如何在windows下安装配置pyspark notebook
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在windows下安装配置pyspark notebook相关的知识,希望对你有一定的参考价值。
参考技术A 首先你的spark环境已经安装好了。然后安装anaconda。
如果spark和anaconda都已经安装好了,直接添加环境变量。第一个变量是PYSPARK_DRIVER_PYTHON:jupyter。另外一个变量是PYSPARK_DRIVER_PYTHON_OPTS:notebook。这样从命令行启动的话(双击启动不行)就可以打开一个web服务在notebook中的py脚本就可以运行在spark上了本回答被提问者采纳
Win10下配置安装PySpark和Hadoop环境
Win10下配置PySpark环境
一、下载和安装Python和JAVA
- 下载JDK8:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html(注:Hadoop只支持JDK8或者JDK11)
- 安装JDK到默认路径。
设置JAVA_HOME=%JAVA_HOME%为C:\\PROGRA~1\\Java\\jdk1.8.0_261(重要!!!)如果填写C:\\Program Files\\Java\\jdk1.8.0_261的话,会出现ERROR namenode.NameNode: Failed to start namenode.java.lang.UnsupportedOperationException的错误![^6]
设置环境变量JAVA_TOOL_OPTIONS为-Duser.language=en。(如果你喜欢JDK输出中文的话,这里可以不设置。但是在第六步得修改JVM参数。) - 下载Python3.9:https://www.python.org/downloads/
二、安装和配置Hadoop1
-
从清华镜像网站下载:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/。下载稳定版:hadoop-3.2.1.tar.gz.
-
下载winutils。Hadoop在windows上不能直接运行,需要下载winutils。下载地址下载地址:https://github.com/Zer0r3/winutils。
-
解压hadoop。找到winutils对应hadoop的版本号,解压winutils并安装到hadoop\\bin文件夹下注意winutils的版本号要和Hadoop对应,否则会出现
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0的错误!2。 -
配置hadoop。
新建环境变量HADOOP_HOME ,值为hadoop的安装目录:如D:\\hadoop-3.2.1
编辑path环境变量,新增:
%HADOOP_HOME%\\bin
%HADOOP_HOME%\\sbin -
配置hadoop启动脚本
修改
etc\\hadoop\\core-site.xml,添加本机域名默认节点:<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:8900</value> </property> <property> <name>hadoop.tmp.dir</name> <value>D:/hadoop-3.2.1/tmp/${user.name}</value> <description>A base for other temporary directories.</description> </property> </configuration> -
