Logstash: Grok 模式示例
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Logstash: Grok 模式示例相关的知识,希望对你有一定的参考价值。
Logstash 可以轻松解析 CSV 和 JSON 文件,因为这些格式的数据组织得很好,可以进行 Elasticsearch 分析。 但是,有时我们需要处理非结构化数据,例如纯文本日志。 在这些情况下,我们需要使用 Logstash Grok 或其他第三方服务解析数据以使其成为结构化数据。 本教程将通过使用 Logstash Grok 进行解析,帮助你利用 Elasticsearch 的分析和查询功能。
因此,让我们深入了解如何使用 Logstash Grok 过滤器处理非结构化数据。
理论
在 CSV 文件中,每条记录都有相同的字段列表。 这些字段的顺序可预测地重复,以便任何程序以结构化方式读取。 自然,这对于 Elasticsearch 来说是一个理想的情况。
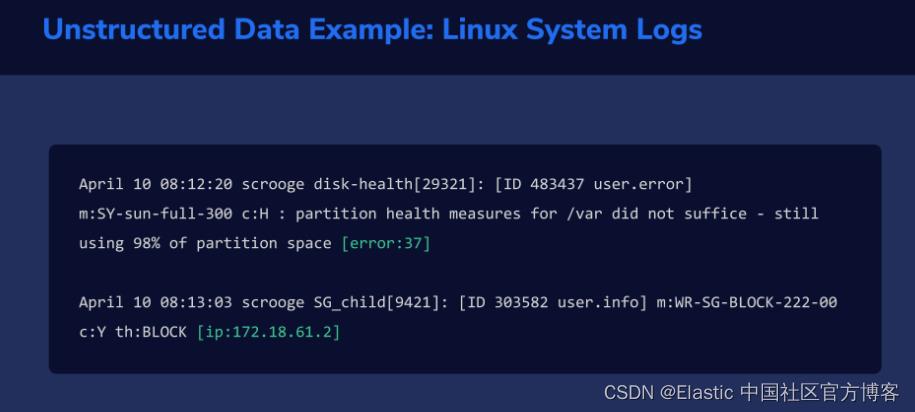
在其他情况下,无法以这种理想方式组织信息。 考虑一个典型的 Linux 系统日志。 多个程序将它们的状态或错误消息写入同一个日志文件。 在日志的一行中,最后一个字段可能是错误代码。 但在下一行,最后一个字段可能是 IP 地址。 这意味着解析器现在需要有一种方法来 “检测” 每个字段所代表的内容。 让我们看看 Grok 过滤器是如何做到这一点的。
理解 Grok 模式和语法:
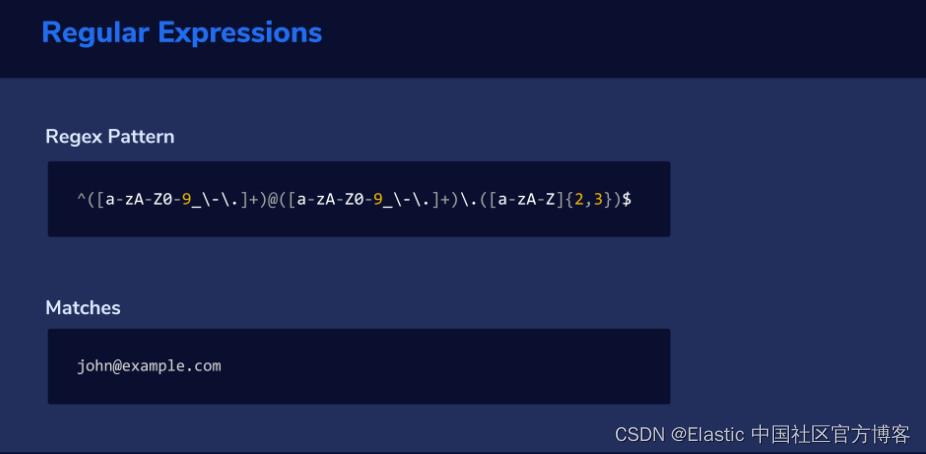
当我们看到 john@example.com 之类的内容时,我们会立即想到 电子邮件地址,因为我们已经学会了识别这种模式。 Grok 可以通过分析每段文本并检查它是否与你指示它查找的模式匹配来做同样的事情。
Grok 在幕后使用正则表达式,或简称 regex,这对于还不熟悉它们的人来说可能看起来有点奇怪。 例如,匹配电子邮件的正则表达式如下所示:
