spring Framework"); map.put(4, "MyBatis framework"); map.put(5, "Java中文社群"); // 遍历 map.forEach((key, value) -> { System.out.println(key); System.out.println(value); }); } }以上程序的执行结果为:
1
Java
2
JDK
3
Spring Framework
4
MyBatis framework
5
Java中文社群
6.Streams API 单线程
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
}
}以上程序的执行结果为: 1 Java 2 JDK 3 Spring Framework 4 MyBatis framework 5 Java中文社群 7.Streams API 多线程 public class HashMapTest { public static void main(String[] args) { // 创建并赋值 HashMap Map<Integer, String> map = new HashMap(); map.put(1, "Java"); map.put(2, "JDK"); map.put(3, "Spring Framework"); map.put(4, "MyBatis framework"); map.put(5, "Java中文社群"); // 遍历 map.entrySet().parallelStream().forEach((entry) -> { System.out.println(entry.getKey()); System.out.println(entry.getValue()); }); } }以上程序的执行结果为:
4 MyBatis framework 5 Java中文社群 1 Java 2 JDK 3 Spring Framework性能测试
接下来我们使用 Oracle 官方提供的性能测试工具 JMH(Java Microbenchmark Harness,JAVA 微基准测试套件)来测试一下这 7 种循环的性能。
首先,我们先要引入 JMH 框架,在 pom.xml 文件中添加如下配置:
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-core -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.23</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-generator-annprocess -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.23</version>
<scope>provided</scope>
</dependency>
然后编写测试代码,如下所示:
@BenchmarkMode(Mode.AverageTime) // 测试完成时间
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 2, time = 1, timeUnit = TimeUnit.SECONDS) // 预热 2 轮,每次 1s
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS) // 测试 5 轮,每次 1s
@Fork(1) // fork 1 个线程
@State(Scope.Thread) // 每个测试线程一个实例
public class HashMapCycleTest {
static Map<Integer, String> map = new HashMap() {{
// 添加数据
for (int i = 0; i < 100; i++) {
put(i, "val:" + i);
}
}};
public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
.include(HashMapCycle.class.getSimpleName()) // 要导入的测试类
.output("/Users/admin/Desktop/jmh-map.log") // 输出测试结果的文件
.build();
new Runner(opt).run(); // 执行测试
}
@Benchmark
public void entrySet() {
// 遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
Integer k = entry.getKey();
String v = entry.getValue();
}
}
@Benchmark
public void forEachEntrySet() {
// 遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
Integer k = entry.getKey();
String v = entry.getValue();
}
}
@Benchmark
public void keySet() {
// 遍历
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer k = iterator.next();
String v = map.get(k);
}
}
@Benchmark
public void forEachKeySet() {
// 遍历
for (Integer key : map.keySet()) {
Integer k = key;
String v = map.get(k);
}
}
@Benchmark
public void lambda() {
// 遍历
map.forEach((key, value) -> {
Integer k = key;
String v = value;
});
}
@Benchmark
public void streamApi() {
// 单线程遍历
map.entrySet().stream().forEach((entry) -> {
Integer k = entry.getKey();
String v = entry.getValue();