修改
etc\\hadoop\\mapred-site.xml。 添加一组property,设置yarn:<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
修改
etc\\hadoop\\hdfs-site.xml:<configuration> <!-- 这个参数设置为1,因为是单机版hadoop --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/D:/hadoop-3.2.1/data/namenode</value> </property> <property> <name>fs.checkpoint.dir</name> <value>/D:/hadoop-3.2.1/data/snn</value> </property> <property> <name>fs.checkpoint.edits.dir</name> <value>/D:/hadoop-3.2.1/data/snn</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/D:/hadoop-3.2.1/data/datanode</value> </property> </configuration> -
修改
etc\\hadoop\\yarn-site.xml配置:<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
三、Yarn配置(如果你电脑安装yarn的NPM包管理的情况下)3
调整PATH环境变量,使得Hadoop的位置在于nodejs的前面。比如:
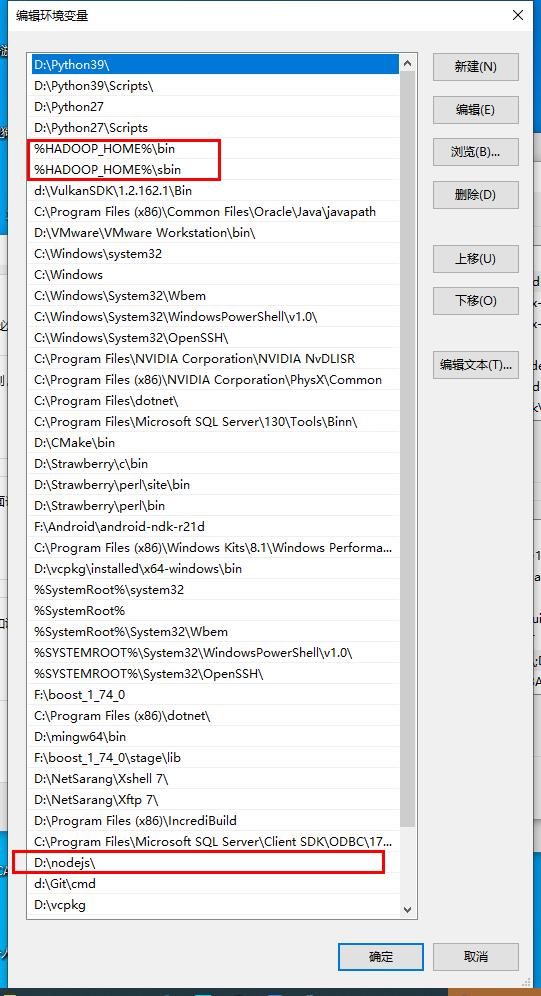
如果没有配置的话,接下去运行就会出现error Couldn't find a package.json file in "d:\\hadoop-3.2.1\\sbin"的字眼。
四、安装PySpark
不需要事先安装Spark,直接安装PySpark即可。
输入命令安装PySpark
pip3 install -i https://mirrors.ustc.edu.cn/pypi/web/simple/ pyspark
输入命令查看PySpark是否安装成功。
pyspark --version
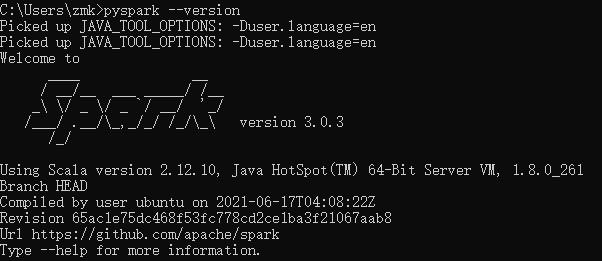
如果显示内容为以上信息的话,表示安装成功!
五、启动Hadoop1
- 右键CMD,以管理员身份运行(不知道这部必不必要)
- 格式化系统文件,输入命令:
hdfs namenode -format - 启动:
start-all
运行完毕后,可以看到运行了四个服务:- Hadoop Namenode(文件系统目录,类似于书的目录部分)
- Hadoop datanode(数据文件内容,就是书的正文)
- YARN Resourc Manager(统一节点管理、调度者)
- YARN Node Manager (各个子节点)