^([a-zA-Z0-9_\\-\\.]+)@([a-zA-Z0-9_\\-\\.]+)\\.([a-zA-Z]2,3)$幸运的是,在 Logstash 的 Grok 过滤器中已经预定义了很多常用表达式,我们可以使用它们的模式名称来代替自己编写那些复杂的字符串。你可以在地址查看:Grok filter plugin | Logstash Reference [8.4] | Elastic。
我们可以在 Grok 过滤器插件的文档页面上找到这些预定义模式名称的列表。Grok 模式的基本语法为:%SYNTAX:SEMANTIC。
简而言之,我们告诉它要寻找什么模式以及如何标记与这些模式匹配的字符串。

回到我们之前的示例,这是定义和标记电子邮件地址的方法:
%EMAILADDRESS:client_email此 Grok 模式将查找所有电子邮件地址并将每个地址标识为 client_email。 你可以自由选择您想要的任何标识符名称。
在我们的例子中,标识符将用作匹配值的字段名称,这些匹配值将被导入到索引中。 我们将在接下来的动手练习中看到它是如何工作的。
示例 Grok 过滤器:

让我们分析一下我们将如何使用 Grok。 考虑日志文件中的以下行:
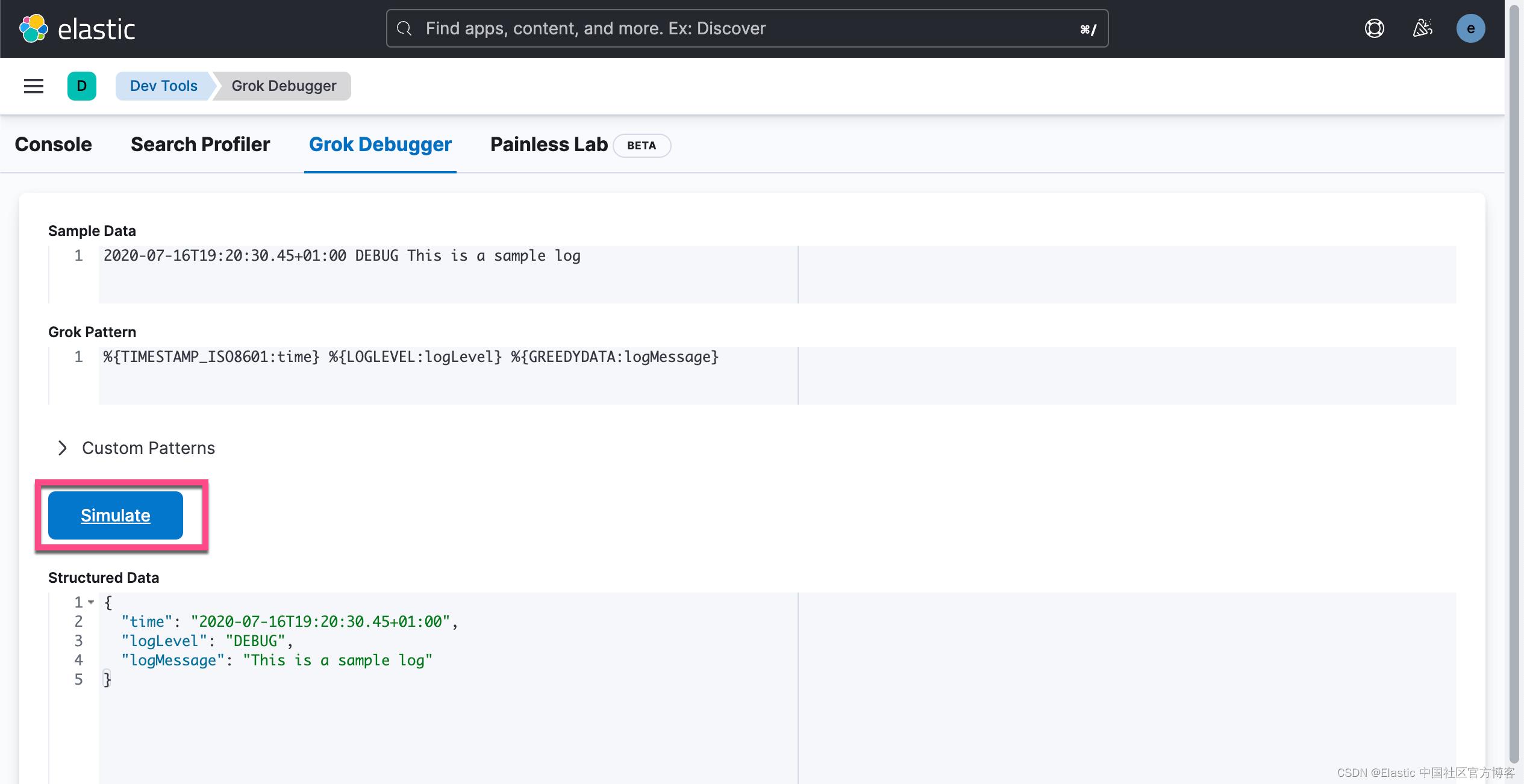
2020-07-16T19:20:30.45+01:00 DEBUG This is a sample log我们可以看到这里有三个逻辑组件:时间戳,然后是日志记录级别,最后是错误或状态消息。时间戳采用所谓的 ISO 格式,这很有用,因为我们已经有一个可用的 Grok 模式。那么,我们如何定义一个 Grok 过滤器来从这段日志文本中提取三个组件?

好吧,这里是:
%TIMESTAMP_ISO8601:time %LOGLEVEL:logLevel %GREEDYDATA:logMessageTIMESTAMP_ISO8601 和 LOGLEVEL 从我们的示例日志文本中提取前两部分。 GREEDYDATA 可能听起来很神秘,但它所做的只是匹配所分析字符串中的所有其他字符,因此它会提取文本的其余部分。
