干货 | Logstash Grok数据结构化ETL实战
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 | Logstash Grok数据结构化ETL实战相关的知识,希望对你有一定的参考价值。
0、题记
日志分析是ELK最常用、最核心业务场景之一。
如果你正在使用Elastic Stack并且正尝试将自定义Logstash日志映射到Elasticsearch,那么这篇文章适合你。
Logstash写入ES之前的中间数据处理过程一般叫做:数据ETL或者数据清洗。
本文重点介绍数据清洗环节的非结构数据转化为结构化数据的——Grok实现。
1、认知前提
老生常谈,夯实基础认知。
ELK Stack是三个开源项目的首字母缩写:Elasticsearch,Logstash和Kibana。 它们可以共同构成一个日志管理平台。
Elasticsearch:搜索和分析引擎。
Logstash:服务器端数据处理管道,它同时从多个源中提取数据,对其进行转换,然后将其发送到Elasticsearch存储。
Kibana:图表和图形来可视化数据ES中数据。
Beats后来出现,是一个轻量级的数据传输带(data shipper)。 Beats的引入将ELK Stack转换为Elastic Stack。

2、啥是Grok?
Grok是Logstash中的过滤器,用于将非结构化数据解析为结构化和可查询的数据。
它位于正则表达式之上,并使用文本模式匹配日志文件中的行。
下文分析你会看到,使用Grok在有效的日志管理方面大有裨益!
一图胜千言。
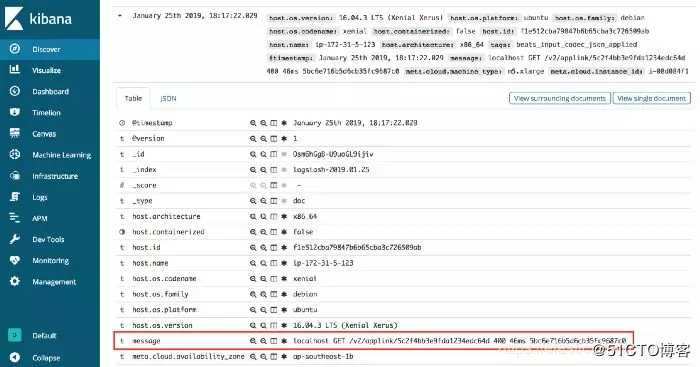
如果没有Grok,当日志从Logstash发送到Elasticsearch并在Kibana中呈现时,它只会出现在消息值中。
在这种情况下,查询有意义的信息很困难,因为所有日志数据都存储在一个key中。
白话文——Grok的目的:将如上一个key对应的一长串非结构的Value,转成多个结构化的Key对应多个结构化的Value。
3、日志数据非结构化 VS 结构化
3.1 非结构化原始日志数据
1localhost GET / v2 / applink / 5c2f4bb3e9fda1234edc64d 400 46ms 5bc6e716b5d6cb35fc9687c0
如果仔细查看原始数据,可以看到它实际上由不同的部分组成,每个部分用空格分隔符分隔。
对于更有经验的开发人员,您可以猜测每个部分的含义,以及来自API调用的日志消息。
从数据分析的角度:非结构化数据不便于检索、统计、分析。
3.2 结构化日志数据
1localhost == environment (基础环境信息)
2GET == method (请求方式)
