致敬罗永浩:自然语言交互的背后是机器人大脑
Posted 中国指挥与控制学会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了致敬罗永浩:自然语言交互的背后是机器人大脑相关的知识,希望对你有一定的参考价值。
*此篇文章由氖星智能彭军辉供稿
本文来源:机器人大讲堂
昨天偶然看到一篇文章,盘点罗永浩先生这几年做过的产品,我才发现原来他竟然和我有着共同的梦想,那就是革新人机交互的方式,让人机自然语言交互成为主流。
在 2013 年的锤子Smartisan OS 发布会上,锤子做了一个语音助手的 Demo。后来成了锤子手机的语音搜索功能。
在2016 年的发布会上,锤子手机加入了科大讯飞的语音输入法,还同步发布了 One Step 和 Bigbang。“基于这三个工具,罗永浩表示,「希望用未来 6 到 12 个月的时间把在手机上用语音输入大量文字、再去做编辑处理的效果和效率,达到跟桌面电脑一样,甚至超过」。”
2018年 5 月份锤子在鸟巢的这场发布会上发布了年度最具争议产品 TNT,可以说是一个语音交互的个人电脑。
那么罗永浩先生搞不定的事情,我能搞定吗?
十多年前,我开始研究怎么让机器理解人类语言。我从汉语语法开始,探求语言的规律,期望把它变成机器可以理解的规则。我本身是学历史的,后来自学了编程。如今我们自然语言处理的算法都是我自己写的。
我们看罗永浩先生发布的产品,基本没有技术上的创新,只有功能上的创新。有人评论说罗永浩先生的产品只有语音,没有智能。
可以说罗永浩先生是个产品经理,我是个程序员。
那么自然语言交互的核心问题是什么呢?
肯定不是个产品问题,是个技术问题。
自然语言交互的特点是:不规范、不稳定、不完整。
你跟机器人说“前进”,机器人能识别成“天津”“强劲”“千金”。识别错了就不能正确处理了,这肯定是不行的。即便文字输入,也有不规范的。比如说“你吃饭了吗”,有人就会说“你饭吃了吗”“你把饭吃了吗”“你吃了吗”“吃饭了吗”“吃了吗”“饭吃啦吗”“饭吃啦吗你”“吃了吗你”“没吃吧”“吃没”等等。如果让人家只说“你吃饭了吗”就不是自然语言了,就是命令式处理了。
自然语言是不稳定的。同一句话,在不同情况下可能表达的意思是不一样的。比如“中国乒乓球谁也打不过。”这句是表扬中国乒乓球。可是过很多年后,也许中国乒乓球就是人见人欺了。这时我们还可以说这句话,语言没变,语义变了。有个小故事,一女生苦追班里一男神。有一天男神正在图书馆看书。女生突然表白。男神说,“我喜欢上一个人。”请问,这句话到底是什么意思?
通常我们说话时,为了节省时间未必要把话说完整,尤其是我们汉语。
比如,汉语通常说“是什么?”省略了主语。翻译成英语是“What’s this?”
汉语说“吃了吗?”翻译成英语是“Didyou have your meal? ”
汉语说“遇到陌生人,要离得远点。”翻译成英语是“When you meet strangers, stay away from them.”
其实交流是个过程,语言是一个整体。我们跟熟悉的人交流就比和陌生人顺畅。遇到陌生人,先要了解对方。这是顺畅交流的开始。一句话,只有把它和上下文以及对话的背景联系起来才能准确理解;甚至有时候我们还要考虑对方的情况。比如,跟一个中国说“神让我这样做的”,他会想到佛祖、菩萨或者土地爷爷、财神爷爷。跟一个西方人说这句话,他想得的可能是上帝或者宙斯。再如,跟一个人说“日本人把你家的地瓜分了。”是地瓜被分了还是土地被分了?如果对方是个饥饿的人,估计先想到的是地瓜;如果是其他人可能先想到的是土地。
不管是语音输入还是文字输入,都是自然语言输入。如果允许用户用自然语言输入,系统就必须面对自然语言存在的这些问题。
我们知道语音识别已经有很高的准确率了。但他们解决的问题只是把语音变成了文字。变成了文字不等于机器就能处理了。语音识别解决不了自然语言不规范、不稳定、不完整的问题。
自然语言交互还有很多障碍需要突破。

自然语言交互的核心问题是语义理解的问题,就是怎么通过用户的自然语言表达,理解用户的意图。这就需要机器人大脑。机器人大脑对自然语言输入的处理是个思辨的过程,只有这样才能准确理解用户意图。
什么是机器人大脑呢?
