项目:可视化分析(后端爬取数据部分)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了项目:可视化分析(后端爬取数据部分)相关的知识,希望对你有一定的参考价值。
一:项目介绍
可视化分析项目是一个将唐诗三百首的详细内容录入到mysql,再实现一个简单的前端页面将数据以图表的形式展现出来,方便用户直观感受每个作者的诗词创作数量,和所使用频繁的词语构成的词云图等。
二:项目构思
项目主要分为两大部分
- 后端爬取唐诗数据录入数据库部分
- 提取数据库信息并通过前端网页绘图展现
我们需要爬取的数据信息来自:
原因:唐诗三百首这个网站不收费,公开的。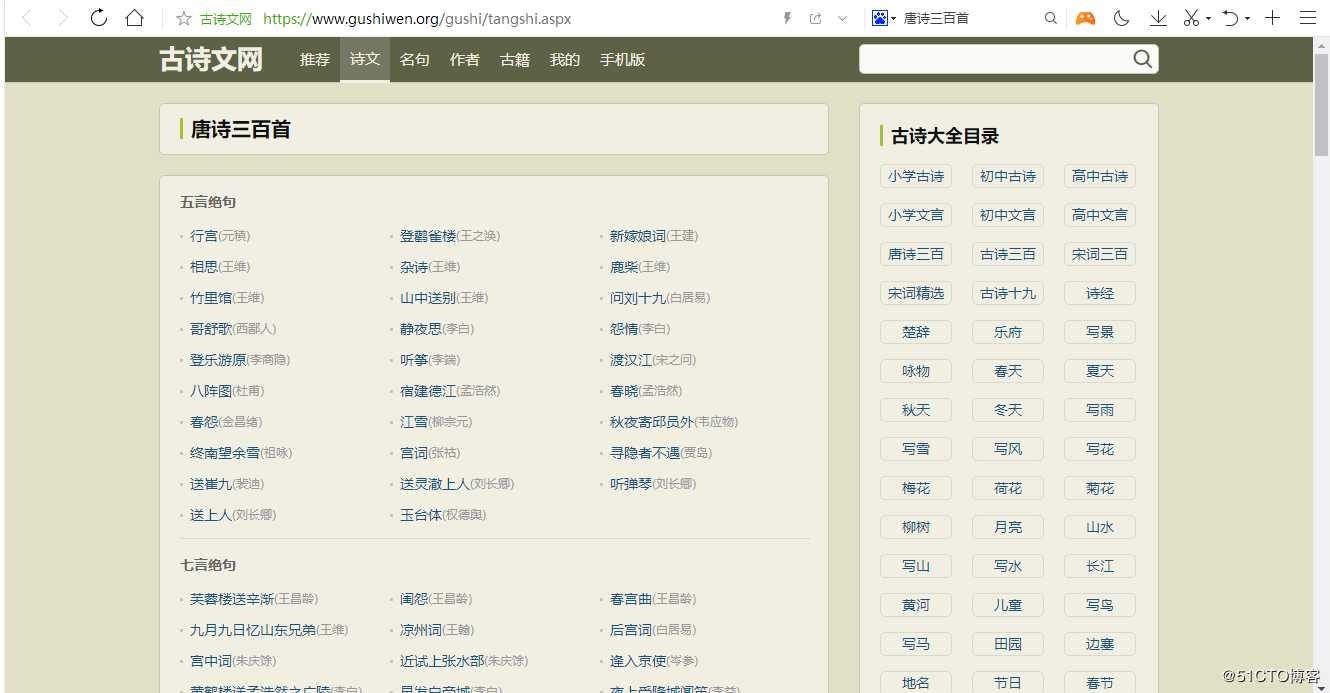
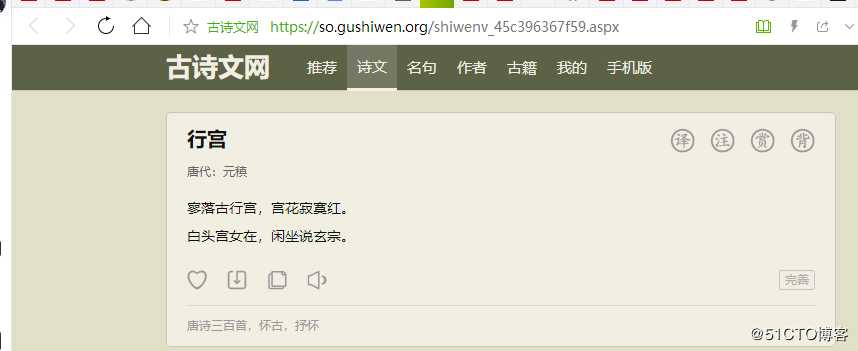
思考:我们如何将这一首首诗的标题,朝代,作者,正文等信息存入到MySQL中?