自然地,我们也想测试这些 Grok 过滤器,看看它们是否按预期工作,在我们的特定数据上。我们可以使用 Kibana 自带的 Grok Debugger,或者你可以使用网上的 Grok Debugger tool。我们现在以 Grok Debugger 为例来进行展示。
现在我们已经建立了一些 Grok 基础知识,让我们使用各种示例来探索这些概念。
动手练习
在今天的练习中,我们以最新的 Elastic Stack 8.4.3 为例进行展示。如果你还没有安装好自己的 Elastic Stack,请参考如下的文章:
在安装时,请选择 Elastic Stack 8.x 的安装。在默认的情况下,Elasticsearch 的访问是带有 HTTPS 的。
使用 Grok 解析一个日志文件
让我们应用这些新获得的知识,看看如何在示例日志文件中使用 Logstash Grok 过滤器插件。
首先,让我们创建一个目录来存储我们的示例数据:
mkdir -p $HOME/data/logstash你需要根据自己的 HOME 目录修改上面的路径。接下来,让我们创建我们将解析的文件:
$ pwd
/Users/liuxg/data/logstash
$ vi sample.log现在让我们将以下文本复制并粘贴到 vi 编辑器中:
2020-10-11T09:49:35Z INFO variable server value is tomcat
2020-03-14T22:50:34Z ERROR cannot find the requested resource
2020-01-02T14:58:40Z INFO initializing the bootup
2020-06-04T06:56:04Z DEBUG initializing checksum
2020-05-07T03:07:11Z INFO variable server value is tomcat我们保存好 sample.log 文件。我们可以使用如下的命令来进行查看:
$ pwd
/Users/liuxg/data/logstash