- 可以访问Hadoop集群页面:http://127.0.0.1:8088。
访问hadoop文件管理页面:http://localhost:9870
六、配置PyCharm(如果不用可以跳过)
-
打开pycharm的安装目录,打开
pycharm64.exe.vmoptions文件,找到-Xms128m -Xmx512m修改为4
-Xms256m -Xmx1024m -
如果之前未把JDK输出的语言改为英文的话,在
pycharm64.exe.vmoptions文件尾添加一下内容:5-Dfile.encoding=UTF-8 -
如果你的电脑里面安装了多个Python的时候,在
PyCharm运行的时候,需要指定具体的Python6:- 打开项目
- 点击运行旁边的小箭头,编辑运行和调试配置选项。
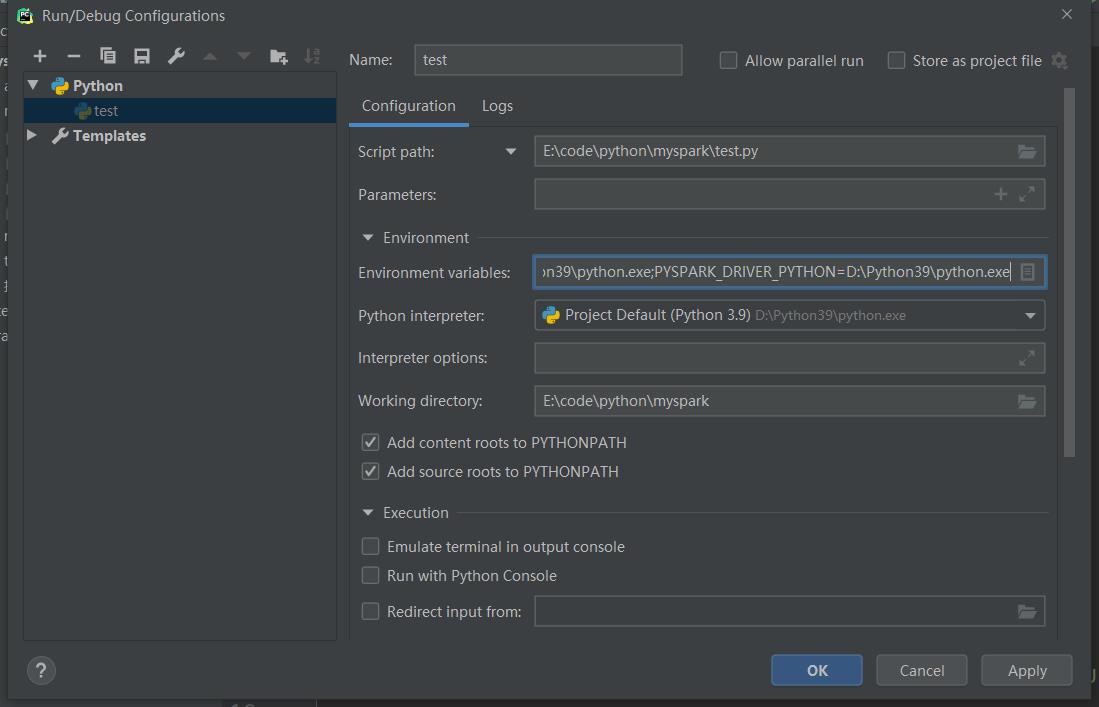
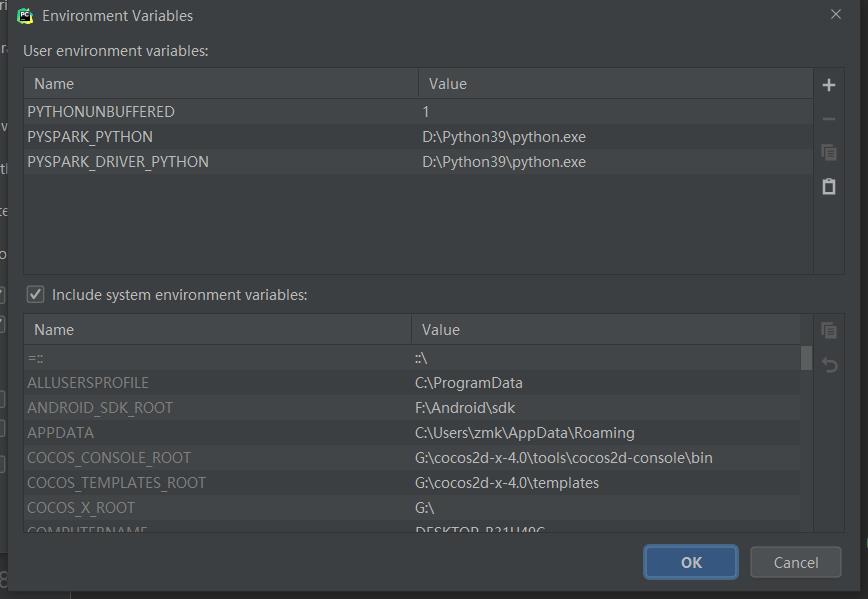
- 点击环境变量,设置
PYSPARK_PYTHON和PYSPARK_DRIVER_PYTHON为你的Python路径。
七、运行和享受
完毕,运行和享受你的项目。
win10下安装hadoop3.3.0 - 知乎 https://zhuanlan.zhihu.com/p/375066643 ↩︎ ↩︎
java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z - 江湖小小白 - 博客园 https://www.cnblogs.com/jhxxb/p/10723369.html ↩︎
hdfs - Unable to run yarn during hadoop installation - Stack Overflow https://stackoverflow.com/questions/51574920/unable-to-run-yarn-during-hadoop-installation ↩︎
ERROR Utils: Uncaught exception in thread stdout writer for python - 亢奋的小马哥 - 博客园 https://www.cnblogs.com/xiaoma0529/p/7250187.html ↩︎
【已解决】解决IntelliJ IDEA控制台输出中文乱码问题 - 知乎 https://zhuanlan.zhihu.com/p/94412052
[^6 ]: java - Failed to start NameNode - Stack Overflow https://stackoverflow.com/questions/58461455/failed-to-start-namenode ↩︎python - environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON - Stack Overflow https://stackoverflow.com/questions/48260412/environment-variables-pyspark-python-and-pyspark-driver-python ↩︎
以上是关于如何在windows下安装配置pyspark notebook的主要内容,如果未能解决你的问题,请参考以下文章
ModuleNotFoundError: No module named 'pyspark' 解决方案