基本上可以把机器人大脑和操作系统当成一个层面的东西,它们都解决人机交互的问题。不同的是机器人大脑是人工智能,操作系统不是。
1.对用户自然语言输入,机器人大脑要经过思辨才能给出结果。这种结果指向并不是唯一的。而对于用户输入,操作系统的处理是条件反射,反馈结果是唯一的。
比如一个机器人正在往前走,同时还在播放音乐,这时用户说“停”,机器人就要根据上下文去决定是停止前进还是停止播放音乐。如果跟计算机说“停”,估计计算机会停止所有操作。
2.机器人大脑处理的是用户意图,不是用户输入。用户意图是形而上的,它通过语言文字表达,但不是语言文字本身。而操作系统处理的是语言文字本身。
比如你跟机器人说“前进”,语音识别结果是“天津”,机器人理解你的意图,依然执行前进的动作。如果给计算机输入“天津”,它会帮你查天津这个词条或者从地图上找到天津。
3.机器人大脑的系统结构是平行结构,而操作系统的系统结构是菜单结构。我们对平行结构的要求是想进入就进入、不想进入就不进入、想退出就退出、不想退出就不退出。
比如,我正在让机器人放音乐。这时我问北京天气,应该立即播报北京天气。但如果有一首歌曲的名称叫《北京天气》,这时应当播放这首歌。如果这时要进入天气预报功能,应当说别的比如“上海天气”“南京天气”等。不管说什么,只要用户意图表达是清晰的,都应该立即执行。
但在操作系统上做的机器人,各个功能彼此是独立的,本质上还是个树状结构。由于无法用语言去表现这个树状结构,于是用户没法理解这个结构。树状结构从一个功能到另一个功能之间的跳转要通过用户界面去完成。自然语言交互时并没有用户界面的。所以功能之间的跳转就变得无法把控。比如,在天气预报程序里,说“北京天气”设备会播报北京天气。但如果在音乐播放程序里,如果有首歌叫《北京天气》,很多厂商的设备就会播放北京天气预报。实际上用户的意图是播放《北京天气》这首歌。
只有使用机器人大脑才能处理好自然语言不规范、不稳定、不完整的问题。
那么机器人大脑是个产品吗?
如果泛泛地看,很可能把这个问题看成个产品问题。如果是个产品,罗永浩先生肯定能做好的。
很久以来都有人说我做的东西不过是关键字模糊查询。其实关键字模糊查询和语义理解相差甚远。用关键字模糊查询做语义理解,正确率能做到20%就不错了。这样的机器人基本上就是个智障。
机器人大脑的核心是语义理解,它是个技术门槛很高的事情,也是人工智能领域做得最差的。这个东西,连大公司都没做好,罗永浩们更不可能做好。我经常讲,做机器人大脑的难度和工程量不亚于登月工程。