3/v2/applink/5c2f4bb3e9fda1234edc64d == url (URL地址)
4400 == response_status (响应状态码)
546ms == response_time (响应时间)
65bc6e716b5d6cb35fc9687c0 == user_id (用户Id)
如上切分的中间转换正是借助grok实现。非结构化数据变成结构化数据后才凸显价值,检索、统计、分析等都变得非常简单了。
4、Grok模式
4.1 内置模式
Logstash提供了超过100种内置模式,用于解析非结构化数据。
对于常见的系统日志,如apache,linux,haproxy,aws等,内置模式是刚需+标配。
但是,当您拥有自定义日志时会发生什么? 必须构建自己的自定义Grok模式。
4.2 自定义模式
构建自己的自定义Grok模式需要反复试验。 推荐使用Grok Debugger和Grok Patterns做验证。
Grok Debugger地址:https://grokdebug.herokuapp.com/ ,注意:需要***。
Grok Patterns地址:https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
请注意,Grok模式的语法是:%{SYNTAX:SEMANTIC}
实践一把:
步骤1:进入Grok Debugger中的Discover选项卡。
期望这个工具可以自动生成Grok模式,但它没有太大帮助,因为它只发现了如下两个匹配。
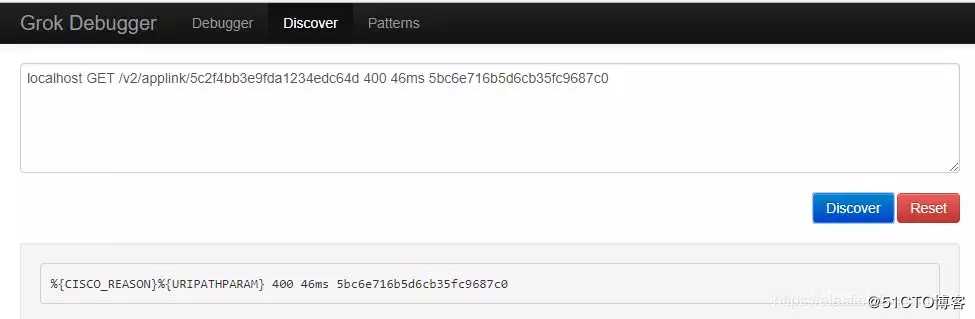
在这里插入图片描述
步骤2:借助Elastic的github上的语法在Grok Debugger上构建模式。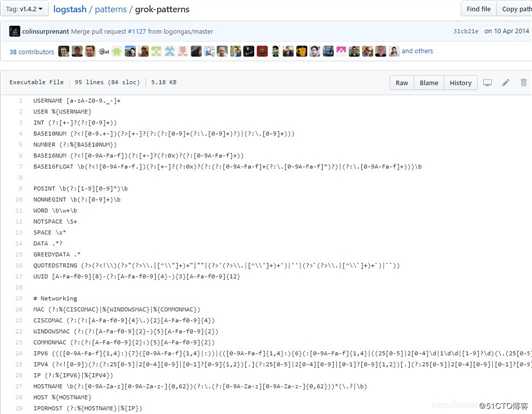
在这里插入图片描述
步骤3:Grok Debugger实操验证。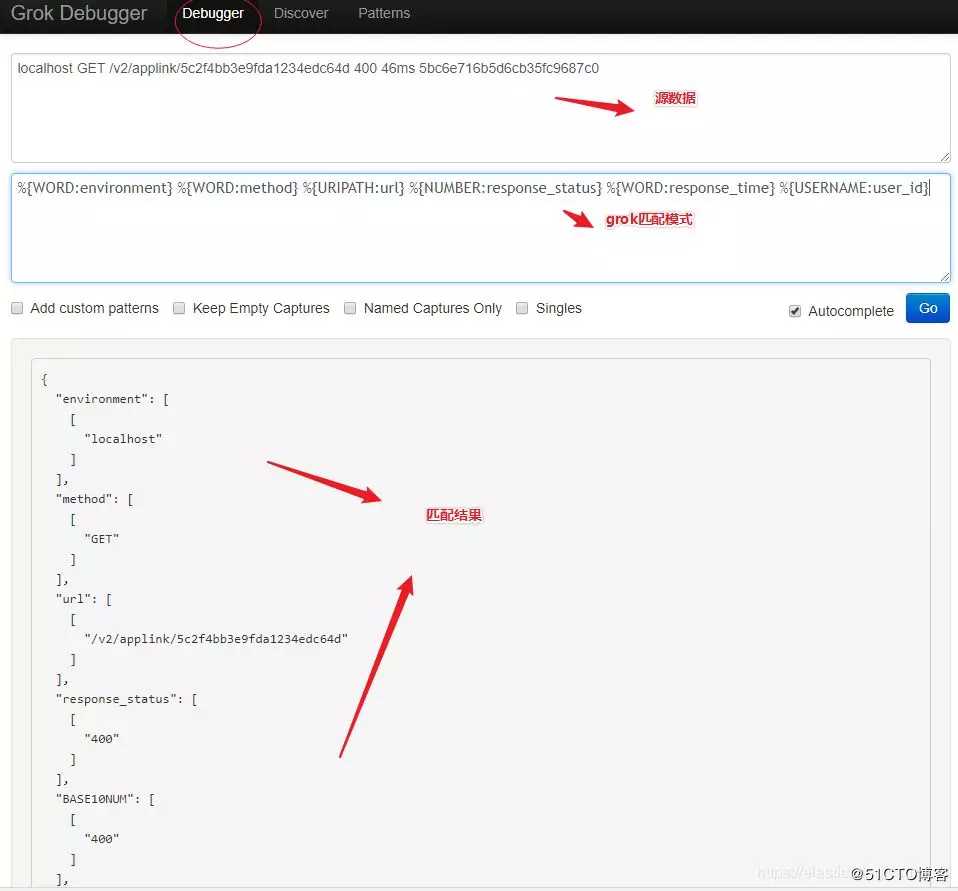
如上截图:
输入待匹配的源非结构化数据:
1localhost GET /v2/applink/5c2f4bb3e9fda1234edc64d 400 46ms 5bc6e716b5d6cb35fc9687c0
输入匹配模式:
1%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}
输出结构化数据解析后匹配结果:
1{
2 "environment": [
3 [
4 "localhost"
5 ]
6 ],
7 "method": [
8 [
9 "GET"
10 ]
11 ],
12 "url": [
13 [
14 "/v2/applink/5c2f4bb3e9fda1234edc64d"
15 ]
16 ],
17 "response_status": [