$ cat sample.log
2020-10-11T09:49:35Z INFO variable server value is tomcat
2020-03-14T22:50:34Z ERROR cannot find the requested resource
2020-01-02T14:58:40Z INFO initializing the bootup
2020-06-04T06:56:04Z DEBUG initializing checksum
2020-05-07T03:07:11Z INFO variable server value is tomcat接下来,我们来创建一个 Logstash 的配置文件 grok-example.conf。它的内容如下:
grok-example.conf
input
file
path => "/Users/liuxg/data/logstash/sample.log"
start_position => "beginning"
sincedb_path => "/dev/null"
filter
grok
match => "message" => ['%TIMESTAMP_ISO8601:time %LOGLEVEL:logLevel %GREEDYDATA:logMessage']
output
stdout
正如一个典型的 Logstash pipeline,它由一个 input,filter 及 output 组成:

我们可以看到过滤器部分下的配置非常简单。 我们指示 Logstash 使用 grok 过滤器插件,并在我们使用之前探索的相同模式和标识符的地方添加匹配指令。
"message" => ['%TIMESTAMP_ISO8601:time %LOGLEVEL:logLevel %GREEDYDATA:logMessage']我们使用如下的命令来运行这个 pipeline:
./bin/logstash -f /Users/liuxg/data/logstash/grok-example.conf