我们提出了语义理解的四个标准:差异性、同一性、模糊性、一致性。
差异性就是理解句子之间的细微差异。比如“这是我”“这是我的”,差了个“的”语义不同。很多语义理解厂商是不处理“的地得”的。
同一性就是一个语义的不同表达。比如“你吃饭了吗”“饭你吃了吗”“吃了吗”等等,其实都是一个意思。
模糊性就是用户输入错误,或者语音识别错误,机器还能正确处理。就像刚才举的例子,把“前进”识别成“天津”机器人一样执行前进的动作。
一致性就是机器人说的话前后一致。不能先说“我是女孩子”后说“人家是个男的”。只有这样才是真正的语义理解。
以上四个标准都是技术标准,不是产品标准。我们就是照着这四个标准去不断完善我们技术的。
要满足以上四个标准是有相当难度的。
很多厂商用搜索技术做自然语言交互,根本满足不了以上标准。
搜索技术对自然语言的处理实质是对符号的处理,不是对语义的处理。自然语言交互需要问答技术。搜索和问答是完全不同的两个技术。这个我在别的文章里有比较详细的讲述,这里不再多讲。

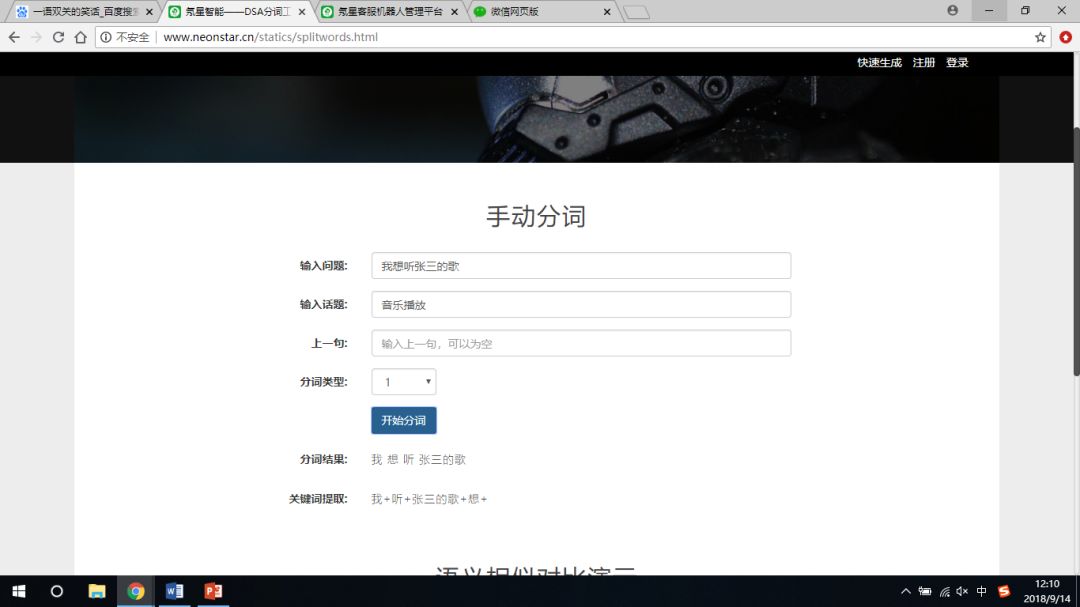
当我们深入做问答技术后才发现分词技术也是有问题的。市场上的分词技术都支持一个维度,对一句话只能分出一个结果。但自然语言交互需要根据上下文,根据对话场景对用户输入做不同分词。比如“日本人把你家的地瓜分了”分出来“地瓜”还是“瓜分”都是对的。但要分出来哪个就要根据上下文了。还有“我想听张三的歌”中“张三的歌”其实是一首歌的名字。传统的分词技术分不出来歌曲名称。于是我们自己研发了分词技术,为分词技术加入了上一句和话题两个维度。这样当话题是音乐播放时,“我想听张三的歌”分词结果就是“我/想/听/张三的歌”,其他情况就会分成“我/想/听/张三/的/歌”。
分词对语义理解的影响并不大,以至于被很多厂商忽略了。但我们依然自己做了分词。
我们用很多年完善了语义理解算法,才发现教机器人知识是个更大的坑。一个没有知识的机器人,就好比一个小孩子没受过教育一样。
如果仅仅用语音识别技术就能做好一个自然语言交互产品,科大讯飞可能更容易成功。如果罗永浩先生没有认识到自然语言交互需要一个机器人大脑,估计还需要走很长的弯路。我相信我们正走在正确的道路上,然而我也能看到这条道路的艰辛和漫长。好在经过十多年的反复探索,虽然屡战屡败,现在我们已经看到了希望。我们的氖星智能机器人大脑目前已经有了销售收入。
以上是关于致敬罗永浩:自然语言交互的背后是机器人大脑的主要内容,如果未能解决你的问题,请参考以下文章