18 [
19 "400"
20 ]
21 ],
22 "BASE10NUM": [
23 [
24 "400"
25 ]
26 ],
27 "response_time": [
28 [
29 "46ms"
30 ]
31 ],
32 "user_id": [
33 [
34 "5bc6e716b5d6cb35fc9687c0"
35 ]
36 ]
37}
在使用不同的语法后,终于能够以期望的方式构建日志数据。
5、grok集成到Logstash filter环节验证
步骤1:切换路径。
在安装ELK Stack的服务器上,切换到Logstash配置。
1sudo vi /etc/logstash/conf.d/logstash.conf
步骤2:拷贝核心Grok配置, 更新Logstash.conf。
将验证后的grok部分贴过来。
注意:核心三段论结构。
1、输入:日志路径;
2、中间处理ETL:grok解析
3、输出:ES。
1input {
2 file {
3 path => "/your_logs/*.log"
4 }
5}
6filter{
7 grok {
8 match => { "message" => "%{WORD:environment} %{WORD:method} %{URIPATH:url} %{NUMBER:response_status} %{WORD:response_time} %{USERNAME:user_id}"}
9 }
10}
11output {
12 elasticsearch {
13 hosts => [ "localhost:9200" ]
14 }
15}
步骤3:重启。
保存更改后,重新启动Logstash并检查其状态以确保它仍然有效。
1sudo service logstash restart
2sudo service logstash status
6、Kibana可视化验证
最后,为了确保更改生效,请务必刷新Kibana中Logstash写入的Elasticsearch索引!
结论如下图所示:使用Grok,您的日志数据是结构化的!
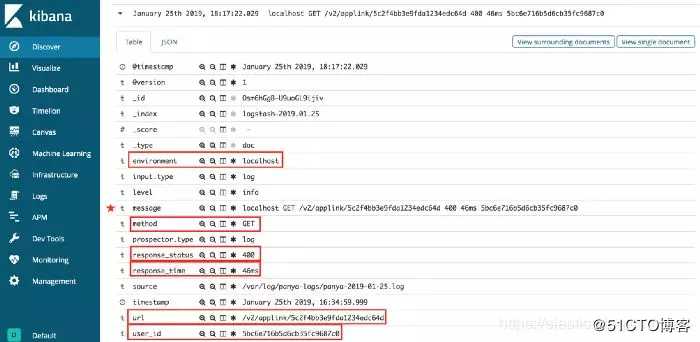
Grok能够自动将日志数据映射到Elasticsearch。这样可以更轻松地管理日志并快速实现查询、统计、分析操作。
7、小结
这是一篇翻译文章。当近期在尝试写类似解析文章的时候,发现国外已经有讲解的非常透彻的文章。
因此,在原文基础上做了实践验证和通俗化的解读,希望对你有帮助。
划重点:Grok Debugger和Grok Patterns工具的使用,会事半功倍,极大提高开发效率,避免不必要的“黑暗中摸索”。
以上是关于干货 | Logstash Grok数据结构化ETL实战的主要内容,如果未能解决你的问题,请参考以下文章