1.获取列表页的html文档,通过运用htmlunit第三方库中的方法获取每首诗的url.
2.分析详情页,通过Xpath获取每首诗的标题,朝代,作者,正文。
3.使用Java原生加密类MessageDigest类中的SHA-256算法防止数据重复录入数据库。
4.使用ansj-seg第三方库中的NlpAnalysis类的parse(),来计算分词,为前端网页展现词云图做铺垫。
5.使用JDBC 将数据入库。
预研阶段及技术选型:
- HtmlUnit(网页爬取)
HtmlUnit第三方库自带http client,可以帮助我们访问服务器资源,实现html页面的请求+解析。这个库下有一些方法getElementsByAttribute(),getAttribute(),getElementsByATagName()帮助我们解析解析html文档。 - ansi_seg(分词)
ansj-seg第三方库中的NlpAnalysis类的方法parse(),来计算分词。 - MySQL(数据库)
这是一个轻量级的数据库,操作方便,且支持SQL语句,我们可以作为客户端很方便得存储,管理以及访问数据。 - maven(构建软件)
在一个项目的开发过程中需要用到很多第三方库。而maven可以帮助我们编译代码,从maven 仓库自动下载安装所需的第三方库以及别人写好的jar包。熟悉技术使用:
我们在正式编写代码之前先写一些小Demo,使得我们快速熟悉方法的使用。
- HtmlUnit的小Demo
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
// ***面的浏览器(HTTP 客户端)
WebClient webClient = new WebClient(BrowserVersion.CHROME);//声明了一个浏览器对象 http客户端
// 关闭了浏览器的 js 执行引擎,不再执行网页中的 js 脚本
webClient.getOptions().setjavascriptEnabled(false);
// 关闭了浏览器的 css 执行引擎,不再执行网页中的 css 布局
webClient.getOptions().setCssEnabled(false);
HtmlPage page=webClient.getPage("https://so.gushiwen.org/gushi/tangshi.aspx");
//请求网页 请求列表页
//得到HTMLpage对象
System.out.println(page);// HtmlPage(https://so.gushiwen.org/gushi/tangshi.aspx)@1424108509
File file = new File("唐诗三百首\列表页.html");//里面有一首首诗的url
file.delete();
page.save(file);//将得到的东西保存在列表页文件里
// 如何从 html 中提取我们需要的信息
HtmlElement body = page.getBody();
List<HtmlElement> elements = body.getElementsByAttribute(
"div",
"class",//attributeName
"typecont");//得到【五言绝句,七言律诗,五言律诗。。。】
/*
for (HtmlElement element : elements) {
System.out.println(element);
}
*/
HtmlElement divElement = elements.get(0);//取第一个元素:五言绝句
List<HtmlElement> aElements = divElement.getElementsByAttribute("a", "target", "_blank");
for (HtmlElement e : aElements) {
System.out.println(e);
}
System.out.println(aElements.size());
System.out.println(aElements.get(0).getAttribute("href"));//五言绝句中的第一首诗 行宫
}
}关键方法解释:
1.getElementsByAttribute("elementName","attributeName","attributeValue")
此方法返回的是一个list,会返回所有"class"=typecont"的元素。
[{五言绝句},{七言律诗},{五言律诗}...]