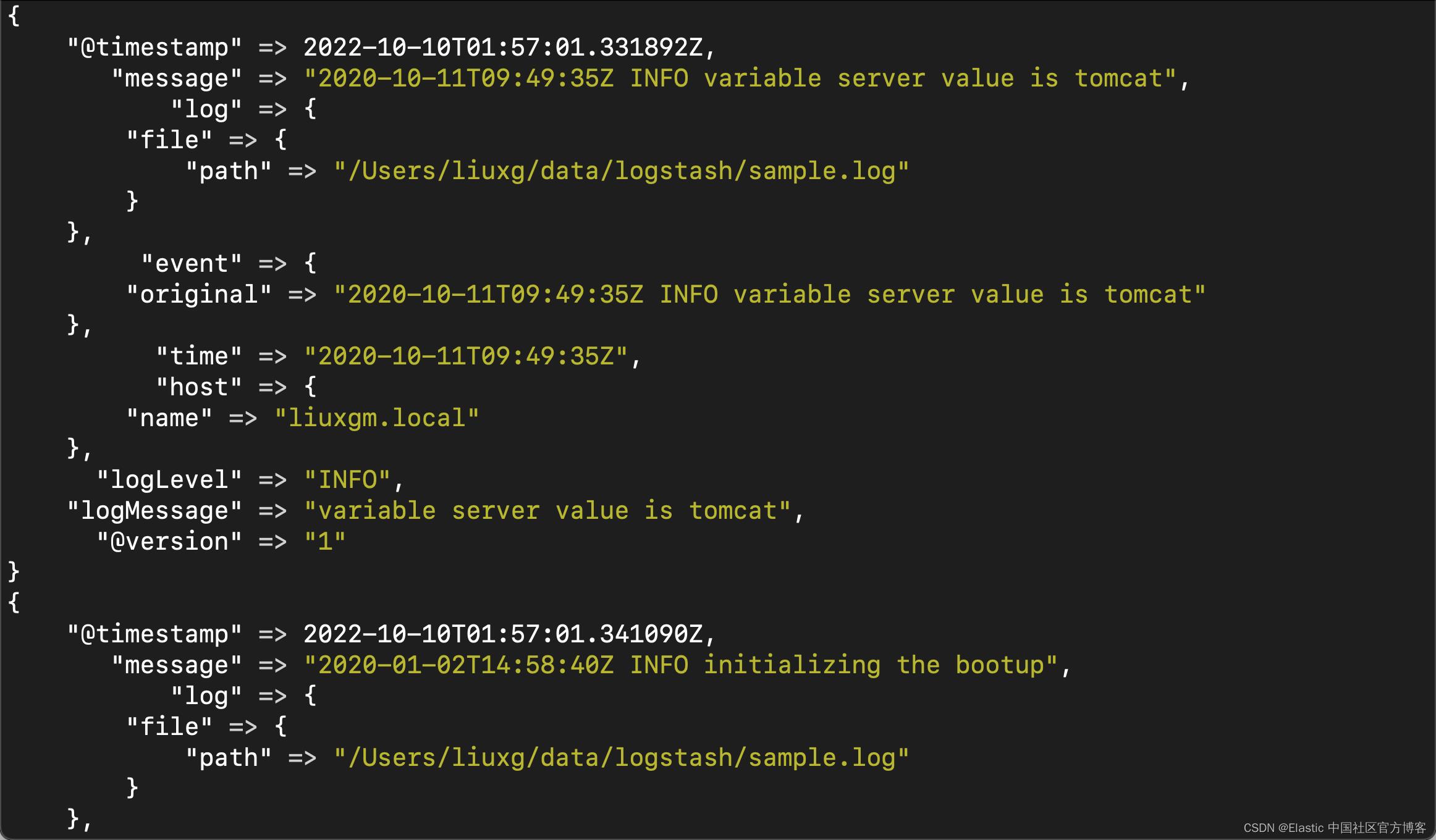
从上面的输入中,我们可以清楚地看到非结构化的文档,现在已经变成了结构化的文档。我们可以充分利用 Elasticsearch 的数据分析能力对数据进行分析和制作仪表盘。
如何把数据写入到 Elasticsearch
为了把数据写入到 Elasticsearch,我们需要做一些额外的工作,这是因为 Elasticsearch 的访问是 HTTPS 的。我们参考文章 “Logstash:如何连接到带有 HTTPS 访问的集群”。我们进入到 Elasticsearch 的安装目录中,并打入如下的命令:
keytool -import -file http_ca.crt -keystore truststore.p12 -storepass password -noprompt -storetype pkcs12$ pwd
/Users/liuxg/test/elasticsearch-8.4.3/config/certs
$ ls
http.p12 http_ca.crt transport.p12
$ keytool -import -file http_ca.crt -keystore truststore.p12 -storepass password -noprompt -storetype pkcs12
Certificate was added to keystore
$ ls
http.p12 http_ca.crt transport.p12 truststore.p12在上面的命令中,我们生成了一个叫做 truststore.p12 的文件,而访问它的密码是 password。
我们进一步修改 grok-example.conf 文件如下:
grok-example.conf
input
file
path => "/Users/liuxg/data/logstash/sample.log"
start_position => "beginning"
sincedb_path => "/dev/null"
