定制语音代理(智能体)的背后是什么?
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了定制语音代理(智能体)的背后是什么?相关的知识,希望对你有一定的参考价值。
定制语音代理(智能体)的背后是什么?
What’s behind the move to custom voice agents?
自动化是未来的发展方向。生活在一个现在的时代,希望所有的事情都能迅速得到回答、实现和接受。尽管有了这种根本性的转变,许多人并不接受技术。对一些人来说,这与生活方式有关:大公司可能太笨重而无法改造系统,个人可能会被困在自己的方式中,不想学习如何使用触摸屏。然而,对大多数人来说,归根结底是数据——谁拥有以及如何保证安全。
解决方案?就像声音一样简单。语音支持技术可以解除对自动化的需求,同时保持数据的紧密性,这是每天都在使用的东西,无论地点或平台。随着数字转型对越来越多的应用程序产生影响,语音代理就是答案。除了像Alexa和Google voice这样家喻户晓的流行语音代理之外,更多的公司正在探索构建嵌入到这项技术中的定制语音平台。对于希望保留和控制自己数据的公司来说,独特的语音平台将是前进的方向。
Behind the disruption is automation
中断的背后是自动化
随着物联网(IoT)建立在人工智能(AI)之上,开始看到自动化需求的增长。当物联网与人工智能合作时,提高了用户对大量和广泛的互联网设备的控制能力。开始看到语音功能在家庭和其地方得到了扩展,通过谷歌语音、亚马逊Alexa、微软Cortana等平台或独特的平台进行交互。在Harman Embedded Audio,已经与世界上每一个语音引擎合作过,并且第一手了解了市场的广度。看到越来越多的公司希望在自己定制的语音助手平台上构建支持语音的产品,因此可以控制数据。
The demand for voice control is growing
对语音控制的需求正在增长
这是音频领域最热门的趋势之一。用户界面的下一件大事,现在触摸屏之类的功能几乎无处不在,就是能够与设备通话。声音正在引领下一代人类协作。想想计算机上的自然语言处理:语音的处理方式符合机器希望听到的声音,但如果播放相同的处理过的文件,将是机械的和不自然的。打电话也是一样:不会给人留下和某人在一个房间里的相同印象。这就是语音需要去的地方,上面提到的独特的语音平台也将随之出现。
What custom voice agents look like, and what’s involved in the build
自定义语音代理的外观,以及构建过程中涉及的内容
虽然每个语音解决方案都是不同的,但重要的是,所有解决方案都要足够灵活,以便在收集和保护用户数据的同时适应其用例的必要要求。要实现这一点,任何语音代理的构建和集成都涉及到三个主要元素。
第一种是远场算法。使用一个顶级算法来捕捉远场语音。在公司,使用了来自Sonique算法的四个关键软件算法:噪声抑制、噪声消除、声音分离和波束形成以及语音活动检测。这些算法是专门开发用于相互结合使用,以支持语音支持的应用程序。
是如何工作的?想想把一个聪明的演讲者和一个人类做比较。DSP/SOC充当扬声器的“大脑”,麦克风是耳朵,扬声器是嘴巴。对来说,当有人叫名字时,大脑会消除周围所有的噪音,把所有的能量都放在这个关键词上。这就是在智能扬声器中所取得的成就——当检测到关键词时,麦克风会使用不同的噪声抑制技术,并将所有的能量都投入到信号源上。在这个过程中,消除了周围的大部分噪音。在声学环境中,有许多噪声源,如环境噪声、本地扬声器、暖通空调等,这些噪声源将扬声器的反馈信号反馈到麦克风上。每一个噪声源都需要自己的解决方案。Sonique算法可以抑制噪音并捕捉到最好的清晰语音命令。
