GroupingComparator分组(辅助分组)
Posted si-137
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GroupingComparator分组(辅助分组)相关的知识,希望对你有一定的参考价值。
一、辅助排序:(GroupingComparator分组)
在Reduce端对key进行分组。应用于:在接受的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
二、举例说明
1、需求
(1)统计同一品牌下,卖最贵的手机型号
(2)希望输出信息(品牌名、手机型号名、价格)


1 xiaomi 小米10 1999 8 2020-07-10 2 huawei 华为P10 2999 7 2020-07-08 3 meizu 魅族E3660 1999 10 2020-07-09 4 xiaomi 小米9 1699 30 2020-07-09 5 xiaomi 小米8 1299 40 2020-07-11 6 xiaomi 小米10 1999 20 2020-07-12 7 xiaomi 小米9 1699 6 2020-07-13 8 meizu 魅族5300 2999 7 2020-07-14 9 meizu 魅族8 1899 8 2020-07-11 10 meizu 魅族e 1099 15 2020-07-06 11 huawei 华为P30 3999 18 2020-07-12 12 huawei 华为P20 2999 80 2020-07-01 13 huawei 华为P10 1999 60 2020-07-03 14 xiaomi 小米10 1999 8 2020-07-12 15 huawei 华为P10 2999 7 2020-07-18 16 meizu 魅族E3660 1999 40 2020-07-19 17 xiaomi 小米9 1699 30 2020-07-29 18 xiaomi 小米8 1299 41 2020-07-21 19 xiaomi 小米10 1999 70 2020-07-23 20 xiaomi 小米9 1699 6 2020-07-30 21 meizu 魅族5300 2999 7 2020-07-22 22 meizu 魅族8 1899 50 2020-07-16 23 meizu 魅族e 1099 55 2020-07-19 24 huawei 华为P30 3999 18 2020-07-25 25 huawei 华为P20 2999 80 2020-07-04 26 huawei 华为P10 1999 90 2020-07-03
2、PhoneBean.java
package com.jh.work02; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class PhoneBean implements WritableComparable<PhoneBean> { private String phoneName; // 手机品牌 private String phoneVersion; // 手机型号 private Long phoneMoney; // 手机单价 public PhoneBean() { super(); } @Override public String toString() { return phoneName + " " + phoneVersion + " " + phoneMoney; } public String getPhoneVersion() { return phoneVersion; } public void setPhoneVersion(String phoneVersion) { this.phoneVersion = phoneVersion; } public Long getPhoneMoney() { return phoneMoney; } public void setPhoneMoney(Long phoneMoney) { this.phoneMoney = phoneMoney; } public String getPhoneName() { return phoneName; } public void setPhoneName(String phoneName) { this.phoneName = phoneName; } // 序列化 @Override public void write(DataOutput out) throws IOException { out.writeUTF(phoneName); out.writeUTF(phoneVersion); out.writeLong(phoneMoney); } // 反序列化 @Override public void readFields(DataInput in) throws IOException { phoneName = in.readUTF(); phoneVersion = in.readUTF(); phoneMoney = in.readLong(); } // 排序 @Override public int compareTo(PhoneBean o) { /** * 说明: * compareTo方法被称为自然比较方法,利用当前对象和传入的目标对象进行比较; * 若是当前对象比目标对象大,则返回1,那么当前对象会排在目标对象的后面 * 若是当前对象比目标对象小,则返回-1,那么当前对象会排在目标对象的后面 * 若是两个对象相等,则返回0 */ // 先根据手机品牌排序,相同的挨着放 int result = this.getPhoneName().compareTo(o.getPhoneName()); if (result == 0){ // 手机品牌相同时,再根据手机单价倒序排序 return o.getPhoneMoney().compareTo(this.getPhoneMoney()); }else{ return result; } } }
3、PhoneMapper.java
package com.jh.work02; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class PhoneMapper extends Mapper<LongWritable,Text,PhoneBean,NullWritable> { private PhoneBean bean = new PhoneBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 获取文本每行内容 String line = value.toString(); // 根据分隔符切割 String[] split = line.split(" "); // 赋值 bean.setPhoneName(split[0]); bean.setPhoneVersion(split[1]); bean.setPhoneMoney(Long.parseLong(split[2])); context.write(bean,NullWritable.get()); } }
4、PhoneGroupCompartor.java
package com.jh.work02; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; public class PhoneGroupCompartor extends WritableComparator { /* 创建一个构造将比较对象的类传给父类,便于反序列化, 如果不提前声明空对象,在GroupingComparator调用时会抛出空指针异常 */ protected PhoneGroupCompartor() { super(PhoneBean.class,true); } @Override public int compare(WritableComparable a, WritableComparable b) { PhoneBean abean = (PhoneBean)a; PhoneBean bbean = (PhoneBean)b; // 根据手机品牌分组 return abean.getPhoneName().compareTo(bbean.getPhoneName()); } }
5、PhoneReducer.java
package com.jh.work02; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class PhoneReducer extends Reducer<PhoneBean,NullWritable,PhoneBean,NullWritable> { private PhoneBean bean = new PhoneBean(); @Override protected void reduce(PhoneBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { // 输出每组第一个,也就是最贵的的那个 context.write(key,values.iterator().next()); } }
6、PhoneDriverWork02.java
package com.jh.work02; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class PhoneDriverWork02 { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //1.获取job对象和配置文件对象 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); //2.添加jar的路径 job.setJarByClass(PhoneDriverWork02.class); //3.设置mapper类和reducer类 job.setMapperClass(PhoneMapper.class); job.setReducerClass(PhoneReducer.class); //4.设置mapper类输出的数据类型 job.setMapOutputKeyClass(PhoneBean.class); job.setMapOutputValueClass(NullWritable.class); //5.设置reducer类输出的数据类型 job.setOutputKeyClass(PhoneBean.class); job.setOutputValueClass(NullWritable.class); // 设置辅助分组的类 job.setGroupingComparatorClass(PhoneGroupCompartor.class); //设置文件的输入出路径 FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交任务 boolean result = job.waitForCompletion(true); //成功返回0,失败返回1 System.exit(result ? 0:1); } }
7、输出文件为
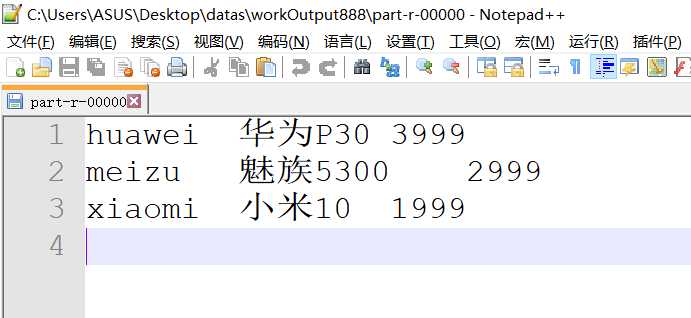
8、如果想统计同一品牌下,价格前两名的手机型号,只需修改PhoneReducer.java
package com.jh.work02; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class PhoneReducer extends Reducer<PhoneBean,NullWritable,PhoneBean,NullWritable> { private PhoneBean bean = new PhoneBean(); @Override protected void reduce(PhoneBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { // 输出每组第一个,也就是最贵的的那个 for (int i = 0; i < 2; i++) { if (values.iterator().hasNext()) { values.iterator().next(); context.write(key, NullWritable.get()); } } } }
以上是关于GroupingComparator分组(辅助分组)的主要内容,如果未能解决你的问题,请参考以下文章
大数据之Hadoop(MapReduce):GroupingComparator分组案例实操