filter
grok
match => "message" => ['%TIMESTAMP_ISO8601:time %LOGLEVEL:logLevel %GREEDYDATA:logMessage']
output
stdout
elasticsearch
hosts => ["https://localhost:9200"]
index => "data-%+YYYY.MM.dd"
user => "elastic"
password => "6bTlJp388KkgJKWi+hQr"
ssl_certificate_verification => true
truststore => "/Users/liuxg/test/elasticsearch-8.4.3/config/certs/truststore.p12"
truststore_password => "password"
在上面,我们添加了 elasticsearch 输出。特别需要注意的是,我们需要根据自己的配置修改上面的 password 部分。为了说明问题的方便,我使用了超级用户 elastic 来做展示。在实际的使用中,这个是一个不好的建议。你需要根据自己的需求创建适合数据采集的用户及密码。我们重新运行 Logstash:
./bin/logstash -f /Users/liuxg/data/logstash/grok-example.conf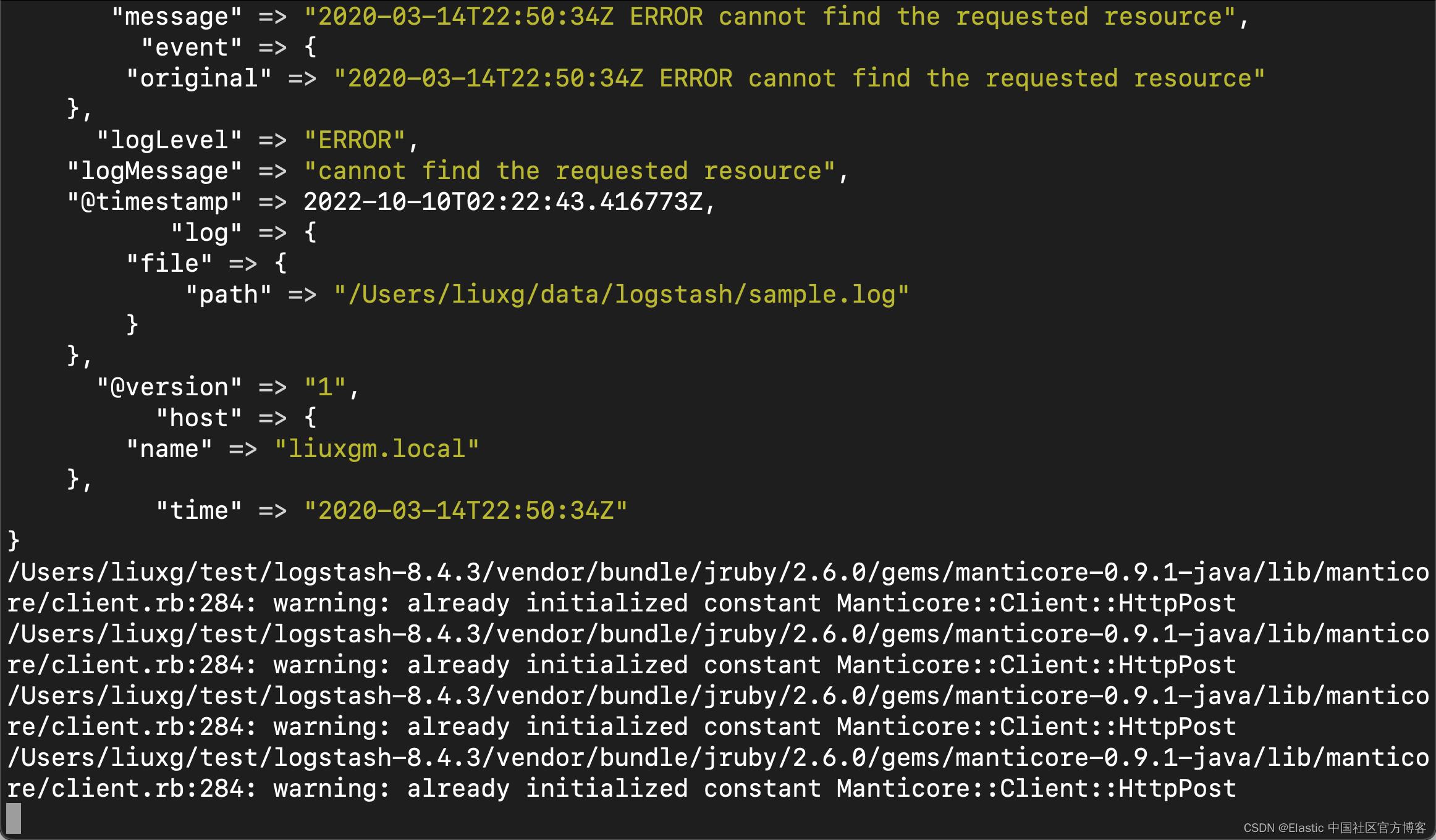
从上面的输出中,我能可以看出来数据解析是成功的。我们回到 Kibana 的界面,并打入如下的命令:
GET _cat/indices
我们可以看到一个以 data 开始的索引已经被生成了。我们使用如下的命令来查看它的文档数:
GET data-2022.10.10/_count
"count": 5,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
上面显示有 5 个文档。我们可以对它进行搜索:
