Notebook Docker 安装spark环境
Posted leechg
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Notebook Docker 安装spark环境相关的知识,希望对你有一定的参考价值。
环境
Notebook docker环境
https://registry.hub.docker.com/r/jupyter/datascience-notebook/
下载安装包
spark安装包
http://mirror.bit.edu.cn/apache/spark/spark-3.0.0/spark-3.0.0-bin-hadoop3.2.tgz
pyspark安装包
http://mirror.bit.edu.cn/apache/spark/spark-3.0.0/pyspark-3.0.0.tar.gz
Py4j安装包
下载0.10.9版本
JDK安装包
Jdk 1.8
安装
spark环境安装
解压spark-3.0.0-bin-hadoop3.2.tgz 至 /var/spark目录,配置docker环境变量
SPARK_HOME=/var/spark/spark-3.0.0-bin-hadoop3.2
Java 环境安装
解压jdk至/var/spark/jdk1.8.0_191
配置环境变量
JAVA_HOME=/var/spark/jdk1.8.0_191
PATH=%PATH%:/var/spark/jdk1.8.0_191/bin
Pyspark安装
解压pyspark-3.0.0 并跳转至pyspark-3.0.0目录,执行python setup.py install,执行安装,默认会自动安装py4j,如果自动安装失败,手动安装上一步下载的py4j安装包再次执行python setup.py install命令
测试
新建python文件
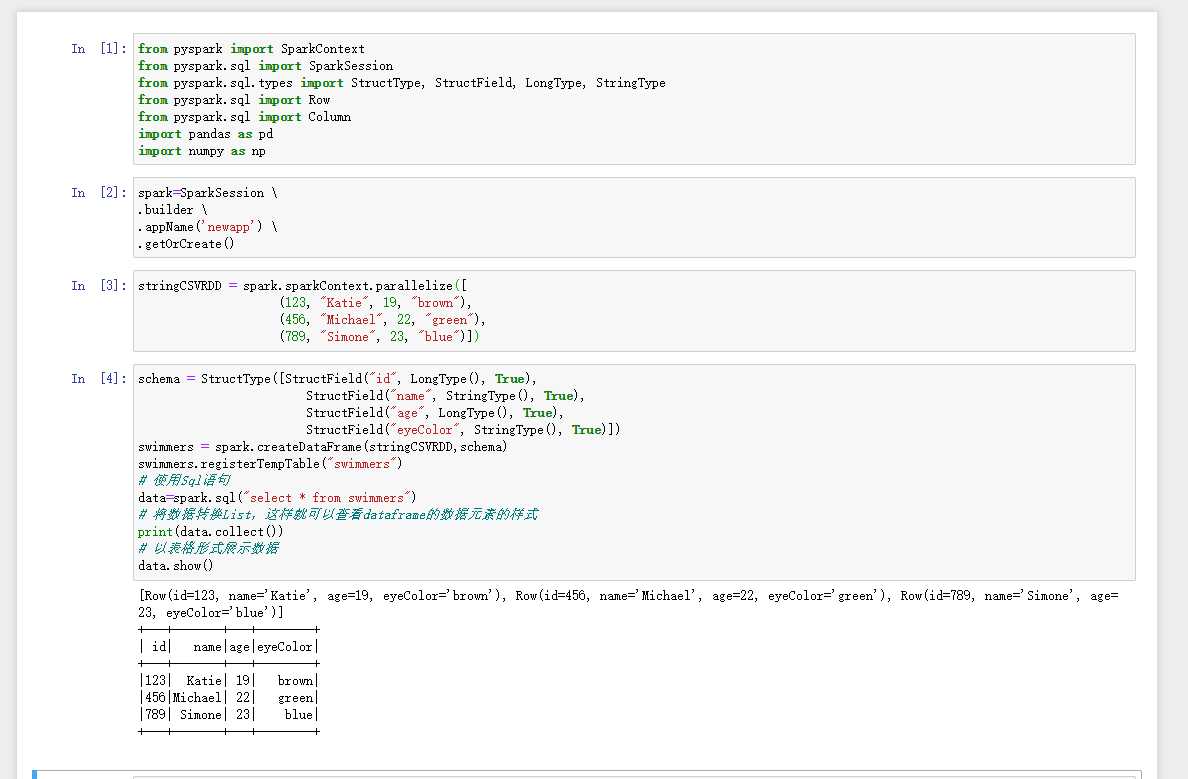
from pyspark import SparkContext from pyspark.sql import SparkSession from pyspark.sql.types import StructType, StructField, LongType, StringType from pyspark.sql import Row from pyspark.sql import Column import pandas as pd import numpy as np spark=SparkSession .builder .appName(‘newapp‘) .getOrCreate() stringCSVRDD = spark.sparkContext.parallelize([ (123, "Katie", 19, "brown"), (456, "Michael", 22, "green"), (789, "Simone", 23, "blue")]) schema = StructType([StructField("id", LongType(), True), StructField("name", StringType(), True), StructField("age", LongType(), True), StructField("eyeColor", StringType(), True)]) swimmers = spark.createDataFrame(stringCSVRDD,schema) swimmers.registerTempTable("swimmers") # 使用Sql语句 data=spark.sql("select * from swimmers") # 将数据转换List,这样就可以查看dataframe的数据元素的样式 print(data.collect()) # 以表格形式展示数据 data.show()
以上是关于Notebook Docker 安装spark环境的主要内容,如果未能解决你的问题,请参考以下文章
如何在windows下安装配置pyspark notebook
安装 Spark 问题。无法使用 pyspark 打开 IPython Notebook
利用docker搭建spark hadoop workbench
极智开发 | docker内安装jupyter notebook的正确姿势