此外,建立一个关键字识别(KWS)引擎是至关重要的。KWS检测诸如“Alexa”或“OkGoogle”之类的关键字来开始对话。与几乎所有的KWS引擎供应商合作过,每一家都是由深度神经网络提供动力的——高度可定制、始终监听、轻量级和嵌入式。为了在远场语音应用中获得良好的客户体验,关键因素是错误接受率和错误拒绝率。在现实世界中,由于电视、家用电器、淋浴等外部噪声的存在,使得音频播放的取消效果不理想,因此要保持较低的误报率是非常困难的。经验丰富的开发人员调整KWS引擎以保持较低的错误接受率。 最后,自动语音识别(ASR)引擎将语音转换为文本。ASR由核心的语音到文本(STT)工具和自然语言理解(NLU)组成,后者将原始文本转换为数据。引擎还需要技能,或者换句话说,需要一个可以提供答案的知识库,以及反向的文本到语音工具。例如,已经开发了一个名为E-NOVA的ASR引擎,提供多平台、内部集成、支持多种语言(目前有七种语言正在增长),包括可训练模型、第三方集成支持和说话人识别。
ASR是语音技术的第一步,当提示“洛杉矶天气如何?”时,亚马逊Alexa、OK Google、Cortana或customer能够做出响应?“这是一个关键的部分,检测出说话的声音,将识别为单词,将与给定语言中的声音进行匹配,并最终识别出所说的单词。因为有了ASR引擎,谈话感觉很自然。而且,随着现代技术的发展,大多数ASR引擎都利用了云计算。随着诸如NLU这样的附加技术,人与计算机之间的对话变得更加智能和复杂。
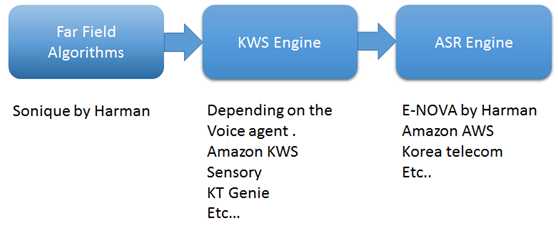
图1:语音代理中的基本处理管道。
然而,构建定制的语音代理有许多独特的挑战。理解产品的环境是这个过程的关键挑战之一,每个应用程序都会根据具体的用例而有所不同。例如,想象一下在家里做饭,手忙得满满的,当该烧开水的时候,只需要向连接到管道空间的语音代理快速请求:“把水烧到x度。”这里的挑战是设备是否能够听到说的话,以及设备将抵消多少噪音收到干净的信号,听到声音。为了确保这一点,需要将语音算法调整到恶劣的环境中,需要调整麦克风的位置以便能够拾取声音,并且应该使用低THD扬声器来帮助麦克风获得高信噪比。通过这个,将得到尽可能清晰的音频到ASR引擎,这将导致问题的正确答案。
此外,想象一下在游船上:周围的噪音和在客厅或厨房听到的完全不同。最大的挑战是训练算法来抑制这些噪声,并获得干净的音频信号给系统,以获得准确的响应。正确地实现,一个虚拟的个人巡航辅助系统(如为MSC Cruises开发的系统)可以可靠地完成图2中所示的步骤。
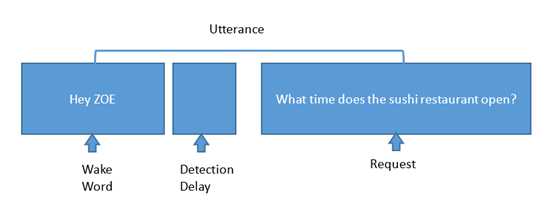
图2:典型的语音助手请求所涉及的步骤。
在这里,一个语音助理装置在乘客室检测到‘ Hey Zoe‘唤醒词。然后,当KWS检测到关键词时,整个麦克风基于噪声抑制算法,将能量转移到声源,并消除周围的噪声,如交流噪声、电视、不相关噪声、螺旋桨和发动机噪声、风噪声、AEC,Sonique算法被调整以消除所有这些噪声,并获得最干净的信号给系统。然后,当系统收到请求时,ASR引擎将此语音转换为文本。NLU引擎然后将此文本转换为原始数据以获得答案。但还没说完。为了得到想要的答案,knowledge skill提供了请求的答案,ASR引擎将数据文本转换为语音并通过扬声器输出。
另一个挑战是关于错误率拒绝(FRR)。唤醒字FRR是衡量智能扬声器性能的一个检查点,其实现过程既耗时又昂贵。该系统用于验证产品是否能在检测到唤醒字时正常唤醒。要实现FRR,必须训练关键词。根据经验,将经过训练的模型与顶层算法相结合可以让开发团队克服挑战并实现尽可能最好的FRR。在实验室中,在各种条件下进一步测试唤醒字响应,以确保系统通过行业标准。
The advantages of employing unique voice agents
使用独特的语音代理的优势
语音代理为用户体验提供了极大的价值。音乐是最大、最简单的用例,但语音代理的价值远不止远程打开Spotify帐户。声音可以打开东西,与电器互动,烧开水,打开水龙头等等!语音功能强大,而且代理对用户非常了解,这就是为什么公司希望获得自己的数据——拥有数据、存储数据和保护数据。
语音解决方案有着广泛的应用,但关键是要利用跨平台的技术——一种与苹果、Windows或android上的智能扬声器、笔记本电脑和智能手机相关的技术——并利用收集到的数据构建一个能够理解、不断学习和记住用户需求的代理。创建一个独特的语音代理可以实现这种使用的灵活性,同时保持数据的内部性。
以上是关于定制语音代理(智能体)的背后是什么?的主要内容,如果未能解决你的问题,请参考以下文章