查找:哈希表
Posted mary1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了查找:哈希表相关的知识,希望对你有一定的参考价值。
散列表(Hash),又名哈希,java中的HashMap,python中的dict,在一般代码中多用于键值对字典存储中。在查找中,哈希表的查找往往都是(Olog(1)),这说明哈希表的查找往往并不需要什么循环结构,是直接得出来的,那么其中必然有值和存储位置的对应计算方法,在哈希表中被叫做散列函数。有计算方法,就会出现结果的值相同的情况,对于计算结果相同的情况,哈希表也有处理这种冲突的方法。经过这俩步,就能建立键值对唯一的对应。
散列函数
留余数法,此方法使用最多,主要是它往往可以应用到其他方法中,并且它也非常的简单,只需要将值与选定值取余即可,假设选定值为(P),那么公式如下:
这里最主要的就是选定值(P)如何取值,一般而言,(P)的值接近或者等于散列表的表长。个人感觉最麻烦的地方就是开辟一块连续的空间,并且可能事先并不知道散列表表长到底是多大。
直接定址法,这也是很简单的方法,就是取线性函数的值作为散列地址,公式就是:
这个方法好处就是没有冲突,不用处理冲突了,但是线性函数计算的结果可能很大,这样不连续,就会造成空间的浪费,留下很多空位。
数字分析法,这就是分析输入的数,一般用于输入的数较长,比如身份证,那么可以分析身份证上的数字,使用其中的一段作为唯一的,比如身份证后六位。
折叠法,折叠就是将数字分成几部分,然后再将这几部分值进行相加。这个分成几部分之后,还可以进行其他的一些处理。
平方取中法,就是将关键字进行平方,之后取中间几位,不过个人感觉这个方法还是用于数字较多的情况下,并且到底取几位要根据情况确定。
值在经过上面的散列函数之后,计算出来的结果可能相同,这时候对于这种相同结果就要处理冲突。
处理冲突的方法
开放定址法,在发生冲突的时候,再找其他的位置来存下发生冲突的关键字,这种处理方式通常有好几种取法:
- 线性探测法,在发生冲突后,顺序查探下一个单元,直到找到一个空闲位置。这种方法缺点就是容易堆积在一起,大大降低了查询效率。
- 平方探测法,上面那个容易堆积在一起,因而在查找下一个位置的时候,使用平方查找位置,将数据分散,(1^2,-1^2,2^2,-2^2,dots ,k^2,-k^2),这样导致的问题就是不能探测到全部的位置。
- 再散列探测法,这个就是再来一个散列函数。当第一个发生冲突了,再利用第二个散列函数计算该关键字的位置。
拉链法,也叫链表法,就是将发生冲突的数据存储在同一个线性链表中,适合经常插入和删除的情况。个人感觉这种方法也很有效果
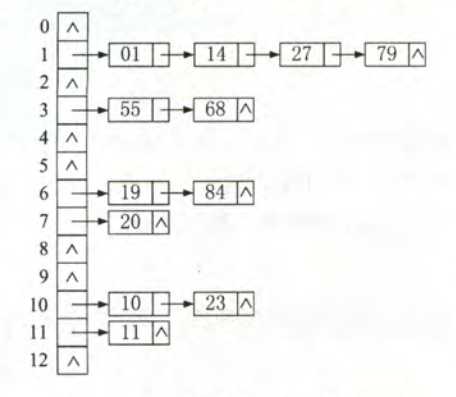
总结
书中说,哈希表的查找效率取决于三个方面:散列函数,处理冲突的方法和装填因子。其中装填因子就是哈希表中的数据多少,如果装的越多,那么就越容易发生冲突,反之发生冲突的概率就越小。但是以前我看很多分析哈希表都是直接得出来的。
哈希表不仅仅是用于存储数据中,更多的是用于其他领域中,比如密码学中,因为很多时候保存明文密码是不安全的,所以很多为了保护用户密码信息,都会保存密码的hash值。其中的方法有MD5,但是这样搞出来的hash值还是可以破解的,最简单的暴力破解。针对这种情况,采取的办法就是加盐salt,就是用特殊字符和用户输入的密码一起组成一个新的字符,但是如果salt被泄露了,那么就要修改全部的信息,针对这个问题,使用的是HMAC加密,加密使用的key是从服务器端获取的,每个用户都不一样。
哈希也可以用于数据检验中,比如git中的提交。每次提交都会有一个id,这个id就是SHA-1算法计算出来的,也可以用于负载均衡。
以前在学习爬虫的,为了标记已经爬过的网页,会使用到布隆过滤器,在数学之美这本书中介绍过这种方法,布隆过滤器也是哈希实现的。
以上是关于查找:哈希表的主要内容,如果未能解决你的问题,请参考以下文章