模型加速知识蒸馏
Posted monologuesmw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型加速知识蒸馏相关的知识,希望对你有一定的参考价值。
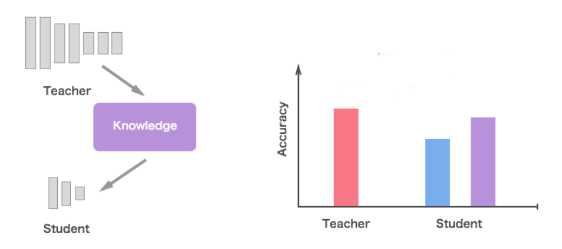
知识蒸馏的思想最早是由Hinton大神在15年提出的一个黑科技,Hinton在一些报告中将该技术称之为Dark Knowledge,技术上一般叫做知识蒸馏(Knowledge Distillation),是模型加速中的一种重要的手段。
现状
深度学习经过多年的发展,已经建立了多种能够执行复杂任务的复杂模型,然而面临的问题是,如何将庞大的模型部署在移动设备上,从而便于即时的使用推广。当然,可以将模型部署到云上,并可以在需要它的服务时调用它,但这需要可靠的互联网连接,这无疑在部署中添加了一道屏障。因此,需要的是一个可以在移动设备上运行的模型。
当然,也可以训练一个在移动设备有限资源上可以运行的小型网络。但是这种方法有一个问题,小型模型无法提取出生成预测的复杂特征,在复杂的外界条件中,精度往往不能满足需求。至少目前还没有某种小型算法可以满足实际的要求,即使yolov3 v4的tiny版,由于网络层数较浅,在实际检测中也会常常出现不稳定的现象。虽然小型模型的集成可以得到很好的结果,但使用整个模型集成进行预测是很麻烦的,而且可能会在计算上过于昂贵,不能允许部署到大量用户。
在这种情况下,通常使用两种技术手段包含:
- 知识蒸馏
- 模型压缩
知识蒸馏
知识蒸馏是提高移动设备深度学习模型性能的一种简单方法,被广泛应用于模型加速。而与模型剪枝不同的是,该项技术并不是通过对原有模型进行某种更改,而是通过原有模型训练一个小模型,使小模型的表现趋近于原有模型。
在这个过程中,通过训练一个庞大而复杂的网络或集成模型,之后,利用训练好的模型从给定的数据中提取重要的特征 产生好的预测(可以接受的)。利用这个复杂的模型训练一个小模型,使这个小模型将能够产生比较好的结果,甚至能够复制复杂网络的结果。
核心思想
知识蒸馏通过知识迁移的方式,将训练好的大模型作为teacher model,通过teacher model训练小模型(Student model)。也就是说,损失函数的构成包含两部分,其一,是熟知将真实标签(hard label)与预测值之间的损失,其二,则是teacher model的输出(soft label)与预测值之间的损失。通过这种方式,让小模型的精度趋近于大模型的精度。
那为什么在hard label的基础上还需要添加soft label呢?也就是说,损失函数在已经有了正确的hard label作指引的条件下,为什么还需要添加soft label的指引?
其实,hard label携带的信息量很低,它只能给予模型是或不是的指引。例如,在猫狗分类中,hard label只能告诉模型它是猫不是狗,或者是狗不是猫。而soft label中会传授诸如不同类别之间的相似度的信息。例如,一辆轿车被误分为卡车的可能性很小,但这个可能性要比误分为一只猫的可能性高很多,形成的soft label更有可能是[0.7, 0.29, 0.01]的形式。这更加有利于模型区分相似物体。当然,如果要区分的物体都是比较容易区分的,即产生[0.98, 0.01, 0.01]这样的soft label与hard label就几乎一致了。
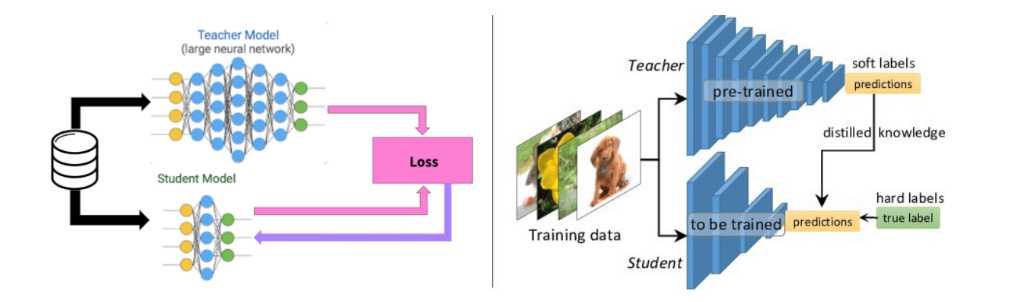
细节补充
通过上述描述,可以理解Teacher Model与Student Model之间建立关联是通过Loss,Teacher Model提供一个Soft label q与Student Model产生的预测p建立一个Loss CE(p, q),Student Model的预测p与真实值y建立一个Loss CE(p, y),因此,最终损失函数可以组合写成:
L = CE(p, y) + αCE(p, q)
其中,CE表示交叉损失熵(Cross Entropy)。
这里的q是teacher model的输出,也是student model的学习对象,对应于下式的P。
下式的qt表示teacher model logit的输出,然而,将qt代入softmax函数中,可能不太合适,出现下面对T讨论的情况。我们希望P可以具有传递相似信息的功能,因此,在softmax函数中增添了温度T参数。
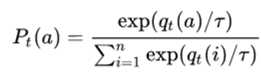
对T的讨论:
- 当T -> inf时, 所有的类别会获得相同的概率,就是一个均匀分布;
- 当T ->0时,则最大值会接近于1,其他值会趋近于0,近似于one hot编码(hard label);
- 当T ->1时,就是softmax公式本身。
以上是关于模型加速知识蒸馏的主要内容,如果未能解决你的问题,请参考以下文章
加速100倍,性能媲美SOTA,浙大提出无数据知识蒸馏新方法FastDFKD