});
}
public void parallelStreamApi() {
// 多线程遍历
map.entrySet().parallelStream().forEach((entry) -> {
Integer k = entry.getKey();
String v = entry.getValue();
});
}
}所有被添加了 @Benchmark 注解的方法都会被测试,因为 parallelStream 为多线程版本性能一定是最好的,所以就不参与测试了,其他 6 个方法的测试结果如下:
其中 Units 为 ns/op 意思是执行完成时间(单位为纳秒),而 Score 列为平均执行时间, ± 符号表示误差。从以上结果可以看出,两个 entrySet 的性能相近,并且执行速度最快,接下来是 stream ,然后是两个 keySet,性能最差的是 KeySet 。注:以上结果基于测试环境:JDK 1.8 / Mac mini (2018) / Idea 2020.1
结论
从以上结果可以看出 entrySet 的性能比 keySet 的性能高出了一倍之多,因此我们应该尽量使用 entrySet 来实现 Map 集合的遍历。
字节码分析
要理解以上的测试结果,我们需要把所有遍历代码通过 javac 编译成字节码来看具体的原因。
编译后,我们使用 Idea 打开字节码,内容如下:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package com.example;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
public class HashMapTest {
static Map<Integer, String> map = new HashMap() {
{
for(int var1 = 0; var1 < 2; ++var1) {
this.put(var1, "val:" + var1);
}
}
};
public HashMapTest() {
}
public static void main(String[] var0) {
entrySet();
keySet();
forEachEntrySet();
forEachKeySet();
lambda();
streamApi();
parallelStreamApi();
}
public static void entrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey());
System.out.println((String)var1.getValue());
}
}
public static void keySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1);
System.out.println((String)map.get(var1));
}
}
public static void forEachEntrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey());
System.out.println((String)var1.getValue());
}
}
public static void forEachKeySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1);
System.out.println((String)map.get(var1));
}
}
public static void lambda() {
map.forEach((var0, var1) -> {
System.out.println(var0);
System.out.println(var1);
});
}
public static void streamApi() {
map.entrySet().stream().forEach((var0) -> {
System.out.println(var0.getKey());
System.out.println((String)var0.getValue());
});
}
public static void parallelStreamApi() {
map.entrySet().parallelStream().forEach((var0) -> {
System.out.println(var0.getKey());
System.out.println((String)var0.getValue());
});
}
}从结果可以看出,除了 Lambda 和 Streams API 之外,通过迭代器循环和 for 循环的遍历的 EntrySet 最终生成的代码是一样的,他们都是在循环中创建了一个遍历对象 Entry ,代码如下:
public static void entrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey());
System.out.println((String)var1.getValue());
}
}
public static void forEachEntrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey());
System.out.println((String)var1.getValue());
}
}
而 KeySet 的代码也是类似的,如下所示:
public static void keySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1);
System.out.println((String)map.get(var1));
}
}
public static void forEachKeySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1);
System.out.println((String)map.get(var1));
}
}所以我们在使用迭代器或是 for 循环 EntrySet 时,他们的性能都是相同的,因为他们最终生成的字节码基本都是一样的;同理 KeySet 的两种遍历方式也是类似的。
性能分析