2.getAttribute("attributeName")
此方法返回的是一个list,会返回所有标签为"href"的元素。
- Xpath元素定位小Demo
public class 详情页下载提取Demo {
public static void main(String[] args) throws IOException {
//try(){} 结束之后会自动调用wenclient.close()
try (WebClient webClient = new WebClient(BrowserVersion.CHROME)) {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
String url = "https://so.gushiwen.org/shiwenv_45c396367f59.aspx";//行宫 的url
HtmlPage page = webClient.getPage(url);//请求详情页
HtmlElement body = page.getBody();
/*
List<HtmlElement> elements = body.getElementsByAttribute(
"div",
"class",
"contson"
);//会把所有这样的标签都拿出来。包括三首猜你喜欢
for (HtmlElement element : elements) {//四首诗
System.out.println(element); //每首诗的div class id
}
System.out.println(elements.get(0).getTextContent().trim());//打印第一首诗的内容
*/ //获取它的正文信息
// 标题
{
String xpath = "//div[@class=‘cont‘]/h1/text()";
Object o = body.getByXPath(xpath).get(0);//会拿出所有这样的。所以需get(0) 纸打印第一首诗
DomText domText = (DomText)o;//document object model
System.out.println(domText.asText());
}
//朝代
{
String xpath = "//div[@class=‘cont‘]/p[@class=‘source‘]/a[1]/text()";//第一个a标签
Object o = body.getByXPath(xpath).get(0);
DomText domText = (DomText)o;
System.out.println(domText.asText());
}
//作者
{
String xpath = "//div[@class=‘cont‘]/p[@class=‘source‘]/a[2]/text()";
Object o = body.getByXPath(xpath).get(0);
DomText domText = (DomText)o;
System.out.println(domText.asText());
}
//正文
{
String xpath = "//div[@class=‘cont‘]/div[@class=‘contson‘]";
Object o = body.getByXPath(xpath).get(0);
HtmlElement element = (HtmlElement)o;//不是dom节点
System.out.println(element.getTextContent().trim());//得到文章内容 修剪空格
//如果不这样做,可能会得到一行 或者更多连同底下的猜您喜欢
}
}
}
}关键方法解释:
//div[@class=‘cont‘]/h1/text()"
表示div标签中属性“class"的值为”cont"的元素
其下面的标题h1内容
DomText为节点对象,(document object model)
asText() 获取文本内容
getTextContent() 获取正文内容**
- ansj_seg(分词库)分词小Demo
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.NlpAnalysis;
import java.util.List;
public class 分词Demo{
public static void main(String[] args) {
String sentence = "中华人民共和国成立了!中国人民从此站起来了!";
List<Term> termList = NlpAnalysis.parse(sentence).getTerms();
for (Term term : termList) {
System.out.println(term.getNatureStr() + ":" + term.getRealName());
}
}
}- SHA-256算法保证数据不会重复入库(sha-256小Demo)
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
public class 求SHA256Demo {
//MD5
//SHA-256
public static void main(String[] args) throws NoSuchAlgorithmException, UnsupportedEncodingException{
MessageDigest messageDigest=MessageDigest.getInstance("SHA-256");
//信息摘要 //实例
String s="你好世界";
byte [] bytes=s.getBytes("UTF-8");
messageDigest.update(bytes);//把要处理的字节传进去
byte[] result=messageDigest.digest();// 吸收 处理完后结果放在result
System.out.println(result.length);
for(byte b:result) {//打印信息摘要的每条信息
System.out.print(String.format("%02x", b));//右对齐 十六进制
}
System.out.println();
}
}
关键方法解释:
messageDigest.update(bytes);//把要处理的字节传进去
byte[] result=messageDigest.digest();// 计算处理完后结果放在result数据库表的设计:
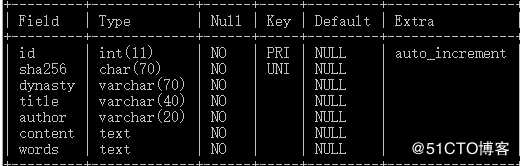
元素列举:
标题
朝代
作者
正文
分词
sha-256
最后加上一个自增主键**
三:正式开发代码:
1.单线程版本:
所有工作全部由主线程一个完成,执行效率最慢,但好处是无线程安全安全。
2.多线程版本:
爬取首页网站是主线程做,详情页的请求+解析,计算sha-256,分词,入库等交给工作线程做。大大提升了执行效率。
遇到的问题:
connection和webclient是线程不安全的,每个线程需要有自己的对象。
3.线程池版本:
Executors.newFixedThreadPool(30);//固定个数的线程池
一批处理30个,大概需要11批。
遇到的问题:
1.线程池中的线程是不会自己停止的?
我们需调用pool.shutdown()关闭线程
2.如何判断320首全部下载结束,继而调用pool.shutdown()关闭线程?
我们用到了countDownLatch类中的两个方法
CountDownLatch countDownLatch = new CountDownLatch(detailUrlList.size());//等到320首全部计数完成
1.await() // 当320没有减少到0师,一直阻塞在pool.shutdown()前。
2.countDown()//每当一个线程完成任务,数字减一。
声明:这次博客只完成了数据爬取并录入数据库过程。以上是关于项目:可视化分析(后端爬取数据部分)的主要内容,如果未能解决你的问题,请参考以下文章