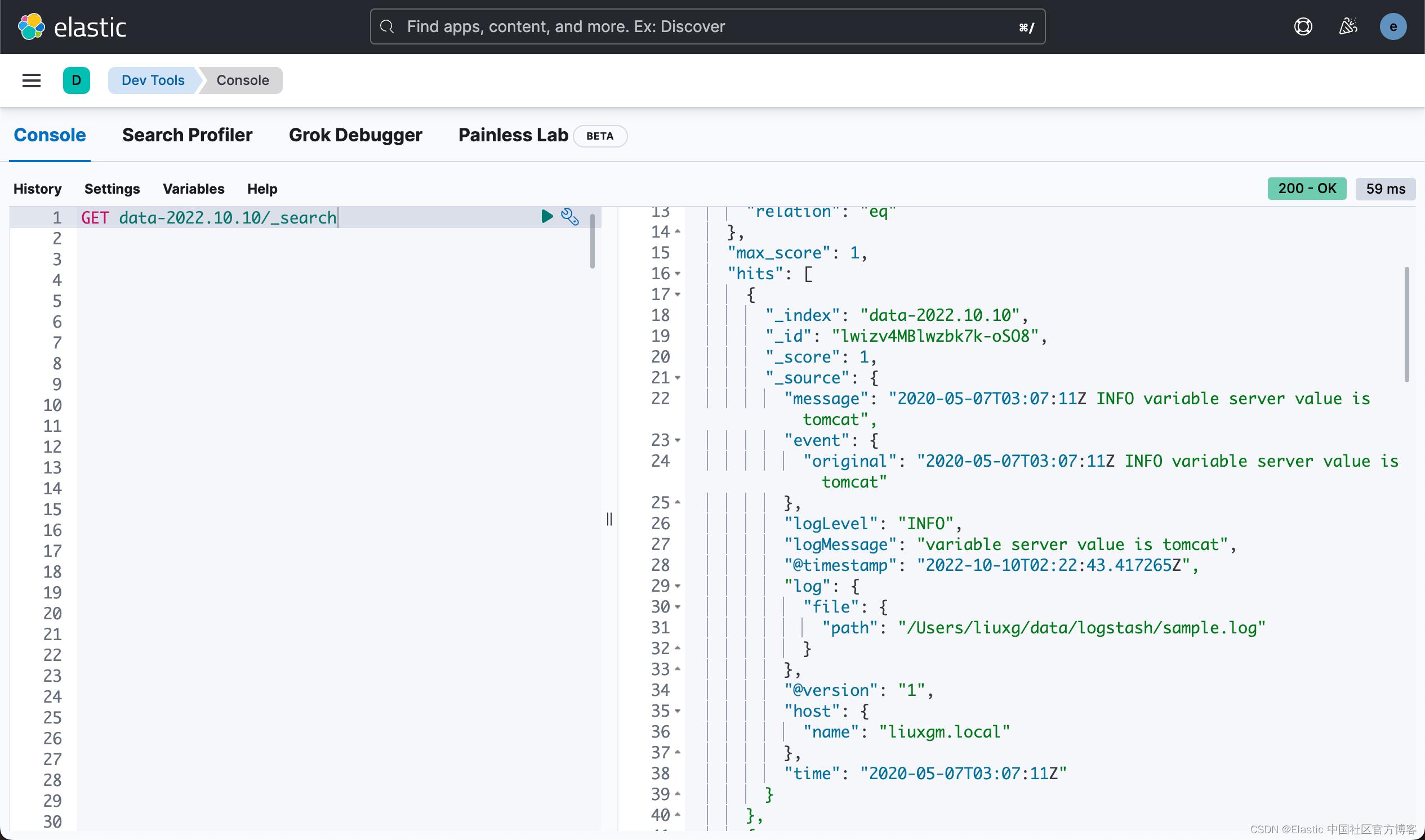
很显然,我们的文档被成功地摄入到 Elasticsearch 中了。
假如我们的文档中有不完全匹配 Grok 模式的,那么会发生什么情况呢?我们首先在 Kibana 中使用如下的命令来删除之前已经创建的索引:
DELETE data-2022.10.10我们在之前的 sample.log 文件的最后添加如下的一个新的行:
55.12.32.134 GET /user/id/properties$ pwd
/Users/liuxg/data/logstash
$ cat sample.log
2020-10-11T09:49:35Z INFO variable server value is tomcat
2020-03-14T22:50:34Z ERROR cannot find the requested resource
2020-01-02T14:58:40Z INFO initializing the bootup
2020-06-04T06:56:04Z DEBUG initializing checksum
2020-05-07T03:07:11Z INFO variable server value is tomcat
55.12.32.134 GET /user/id/properties很显然,它的格式和我们之前的行不一样。它的第一个部分不是时间戳。我们重新运行 Logstash:
./bin/logstash -f /Users/liuxg/data/logstash/grok-example.conf
我们可以看到该文档缺少 time、logLevel 和 logMessage 字段。 message 字段显示了我们的示例日志中生成此文档的行。 我们可以看到这是没有任何字段与我们的 Grok 过滤器模式匹配的行。 添加了一个名为 _grokparsefailure 的标记,以表明解析器在文件中的这一行出现问题。
以上是关于Logstash: Grok 模式示例的主要内容,如果未能解决你的问题,请参考以下文章