EntrySet 之所以比 KeySet 的性能高是因为,KeySet 在循环时使用了 map.get(key),而 map.get(key) 相当于又遍历了一遍 Map 集合去查询 key 所对应的值。为什么要用“又”这个词?那是因为在使用迭代器或者 for 循环时,其实已经遍历了一遍 Map 集合了,因此再使用 map.get(key) 查询时,相当于遍历了两遍。
而 EntrySet 只遍历了一遍 Map 集合,之后通过代码“Entry<Integer, String> entry = iterator.next()”把对象的 key 和 value 值都放入到了 Entry 对象中,因此再获取 key 和 value 值时就无需再遍历 Map 集合,只需要从 Entry 对象中取值就可以了。
所以,EntrySet 的性能比 KeySet 的性能高出了一倍,因为 KeySet 相当于循环了两遍 Map 集合,而 EntrySet 只循环了一遍。
安全性测试
从上面的性能测试结果和原理分析,我想大家应该选用那种遍历方式,已经心中有数的,而接下来我们就从「安全」的角度入手,来分析那种遍历方式更安全。
我们把以上遍历划分为四类进行测试:迭代器方式、For 循环方式、Lambda 方式和 Stream 方式,测试代码如下。
1.迭代器方式
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
if (entry.getKey() == 1) {
// 删除
System.out.println("del:" + entry.getKey());
iterator.remove();
} else {
System.out.println("show:" + entry.getKey());
}
}以上程序的执行结果:
show:0
del:1
show:2测试结果:迭代器中循环删除数据安全。
2.For 循环方式
for (Map.Entry<Integer, String> entry : map.entrySet()) {
if (entry.getKey() == 1) {
// 删除
System.out.println("del:" + entry.getKey());
map.remove(entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
}以上程序的执行结果: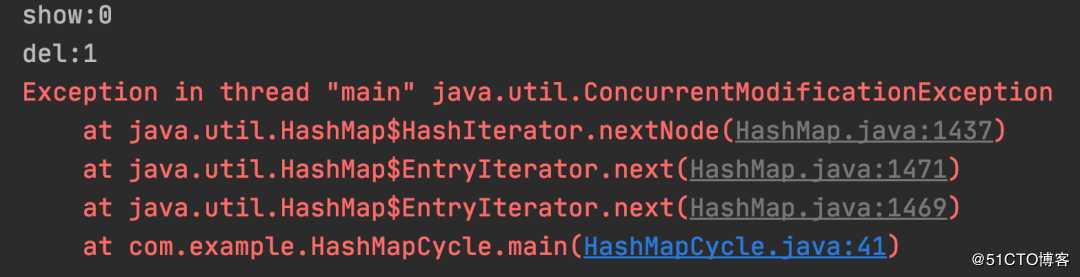
image.png
测试结果:For 循环中删除数据非安全。
3.Lambda 方式
map.forEach((key, value) -> {
if (key == 1) {
System.out.println("del:" + key);
map.remove(key);
} else {
System.out.println("show:" + key);
}
});以上程序的执行结果: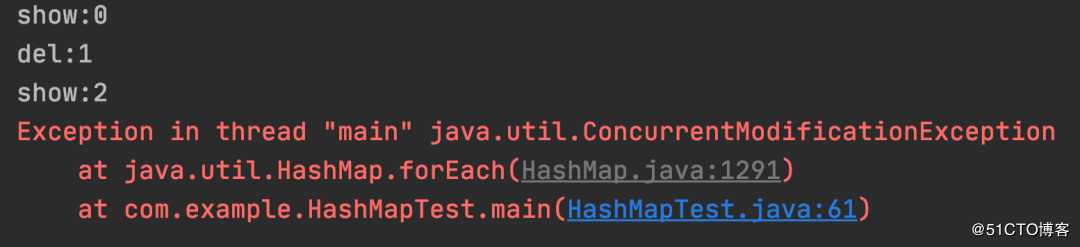
测试结果:Lambda 循环中删除数据非安全。
Lambda 删除的正确方式:
// 根据 map 中的 key 去判断删除
map.keySet().removeIf(key -> key == 1);
map.forEach((key, value) -> {
System.out.println("show:" + key);
});以上程序的执行结果:
show:0
show:2从上面的代码可以看出,可以先使用 Lambda 的 removeIf 删除多余的数据,再进行循环是一种正确操作集合的方式。
4.Stream 方式
map.entrySet().stream().forEach((entry) -> {
if (entry.getKey() == 1) {
System.out.println("del:" + entry.getKey());
map.remove(entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
});以上程序的执行结果: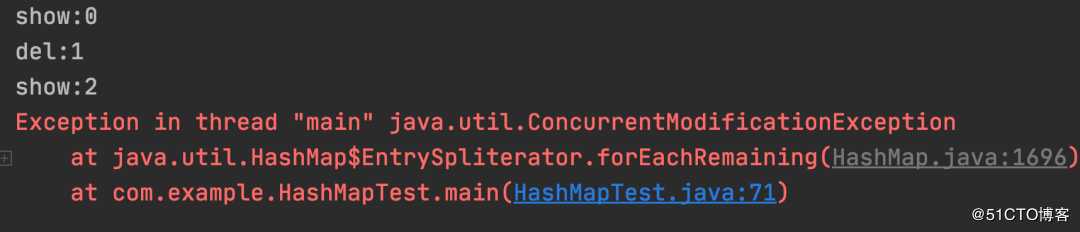
image.png
测试结果:Stream 循环中删除数据非安全。
Stream 循环的正确方式:
map.entrySet().stream().filter(m -> 1 != m.getKey()).forEach((entry) -> {
if (entry.getKey() == 1) {
System.out.println("del:" + entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
});以上程序的执行结果:
show:0
show:2从上面的代码可以看出,可以使用 Stream 中的 filter 过滤掉无用的数据,再进行遍历也是一种安全的操作集合的方式。
小结
我们不能在遍历中使用集合 map.remove() 来删除数据,这是非安全的操作方式,但我们可以使用迭代器的 iterator.remove() 的方法来删除数据,这是安全的删除集合的方式。同样的我们也可以使用 Lambda 中的 removeIf 来提前删除数据,或者是使用 Stream 中的 filter 过滤掉要删除的数据进行循环,这样都是安全的,当然我们也可以在 for 循环前删除数据在遍历也是线程安全的。
总结
本文我们讲了 HashMap 4 种遍历方式:迭代器、for、lambda、stream,以及具体的 7 种遍历方法,综合性能和安全性来看,我们应该尽量使用迭代器(Iterator)来遍历 EntrySet 的遍历方式来操作 Map 集合,这样就会既安全又高效了。
最后的话
知错能改善莫大焉,放下“面子”才是一个成年人最大的体面。
原创不易,如果觉得本文对你有用,请随手点击一个「赞」,这是对作者最大的支持与鼓励,谢谢你。
参考 & 鸣谢
https://www.javaguides.net/2020/03/5-best-ways-to-iterate-over-hashmap-in-java.html
String性能提升10倍的几个方法!(源码+原理分析)
9个小技巧让你的 if else看起来更优雅
关注公众号「Java中文社群」回复“干货”,获取原创干货 Top 榜。
以上是关于HashMap 的 7 种遍历方式与性能分析!「修正篇」的主要内容,如果未能解决你的问题,请参考以下文章